Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi klrd takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
Pedestrian tracking with crowd simulation models in a multi-camera system
.png) In this paper, a multi-camera tracking system with integrated crowd simulation is proposed in order to explore the possibility to make homography information more helpful. Two crowd simulators with different simulation strategies are used to investigate the influence of the simulation strategy on the final tracking performance. The performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) metrics, for all the camera views and the results obtained under real-world coordinates. The experimental results demonstrate that crowd simulators boost the tracking performance significantly, especially for crowded scenes with higher density.
In this paper, a multi-camera tracking system with integrated crowd simulation is proposed in order to explore the possibility to make homography information more helpful. Two crowd simulators with different simulation strategies are used to investigate the influence of the simulation strategy on the final tracking performance. The performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) metrics, for all the camera views and the results obtained under real-world coordinates. The experimental results demonstrate that crowd simulators boost the tracking performance significantly, especially for crowded scenes with higher density.
Novel Representation for Driver Emotion Recognition in Motor Vehicle Videos
.png) A novel feature representation of human facial expressions for emotion recognition is developed. The representation leveraged the background texture removal ability of Anisotropic Inhibited Gabor Filtering (AIGF) with the compact representation of spatiotemporal local binary patterns. The emotion recognition system incorporated face detection and registration followed by the proposed feature representation: Local Anisotropic Inhibited Binary Patterns in Three Orthogonal Planes (LAIBP-TOP) and classification. The system is evaluated on videos from Motor Trend Magazine’s Best Driver Car of the Year 2014-2016. The results showed improved performance compared to other state-of-the-art feature representations.
A novel feature representation of human facial expressions for emotion recognition is developed. The representation leveraged the background texture removal ability of Anisotropic Inhibited Gabor Filtering (AIGF) with the compact representation of spatiotemporal local binary patterns. The emotion recognition system incorporated face detection and registration followed by the proposed feature representation: Local Anisotropic Inhibited Binary Patterns in Three Orthogonal Planes (LAIBP-TOP) and classification. The system is evaluated on videos from Motor Trend Magazine’s Best Driver Car of the Year 2014-2016. The results showed improved performance compared to other state-of-the-art feature representations.
EDeN: Ensemble of deep networks for vehicle classification
.png) Traffic surveillance has always been a challenging task to automate. The main difficulties arise from the high variation of the vehicles appertaining to the same category, low resolution, changes in illumination and occlusions. Due to the lack of large labeled datasets, deep learning techniques still have not shown their full potential. In this paper, thanks to the MIOvision Traffic Camera Dataset (MIO-TCD), an Ensemble of Deep Networks (EDeN) is used to successfully classify surveillance images into eleven different classes of vehicles. The ensemble of deep networks consists of 2 individual networks that are trained independently. Experimental results show that the ensemble of networks gives better performance compared to individual networks and it is robust to noise. The ensemble of networks achieves an accuracy of 97.80%, mean precision of 94.39%, mean recall of 91.90% and Cohen kappa of 96.58.
Traffic surveillance has always been a challenging task to automate. The main difficulties arise from the high variation of the vehicles appertaining to the same category, low resolution, changes in illumination and occlusions. Due to the lack of large labeled datasets, deep learning techniques still have not shown their full potential. In this paper, thanks to the MIOvision Traffic Camera Dataset (MIO-TCD), an Ensemble of Deep Networks (EDeN) is used to successfully classify surveillance images into eleven different classes of vehicles. The ensemble of deep networks consists of 2 individual networks that are trained independently. Experimental results show that the ensemble of networks gives better performance compared to individual networks and it is robust to noise. The ensemble of networks achieves an accuracy of 97.80%, mean precision of 94.39%, mean recall of 91.90% and Cohen kappa of 96.58.
Robust visual rear ground clearance estimation and classification of a passenger vehicle
 Computation of Visual Rear Ground Clearance of vehicles was an important computer vision application. This problem was challenging as the road and vehicle rear bumper may have subtle appearance differences, vehicle motion was on uneven surfaces and there were real-time considerations. A method is presented to compute the Visual Rear Ground Clearance of a vehicle from its rear view video and classify it into two classes; namely Low Visual Rear Ground Clearance Vehicles and High Visual Rear Ground Clearance Vehicles. A multi-frame matching technique in conjunction with geometry based constraints was developed. It detected Regions-of-Interest ROIs of moving vehicles and moving shadows, and used shape constraints associated with vehicle geometry as viewed from its rear. It tracked stable features on a vehicle to compute the Visual Rear Ground Clearance.
Computation of Visual Rear Ground Clearance of vehicles was an important computer vision application. This problem was challenging as the road and vehicle rear bumper may have subtle appearance differences, vehicle motion was on uneven surfaces and there were real-time considerations. A method is presented to compute the Visual Rear Ground Clearance of a vehicle from its rear view video and classify it into two classes; namely Low Visual Rear Ground Clearance Vehicles and High Visual Rear Ground Clearance Vehicles. A multi-frame matching technique in conjunction with geometry based constraints was developed. It detected Regions-of-Interest ROIs of moving vehicles and moving shadows, and used shape constraints associated with vehicle geometry as viewed from its rear. It tracked stable features on a vehicle to compute the Visual Rear Ground Clearance.
Multi-camera pedestrian tracking using group structure
.png) In this paper, we propose a novel multi-camera pedestrian tracking system, which incorporates a pedestrian grouping strategy and an online cross-camera model. The new cross-camera model is able to take the advantage of the information from all camera views as well as the group structure in the inference stage, and can be updated based on the learning approach from structured SVM. The experimental results demonstrate the improvement in tracking performance when grouping stage is integrated.
In this paper, we propose a novel multi-camera pedestrian tracking system, which incorporates a pedestrian grouping strategy and an online cross-camera model. The new cross-camera model is able to take the advantage of the information from all camera views as well as the group structure in the inference stage, and can be updated based on the learning approach from structured SVM. The experimental results demonstrate the improvement in tracking performance when grouping stage is integrated.
Efficient alignment for vehicle make and model recognition
.png) This paper presents a make and model recognition system for passenger vehicles. We propose a two-step efficient alignment mechanism to account for view point changes. The 2D alignment problem is solved as two separate one dimensional shortest path problems. To avoid the alignment of the query with the entire database, reference views are used. These views are generated iteratively from the database. To improve the alignment performance further, use of two references is proposed: a universal view and type specific showcase views. The query is aligned with universal view first and compared with the database to find the type of the query. Then the query is aligned with type specific showcase view and compared with the database to achieve the final make and model recognition. We report results on database of 1500 vehicles with more than 250 makes and models.
This paper presents a make and model recognition system for passenger vehicles. We propose a two-step efficient alignment mechanism to account for view point changes. The 2D alignment problem is solved as two separate one dimensional shortest path problems. To avoid the alignment of the query with the entire database, reference views are used. These views are generated iteratively from the database. To improve the alignment performance further, use of two references is proposed: a universal view and type specific showcase views. The query is aligned with universal view first and compared with the database to find the type of the query. Then the query is aligned with type specific showcase view and compared with the database to achieve the final make and model recognition. We report results on database of 1500 vehicles with more than 250 makes and models.
Soft biometrics integrated multi-target tracking
.png) In this paper, we present a soft biometrics based appearance model for multi-target tracking in a single camera. Tracklets, the short-term tracking results, are generated by linking detections in consecutive frames based on conservative constraints. Our goal is to “re-stitching” the adjacent tracklets that contain the same target so that robust long-term tracking results can be achieved. As the appearance of the same target may change greatly due to heavy occlusion, pose variations and changing lighting conditions, a discriminative appearance model is crucial for association-based tracking. Unlike most previous methods which simply use the similarity of color histograms or other low level features to construct the appearance model, we propose to use the fusion of soft biometrics generated from sub-tracklets to learn a discriminative appearance model in an online manner. Compared to low level features, soft biometrics are robust against appearance variation. The experimental results demonstrate that our method is robust and greatly improves the tracking performance over the state-of-the-art method.
In this paper, we present a soft biometrics based appearance model for multi-target tracking in a single camera. Tracklets, the short-term tracking results, are generated by linking detections in consecutive frames based on conservative constraints. Our goal is to “re-stitching” the adjacent tracklets that contain the same target so that robust long-term tracking results can be achieved. As the appearance of the same target may change greatly due to heavy occlusion, pose variations and changing lighting conditions, a discriminative appearance model is crucial for association-based tracking. Unlike most previous methods which simply use the similarity of color histograms or other low level features to construct the appearance model, we propose to use the fusion of soft biometrics generated from sub-tracklets to learn a discriminative appearance model in an online manner. Compared to low level features, soft biometrics are robust against appearance variation. The experimental results demonstrate that our method is robust and greatly improves the tracking performance over the state-of-the-art method.
An online learned elementary grouping model for multi-target tracking
.png) We introduce an online approach to learn possible elementary for inferring high level context that can be used to improve multi-target tracking in a data-association based framework. Unlike most existing association-based tracking approaches that use only low level information to build the affinity model and consider each target as an independent agent, we online learn social grouping behavior to provide additional information for producing more robust tracklets affinities. Social grouping behavior of pairwise targets is first learned from confident tracklets and encoded in a disjoint grouping graph. The grouping graph is further completed with the help of group tracking. The proposed method is efficient, handles group merge and split, and can be easily integrated into any basic affinity model. We evaluate our approach on two public datasets, and show significant improvements compared with state-of-the-art methods.
We introduce an online approach to learn possible elementary for inferring high level context that can be used to improve multi-target tracking in a data-association based framework. Unlike most existing association-based tracking approaches that use only low level information to build the affinity model and consider each target as an independent agent, we online learn social grouping behavior to provide additional information for producing more robust tracklets affinities. Social grouping behavior of pairwise targets is first learned from confident tracklets and encoded in a disjoint grouping graph. The grouping graph is further completed with the help of group tracking. The proposed method is efficient, handles group merge and split, and can be easily integrated into any basic affinity model. We evaluate our approach on two public datasets, and show significant improvements compared with state-of-the-art methods.
Three-Dimensional Vehicle Model Building From Video
 Traffic videos often capture slowly changing views of moving vehicles.
We instead focus on 3-D model building vehicles with different shapes from a
generic 3-D vehicle model by accumulating evidences in streaming traffic videos collected
from a single camera. We propose a novel Bayesian graphical model (BGM), which is called
structure-modifiable adaptive reason-building temporal Bayesian graph (SmartBG), that models
uncertainty propagation in 3-D vehicle model building. Uncertainties are used as relative weights
to fuse evidences and to compute the overall reliability of the generated models.
Results from several traffic videos and two different view points demonstrate the performance of the method.
Traffic videos often capture slowly changing views of moving vehicles.
We instead focus on 3-D model building vehicles with different shapes from a
generic 3-D vehicle model by accumulating evidences in streaming traffic videos collected
from a single camera. We propose a novel Bayesian graphical model (BGM), which is called
structure-modifiable adaptive reason-building temporal Bayesian graph (SmartBG), that models
uncertainty propagation in 3-D vehicle model building. Uncertainties are used as relative weights
to fuse evidences and to compute the overall reliability of the generated models.
Results from several traffic videos and two different view points demonstrate the performance of the method.
Structural Signatures for Passenger Vehicle Classification in Video
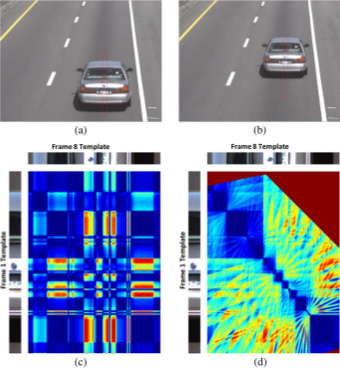 This research focuses on a challenging pattern recognition problem of significant industrial impact,
i.e., classifying vehicles from their rear videos as observed by a camera mounted on top of a highway
with vehicles travelling at high speed. To solve this problem, we present a novel feature called
structural signature. From a rear-view video, a structural signature recovers the vehicle side
profile information, which is crucial in its classification. We present a complete system
that computes structural
signatures and uses them for classification of passenger vehicles into sedans, pickups,
and minivans/sport utility vehicles in highway videos.
This research focuses on a challenging pattern recognition problem of significant industrial impact,
i.e., classifying vehicles from their rear videos as observed by a camera mounted on top of a highway
with vehicles travelling at high speed. To solve this problem, we present a novel feature called
structural signature. From a rear-view video, a structural signature recovers the vehicle side
profile information, which is crucial in its classification. We present a complete system
that computes structural
signatures and uses them for classification of passenger vehicles into sedans, pickups,
and minivans/sport utility vehicles in highway videos.
Context-aware reinforcement learning for re-identification in a video network
.png) Re-identification of people in a large camera network has gained popularity in recent years. The problem still remains challenging due to variations across cameras. A variety of techniques which concentrate on either features or matching have been proposed. Similar to majority of computer vision approaches, these techniques use fixed features and/or parameters. As the operating conditions of a vision system change, its performance deteriorates as fixed features and/or parameters are no longer suited for the new conditions. We propose to use context-aware reinforcement learning to handle this challenge. We capture the changing operating conditions through context and learn mapping between context and feature weights to improve the re-identification accuracy. The results are shown using videos from a camera network that consists of eight cameras.
Re-identification of people in a large camera network has gained popularity in recent years. The problem still remains challenging due to variations across cameras. A variety of techniques which concentrate on either features or matching have been proposed. Similar to majority of computer vision approaches, these techniques use fixed features and/or parameters. As the operating conditions of a vision system change, its performance deteriorates as fixed features and/or parameters are no longer suited for the new conditions. We propose to use context-aware reinforcement learning to handle this challenge. We capture the changing operating conditions through context and learn mapping between context and feature weights to improve the re-identification accuracy. The results are shown using videos from a camera network that consists of eight cameras.
Improving person re-identification by soft biometrics based re-ranking
.png) The problem of person re-identification is to recognize a target subject across non-overlapping distributed cameras at different times and locations. In a real-world scenario, person re-identification is challenging due to the dramatic changes in a subject’s appearance in terms of pose, illumination, background, and occlusion. Existing approaches either try to design robust features to identify a subject across different views or learn distance metrics to maximize the similarity between different views of the same person and minimize the similarity between different views of different persons. In this paper, we aim at improving the reidentification performance by reranking the returned results based on soft biometric attributes, such as gender, which can describe probe and gallery subjects at a higher level. During reranking, the soft biometric attributes are detected and attribute-based distance scores are calculated between pairs of images by using a regression model. These distance scores are used for reranking the initially returned matches. Experiments on a benchmark database with different baseline re-identification methods show that reranking improves the recognition accuracy by moving upwards the returned matches from gallery that share the same soft biometric attributes as the probe subject.
The problem of person re-identification is to recognize a target subject across non-overlapping distributed cameras at different times and locations. In a real-world scenario, person re-identification is challenging due to the dramatic changes in a subject’s appearance in terms of pose, illumination, background, and occlusion. Existing approaches either try to design robust features to identify a subject across different views or learn distance metrics to maximize the similarity between different views of the same person and minimize the similarity between different views of different persons. In this paper, we aim at improving the reidentification performance by reranking the returned results based on soft biometric attributes, such as gender, which can describe probe and gallery subjects at a higher level. During reranking, the soft biometric attributes are detected and attribute-based distance scores are calculated between pairs of images by using a regression model. These distance scores are used for reranking the initially returned matches. Experiments on a benchmark database with different baseline re-identification methods show that reranking improves the recognition accuracy by moving upwards the returned matches from gallery that share the same soft biometric attributes as the probe subject.
Reference set based appearance model for tracking across non-overlapping cameras
.png) Multi-target tracking in non-overlapping cameras is challenging due to the vast appearance change of the targets across camera views caused by variations in illumination conditions, poses, and camera imaging characteristics. Therefore, direct track association is difficult and prone to error. In this paper, we propose a novel reference set based appearance model to improve multi-target tracking in a network of nonoverlapping video cameras. Unlike previous work, a reference set is constructed for a pair of cameras, containing targets appearing in both camera views. For track association, instead of comparing the appearance of two targets in different camera views directly, they are compared to the reference set. The reference set acts as a basis to represent a target by measuring the similarity between the target and each of the individuals in the reference set. The effectiveness of the proposed method over the baseline models on challenging realworld multi-camera video data is validated by the experiments.
Multi-target tracking in non-overlapping cameras is challenging due to the vast appearance change of the targets across camera views caused by variations in illumination conditions, poses, and camera imaging characteristics. Therefore, direct track association is difficult and prone to error. In this paper, we propose a novel reference set based appearance model to improve multi-target tracking in a network of nonoverlapping video cameras. Unlike previous work, a reference set is constructed for a pair of cameras, containing targets appearing in both camera views. For track association, instead of comparing the appearance of two targets in different camera views directly, they are compared to the reference set. The reference set acts as a basis to represent a target by measuring the similarity between the target and each of the individuals in the reference set. The effectiveness of the proposed method over the baseline models on challenging realworld multi-camera video data is validated by the experiments.
Single camera multi-person tracking based on crowd simulation
.png) Tracking individuals in video sequences, especially in crowded scenes, is still a challenging research topic in the area of pattern recognition and computer vision. However, current single camera tracking approaches are mostly based on visual features only. The novelty of the approach proposed in this paper is the integration of evidences from a crowd simulation algorithm into a pure vision based method. Based on a stateof-the-art tracking-by-detection method, the integration is achieved by evaluating particle weights with additional prediction of individual positions, which is obtained from the crowd simulation algorithm. Our experimental results indicate that, by integrating simulation, the multi-person tracking performance such as MOTP and MOTA can be increased by an average about 2% and 5%, which provides significant evidence for the effectiveness of our approach.
Tracking individuals in video sequences, especially in crowded scenes, is still a challenging research topic in the area of pattern recognition and computer vision. However, current single camera tracking approaches are mostly based on visual features only. The novelty of the approach proposed in this paper is the integration of evidences from a crowd simulation algorithm into a pure vision based method. Based on a stateof-the-art tracking-by-detection method, the integration is achieved by evaluating particle weights with additional prediction of individual positions, which is obtained from the crowd simulation algorithm. Our experimental results indicate that, by integrating simulation, the multi-person tracking performance such as MOTP and MOTA can be increased by an average about 2% and 5%, which provides significant evidence for the effectiveness of our approach.
Integrating crowd simulation for pedestrian tracking in a multi-camera system
.png) Multi-camera multi-target tracking is one of the most active research topics in computer vision. However, many challenges remain to achieve robust performance in real-world video networks. In this paper we extend the state-of-the-art single camera tracking method, with both detection and crowd simulation, to a multiple camera tracking approach that exploits crowd simulation and uses principal axis-based integration. The experiments are conducted on PETS 2009 data set and the performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) based on the position of each pedestrian on the ground plane. It is demonstrated that the information from crowd simulation can provide significant advantage for tracking multiple pedestrians through multiple cameras.
Multi-camera multi-target tracking is one of the most active research topics in computer vision. However, many challenges remain to achieve robust performance in real-world video networks. In this paper we extend the state-of-the-art single camera tracking method, with both detection and crowd simulation, to a multiple camera tracking approach that exploits crowd simulation and uses principal axis-based integration. The experiments are conducted on PETS 2009 data set and the performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) based on the position of each pedestrian on the ground plane. It is demonstrated that the information from crowd simulation can provide significant advantage for tracking multiple pedestrians through multiple cameras.
Vehicle Logo Super-Resolution by Canonical Correlation Analysis
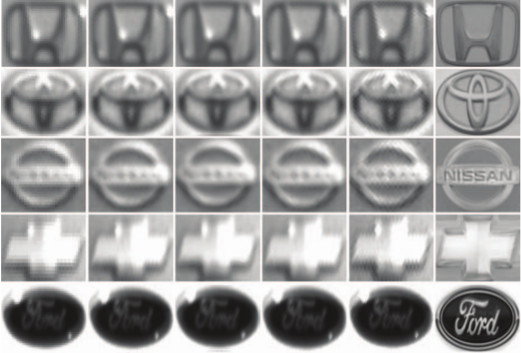 Recognition of a vehicle make is of interest in the fields of
law enforcement and surveillance. We have develop
a canonical correlation analysis (CCA) based method for
vehicle logo super-resolution to facilitate the recognition of
the vehicle make. From a limited number of high-resolution
logos, we populate the training dataset for each make using
gamma transformations. Given a vehicle logo from a low resolution
source (i.e., surveillance or traffic camera recordings),
the learned models yield super-resolved results. By
matching the low-resolution image and the generated high resolution
images, we select the final output that is closest to
the low-resolution image in the histogram of oriented gradients
(HOG) feature space. Experimental results show that our
approach outperforms the state-of-the-art super-resolution
methods in qualitative and quantitative measures. Furthermore,
the super-resolved logos help to improve the accuracy
in the subsequent recognition tasks significantly.
Recognition of a vehicle make is of interest in the fields of
law enforcement and surveillance. We have develop
a canonical correlation analysis (CCA) based method for
vehicle logo super-resolution to facilitate the recognition of
the vehicle make. From a limited number of high-resolution
logos, we populate the training dataset for each make using
gamma transformations. Given a vehicle logo from a low resolution
source (i.e., surveillance or traffic camera recordings),
the learned models yield super-resolved results. By
matching the low-resolution image and the generated high resolution
images, we select the final output that is closest to
the low-resolution image in the histogram of oriented gradients
(HOG) feature space. Experimental results show that our
approach outperforms the state-of-the-art super-resolution
methods in qualitative and quantitative measures. Furthermore,
the super-resolved logos help to improve the accuracy
in the subsequent recognition tasks significantly.
Dynamic Bayesian Networks for Vehicle Classification in Video
 Vehicle classification has evolved into a significant subject of study due to its importance in autonomous
navigation, traffic analysis, surveillance and security systems, and transportation management.
We present a
system which classifies a vehicle (given its direct rear-side view) into one of
four classes Sedan, Pickup truck, SUV/Minivan, and unknown. A feature set of tail light and vehicle
dimensions is extracted which feeds a feature selection algorithm.
A feature vector is then processed by a Hybrid Dynamic Bayesian Network (HDBN) to
classify each vehicle.
Vehicle classification has evolved into a significant subject of study due to its importance in autonomous
navigation, traffic analysis, surveillance and security systems, and transportation management.
We present a
system which classifies a vehicle (given its direct rear-side view) into one of
four classes Sedan, Pickup truck, SUV/Minivan, and unknown. A feature set of tail light and vehicle
dimensions is extracted which feeds a feature selection algorithm.
A feature vector is then processed by a Hybrid Dynamic Bayesian Network (HDBN) to
classify each vehicle.
Incremental Unsupervised Three-Dimensional Vehicle Model Learning From Video
 We introduce a new generic model-based approach for building 3-D models of vehicles
from color video from a single uncalibrated traffic-surveillance camera. We propose a novel directional
template method that uses trigonometric relations of the 2-D features and geometric relations of a single
3-D generic vehicle model to map 2-D features to 3-D in the face of projection and foreshortening effects.
Results are shown for several simulated and real traffic videos in an uncontrolled setup.
The performance of the proposed method for several types of
vehicles in two considerably different traffic spots is very promising to encourage its applicability in
3-D reconstruction of other rigid objects in video.
We introduce a new generic model-based approach for building 3-D models of vehicles
from color video from a single uncalibrated traffic-surveillance camera. We propose a novel directional
template method that uses trigonometric relations of the 2-D features and geometric relations of a single
3-D generic vehicle model to map 2-D features to 3-D in the face of projection and foreshortening effects.
Results are shown for several simulated and real traffic videos in an uncontrolled setup.
The performance of the proposed method for several types of
vehicles in two considerably different traffic spots is very promising to encourage its applicability in
3-D reconstruction of other rigid objects in video.
Bayesian Based 3D Shape Reconstruction from Video
 In a video sequence with a 3D rigid object moving,
changing shapes of the 2D projections provide interrelated
spatio-temporal cues for incremental 3D shape
reconstruction. This research describes a probabilistic
approach for intelligent view-integration to build 3D model
of vehicles from traffic videos collected from an
uncalibrated static camera. The proposed Bayesian net
framework allows the handling of uncertainties in a
systematic manner. The performance is verified with several
types of vehicles in different videos.
In a video sequence with a 3D rigid object moving,
changing shapes of the 2D projections provide interrelated
spatio-temporal cues for incremental 3D shape
reconstruction. This research describes a probabilistic
approach for intelligent view-integration to build 3D model
of vehicles from traffic videos collected from an
uncalibrated static camera. The proposed Bayesian net
framework allows the handling of uncertainties in a
systematic manner. The performance is verified with several
types of vehicles in different videos.
Automated classification of skippers based on parts representation
.png) Image data can help to understand species evolution from a new perspective. In this paper, we propose a parts-based (patch-based) representation for biological images. Experimental results show this compact model as efficient and effective for representing and classifying skipper images. The results can be further improved by exploiting symmetry of the shape and increasing the quality of image segmentation.
Image data can help to understand species evolution from a new perspective. In this paper, we propose a parts-based (patch-based) representation for biological images. Experimental results show this compact model as efficient and effective for representing and classifying skipper images. The results can be further improved by exploiting symmetry of the shape and increasing the quality of image segmentation.
Visual Learning by Evolutionary and Coevolutionary Feature Synthesis
 We present a novel method for learning complex concepts/hypotheses directly from raw
training data. The task addressed here concerns data-driven synthesis of recognition procedures for
real-world object recognition. The method uses linear genetic programming to encode potential
solutions expressed in terms of elementary operations, and handles the complexity of the learning
task by applying cooperative coevolution to decompose the problem automatically at the
genotype level. Extensive experimental results
show that the approach attains competitive performance for three-dimensional object recognition in real
synthetic aperture radar imagery.
We present a novel method for learning complex concepts/hypotheses directly from raw
training data. The task addressed here concerns data-driven synthesis of recognition procedures for
real-world object recognition. The method uses linear genetic programming to encode potential
solutions expressed in terms of elementary operations, and handles the complexity of the learning
task by applying cooperative coevolution to decompose the problem automatically at the
genotype level. Extensive experimental results
show that the approach attains competitive performance for three-dimensional object recognition in real
synthetic aperture radar imagery.
Coevolution and Linear Genetic Programming for Visual Learning
 We introduce a novel genetically-inspired visual learning method. Given the training images,
this general approach induces a sophisticated feature-based recognition system, by using cooperative
coevolution and linear genetic programming for the procedural representation of feature extraction agents.
The paper describes the learning algorithm and provides a firm rationale for its design. An extensive
experimental evaluation, on the demanding real-world task of object recognition in synthetic aperture radar
(SAR) imagery, shows the competitiveness of the proposed approach with human-designed recognition
systems.
We introduce a novel genetically-inspired visual learning method. Given the training images,
this general approach induces a sophisticated feature-based recognition system, by using cooperative
coevolution and linear genetic programming for the procedural representation of feature extraction agents.
The paper describes the learning algorithm and provides a firm rationale for its design. An extensive
experimental evaluation, on the demanding real-world task of object recognition in synthetic aperture radar
(SAR) imagery, shows the competitiveness of the proposed approach with human-designed recognition
systems.
Visual Learning by Evolutionary Feature Synthesis
 We present a novel method for learning complex concepts/hypotheses directly from raw
training data. The task addressed here concerns data-driven synthesis of recognition procedures for
real-world object recognition task. The method uses linear genetic programming to encode potential
solutions expressed in terms of elementary operations, and handles the complexity of the learning task
by applying cooperative coevolution to decompose the problem automatically. The training consists in
coevolving feature extraction procedures, each being a sequence of elementary image processing and
feature extraction operations. Extensive experimental results show that the approach attains competitive
performance for 3-D object recognition in real synthetic aperture radar (SAR) imagery.
We present a novel method for learning complex concepts/hypotheses directly from raw
training data. The task addressed here concerns data-driven synthesis of recognition procedures for
real-world object recognition task. The method uses linear genetic programming to encode potential
solutions expressed in terms of elementary operations, and handles the complexity of the learning task
by applying cooperative coevolution to decompose the problem automatically. The training consists in
coevolving feature extraction procedures, each being a sequence of elementary image processing and
feature extraction operations. Extensive experimental results show that the approach attains competitive
performance for 3-D object recognition in real synthetic aperture radar (SAR) imagery.
Incremental Vehicle 3-D Modeling from Video
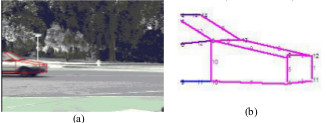 We present a new model-based approach
for building 3-D models of vehicles from color video
provided by a traffic surveillance camera. We
incrementally build 3D models using a clustering
technique. Geometrical relations based on 3D generic
vehicle model map 2D features to 3D. The 3D features are
then adaptively clustered over the frame sequence to
incrementally generate the 3D model of the vehicle.
Results are shown for both simulated and real traffic video.
They are evaluated by a new structural performance
measure underscoring usefulness of incremental learning.
We present a new model-based approach
for building 3-D models of vehicles from color video
provided by a traffic surveillance camera. We
incrementally build 3D models using a clustering
technique. Geometrical relations based on 3D generic
vehicle model map 2D features to 3D. The 3D features are
then adaptively clustered over the frame sequence to
incrementally generate the 3D model of the vehicle.
Results are shown for both simulated and real traffic video.
They are evaluated by a new structural performance
measure underscoring usefulness of incremental learning.
Unsupervised Learning for Incremental 3-D Modeling
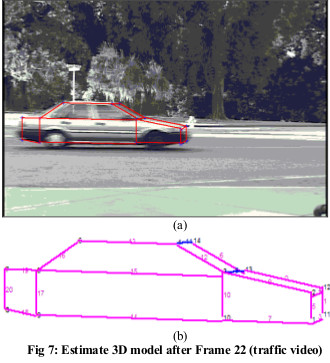 Learning based incremental 3D modeling of traffic
vehicles from uncalibrated video data stream has enormous
application potential in traffic monitoring and intelligent
transportation systems. In this research, video data from a
traffic surveillance camera is used to incrementally
develop the 3D model of vehicles using a clustering based
unsupervised learning. Geometrical relations based on 3D
generic vehicle model map 2D features to 3D. The 3D
features are then adaptively clustered over the frames to
incrementally generate the 3D model of the vehicle.
Results are shown for both simulated and real traffic video.
They are evaluated by a structural performance measure.
Learning based incremental 3D modeling of traffic
vehicles from uncalibrated video data stream has enormous
application potential in traffic monitoring and intelligent
transportation systems. In this research, video data from a
traffic surveillance camera is used to incrementally
develop the 3D model of vehicles using a clustering based
unsupervised learning. Geometrical relations based on 3D
generic vehicle model map 2D features to 3D. The 3D
features are then adaptively clustered over the frames to
incrementally generate the 3D model of the vehicle.
Results are shown for both simulated and real traffic video.
They are evaluated by a structural performance measure.
Learning models for predicting recognition performance
.png) This paper addresses one of the fundamental problems encountered in performance prediction for object recognition. In particular we address the problems related to estimation of small gallery size that can give good error estimates and their confidences on large probe sets and populations. We use a generalized two-dimensional prediction model that integrates a hypergeometric probability distribution model with a binomial model explicitly and considers the distortion problem in large populations. We incorporate learning in the prediction process in order to find the optimal small gallery size and to improve its performance. The Chernoff and Chebychev inequalities are used as a guide to obtain the small gallery size. During the prediction we use the expectation-maximum (EM) algorithm to learn the match score and the non-match score distributions (the number of components, their weights, means and covariances) that are represented as Gaussian mixtures. By learning we find the optimal size of small gallery and at the same time provide the upper bound and the lower bound for the prediction on large populations. Results are shown using real-world databases.
This paper addresses one of the fundamental problems encountered in performance prediction for object recognition. In particular we address the problems related to estimation of small gallery size that can give good error estimates and their confidences on large probe sets and populations. We use a generalized two-dimensional prediction model that integrates a hypergeometric probability distribution model with a binomial model explicitly and considers the distortion problem in large populations. We incorporate learning in the prediction process in order to find the optimal small gallery size and to improve its performance. The Chernoff and Chebychev inequalities are used as a guide to obtain the small gallery size. During the prediction we use the expectation-maximum (EM) algorithm to learn the match score and the non-match score distributions (the number of components, their weights, means and covariances) that are represented as Gaussian mixtures. By learning we find the optimal size of small gallery and at the same time provide the upper bound and the lower bound for the prediction on large populations. Results are shown using real-world databases.
Visual learning by coevolutionary feature synthesis
.png) In this paper, a novel genetically inspired visual learning method is proposed. Given the training raster images, this general approach induces a sophisticated feature-based recognition system. It employs the paradigm of cooperative coevolution to handle the computational difficulty of this task. To represent the feature extraction agents, the linear genetic programming is used. The paper describes the learning algorithm and provides a firm rationale for its design. Different architectures of recognition systems are considered that employ the proposed feature synthesis method. An extensive experimental evaluation on the demanding real-world task of object recognition in synthetic aperture radar (SAR) imagery shows the ability of the proposed approach to attain high recognition performance in different operating conditions.
In this paper, a novel genetically inspired visual learning method is proposed. Given the training raster images, this general approach induces a sophisticated feature-based recognition system. It employs the paradigm of cooperative coevolution to handle the computational difficulty of this task. To represent the feature extraction agents, the linear genetic programming is used. The paper describes the learning algorithm and provides a firm rationale for its design. Different architectures of recognition systems are considered that employ the proposed feature synthesis method. An extensive experimental evaluation on the demanding real-world task of object recognition in synthetic aperture radar (SAR) imagery shows the ability of the proposed approach to attain high recognition performance in different operating conditions.
Evolutionary Feature Synthesis for Object Recognition
 We've developed a coevolutionary genetic
programming (CGP) approach to learn composite features for object recognition. The motivation for using CGP is to
overcome the limitations of human experts who consider only a small number of conventional
combinations of primitive features during synthesis. CGP, on the other hand, can try a very large number
of unconventional combinations and these unconventional combinations yield exceptionally good results
in some cases. The comparison with other classical classification algorithms
is favourable to the CGP-based approach we've proposed.
We've developed a coevolutionary genetic
programming (CGP) approach to learn composite features for object recognition. The motivation for using CGP is to
overcome the limitations of human experts who consider only a small number of conventional
combinations of primitive features during synthesis. CGP, on the other hand, can try a very large number
of unconventional combinations and these unconventional combinations yield exceptionally good results
in some cases. The comparison with other classical classification algorithms
is favourable to the CGP-based approach we've proposed.
Cooperative coevolution fusion for moving object detection
.png) In this paper we introduce a novel sensor fusion algorithm based on the cooperative coevolutionary paradigm. We develop a multisensor robust moving object detection system that can operate under a variety of illumination and environmental conditions. Our experiments indicate that this evolutionary paradigm is well suited as a sensor fusion model and can be extended to different sensing modalities.
In this paper we introduce a novel sensor fusion algorithm based on the cooperative coevolutionary paradigm. We develop a multisensor robust moving object detection system that can operate under a variety of illumination and environmental conditions. Our experiments indicate that this evolutionary paradigm is well suited as a sensor fusion model and can be extended to different sensing modalities.
Object detection in multimodal images using genetic programming
.png) In this paper, we learn to discover composite operators and features that are synthesized from combinations of primitive image processing operations for object detection. Our approach is based on genetic programming (GP). The motivation for using GP-based learning is that we hope to automate the design of object detection system by automatically synthesizing object detection procedures from primitive operations and primitive features. The human expert, limited by experience, knowledge and time, can only try a very small number of conventional combinations. Genetic programming, on the other hand, attempts many unconventional combinations that may never be imagined by human experts. In some cases, these unconventional combinations yield exceptionally good results.
In this paper, we learn to discover composite operators and features that are synthesized from combinations of primitive image processing operations for object detection. Our approach is based on genetic programming (GP). The motivation for using GP-based learning is that we hope to automate the design of object detection system by automatically synthesizing object detection procedures from primitive operations and primitive features. The human expert, limited by experience, knowledge and time, can only try a very small number of conventional combinations. Genetic programming, on the other hand, attempts many unconventional combinations that may never be imagined by human experts. In some cases, these unconventional combinations yield exceptionally good results.
Physical models for moving shadow and object detection in video
.png) Current moving object detection systems typically detect shadows cast by the moving object as part of the moving object. In this paper, the problem of separating moving cast shadows from the moving objects in an outdoor environment is addressed. Unlike previous work, we present an approach that does not rely on any geometrical assumptions such as camera location and ground surface/object geometry. The approach is based on a new spatio-temporal albedo test and dichromatic reflection model and accounts for both the sun and the sky illuminations. Results are presented for several video sequences representing a variety of ground materials when the shadows are cast on different surface types. These results show that our approach is robust to widely different background and foreground materials, and illuminations.
Current moving object detection systems typically detect shadows cast by the moving object as part of the moving object. In this paper, the problem of separating moving cast shadows from the moving objects in an outdoor environment is addressed. Unlike previous work, we present an approach that does not rely on any geometrical assumptions such as camera location and ground surface/object geometry. The approach is based on a new spatio-temporal albedo test and dichromatic reflection model and accounts for both the sun and the sky illuminations. Results are presented for several video sequences representing a variety of ground materials when the shadows are cast on different surface types. These results show that our approach is robust to widely different background and foreground materials, and illuminations.
Multiple look angle SAR recognition
.png) The focus of this paper is optimizing the recognition of vehicles in Synthetic Aperture radar (SAR) imagery by exploiting the azimuthal variance of scatterers using multiple SAR recognizers at different look angles. The variance of SAR scattering center locations with target azimuth leads to recognition system results at different azimuths that are independent, even for small azimuth deltas. Extensive experimental recognition results are presented in terms of receiver operating characteristic (ROC) curves to show the effects of multiple look angles on recognition performance for MSTAR vehicle targets with configuration variants, articulation, and occlusion.
The focus of this paper is optimizing the recognition of vehicles in Synthetic Aperture radar (SAR) imagery by exploiting the azimuthal variance of scatterers using multiple SAR recognizers at different look angles. The variance of SAR scattering center locations with target azimuth leads to recognition system results at different azimuths that are independent, even for small azimuth deltas. Extensive experimental recognition results are presented in terms of receiver operating characteristic (ROC) curves to show the effects of multiple look angles on recognition performance for MSTAR vehicle targets with configuration variants, articulation, and occlusion.
Learning composite features for object recognition
.png) Features represent the characteristics of objects and selecting or synthesizing effective composite features are the key factors to the performance of object recognition. In this paper, we propose a co-evolutionary genetic programming (CGP) approach to learn composite features for object recognition. The motivation for using CGP is to overcome the limitations of human experts who consider only a small number of conventional combinations of primitive features during synthesis. On the other hand, CGP can try a very large number of unconventional combinations and these unconventional combinations may yield exceptionally good results in some cases. Our experimental results with real synthetic aperture radar (SAR) images show that CGP can learn good composite features. We show results to distinguish objects from clutter and to distinguish objects that belong to several classes.
Features represent the characteristics of objects and selecting or synthesizing effective composite features are the key factors to the performance of object recognition. In this paper, we propose a co-evolutionary genetic programming (CGP) approach to learn composite features for object recognition. The motivation for using CGP is to overcome the limitations of human experts who consider only a small number of conventional combinations of primitive features during synthesis. On the other hand, CGP can try a very large number of unconventional combinations and these unconventional combinations may yield exceptionally good results in some cases. Our experimental results with real synthetic aperture radar (SAR) images show that CGP can learn good composite features. We show results to distinguish objects from clutter and to distinguish objects that belong to several classes.
Stochastic Models for Recognition of Occluded Targets
 Recognition of occluded objects in synthetic aperture radar (SAR) images is a significant problem for
automatic target recognition. Stochastic models provide some attractive features for pattern matching
and recognition under partial occlusion and noise. We present a hidden Markov modeling
based approach for recognizing objects in SAR images. We identify the peculiar characteristics of SAR
sensors and using these characteristics we develop feature based multiple models for a given SAR image
of an object. In order to improve
performance we integrate these models synergistically using their probabilistic estimates for recognition of
a particular target at a specific azimuth. Experimental results are presented using both synthetic
and real SAR images.
Recognition of occluded objects in synthetic aperture radar (SAR) images is a significant problem for
automatic target recognition. Stochastic models provide some attractive features for pattern matching
and recognition under partial occlusion and noise. We present a hidden Markov modeling
based approach for recognizing objects in SAR images. We identify the peculiar characteristics of SAR
sensors and using these characteristics we develop feature based multiple models for a given SAR image
of an object. In order to improve
performance we integrate these models synergistically using their probabilistic estimates for recognition of
a particular target at a specific azimuth. Experimental results are presented using both synthetic
and real SAR images.
Coevolutionary computation for synthesis of recognition systems
.png) This paper introduces a novel visual learning method that involves cooperative coevolution and linear genetic programming. Given exclusively training images, the evolutionary learning algorithm induces a set of sophisticated feature extraction agents represented in a procedural way. The proposed method incorporates only general vision-related background knowledge and does not require any task-specific information. The paper describes the learning algorithm, provides a firm rationale for its design, and proves its competitiveness with the human-designed recognition systems in an extensive experimental evaluation, on the demanding real-world task of object recognition in synthetic aperture radar (SAR) imagery.
This paper introduces a novel visual learning method that involves cooperative coevolution and linear genetic programming. Given exclusively training images, the evolutionary learning algorithm induces a set of sophisticated feature extraction agents represented in a procedural way. The proposed method incorporates only general vision-related background knowledge and does not require any task-specific information. The paper describes the learning algorithm, provides a firm rationale for its design, and proves its competitiveness with the human-designed recognition systems in an extensive experimental evaluation, on the demanding real-world task of object recognition in synthetic aperture radar (SAR) imagery.
Coevolving feature extraction agents for target recognition in SAR images
.png) This paper describes a novel evolutionary method for automatic induction of target recognition procedures from examples. The learning process starts with training data containing SAR images with labeled targets and consists in coevolving the population of feature extraction agents that cooperate to build an appropriate representation of the input image. Features extracted by a team of cooperating agents are used to induce a machine learning classifier that is responsible for making the final decision of recognizing a target in a SAR image. Each agent (individual) contains feature extraction procedure encoded according to the principles of linear genetic programming (LGP). Like `plain" genetic programming, in LGP an agent"s genome encodes a program that is executed and tested on the set of training images during the fitness calculation. The program is a sequence of calls to the library of parameterized operations, including, but not limited to, global and local image processing operations, elementary feature extraction, and logic and arithmetic operations. Particular calls operate on working variables that enable the program to store intermediate results, and therefore design complex features. This paper contains detailed description of the learning and recognition methodology outlined here. In experimental part, we report and analyze the results obtained when testing the proposed approach for SAR target recognition using MSTAR database.
This paper describes a novel evolutionary method for automatic induction of target recognition procedures from examples. The learning process starts with training data containing SAR images with labeled targets and consists in coevolving the population of feature extraction agents that cooperate to build an appropriate representation of the input image. Features extracted by a team of cooperating agents are used to induce a machine learning classifier that is responsible for making the final decision of recognizing a target in a SAR image. Each agent (individual) contains feature extraction procedure encoded according to the principles of linear genetic programming (LGP). Like `plain" genetic programming, in LGP an agent"s genome encodes a program that is executed and tested on the set of training images during the fitness calculation. The program is a sequence of calls to the library of parameterized operations, including, but not limited to, global and local image processing operations, elementary feature extraction, and logic and arithmetic operations. Particular calls operate on working variables that enable the program to store intermediate results, and therefore design complex features. This paper contains detailed description of the learning and recognition methodology outlined here. In experimental part, we report and analyze the results obtained when testing the proposed approach for SAR target recognition using MSTAR database.
Composite class models for SAR recognition
.png) This paper focuses on a genetic algorithm based method that automates the construction of local feature based composite class models to capture the salient characteristics of configuration variants of vehicle targets in SAR imagery and increase the performance of SAR recognition systems. The recognition models are based on quasi-invariant local features: SAR scattering center locations and magnitudes. The approach uses an efficient SAR recognition system as an evaluation function to determine the fitness class models. Experimental results are given on the fitness of the composite models and the similarity of both the original training model configurations and the synthesized composite models to the test configurations. In addition, results are presented to show the SAR recognition variants of MSTAR vehicle targets.
This paper focuses on a genetic algorithm based method that automates the construction of local feature based composite class models to capture the salient characteristics of configuration variants of vehicle targets in SAR imagery and increase the performance of SAR recognition systems. The recognition models are based on quasi-invariant local features: SAR scattering center locations and magnitudes. The approach uses an efficient SAR recognition system as an evaluation function to determine the fitness class models. Experimental results are given on the fitness of the composite models and the similarity of both the original training model configurations and the synthesized composite models to the test configurations. In addition, results are presented to show the SAR recognition variants of MSTAR vehicle targets.
Performance modeling of vote-based object recognition
.png) The focus of this paper is predicting the bounds on performance of a vote-based object recognition system, when the test data features are distorted by uncertainty in both feature locations and magnitudes, by occlusion and by clutter. An improved method is presented to calculate lower and upper bound predictions of the probability that objects with various levels of distorted features will be recognized correctly. The prediction method takes model similarity into account, so that when models of objects are more similar to each other, then the probability of correct recognition is lower. The effectiveness of the prediction method is validated in a synthetic aperture radar (SAR) automatic target recognition (ATR) application using MSTAR public SAR data, which are obtained under different depression angles, object configurations and object articulations. Experiments show the performance improvement that can obtained by considering the feature magnitudes, compared to a previous performance prediction method that only considered the locations of features. In addition, the predicted performance is compared with actual performance of a vote-based SAR recognition system using the same SAR scatterer location and magnitude features.
The focus of this paper is predicting the bounds on performance of a vote-based object recognition system, when the test data features are distorted by uncertainty in both feature locations and magnitudes, by occlusion and by clutter. An improved method is presented to calculate lower and upper bound predictions of the probability that objects with various levels of distorted features will be recognized correctly. The prediction method takes model similarity into account, so that when models of objects are more similar to each other, then the probability of correct recognition is lower. The effectiveness of the prediction method is validated in a synthetic aperture radar (SAR) automatic target recognition (ATR) application using MSTAR public SAR data, which are obtained under different depression angles, object configurations and object articulations. Experiments show the performance improvement that can obtained by considering the feature magnitudes, compared to a previous performance prediction method that only considered the locations of features. In addition, the predicted performance is compared with actual performance of a vote-based SAR recognition system using the same SAR scatterer location and magnitude features.
\
Genetic Algorithm Based Feature Selection for Target Detection in SAR Images
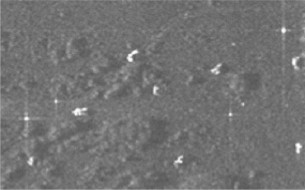 A genetic algorithm (GA) approach is presented to select a set of features to discriminate the targets from
the natural clutter false alarms in SAR images. A new fitness function based on minimum
description length principle (MDLP) is proposed to drive GA and it is compared with three other fitness
functions. Experimental results show that the new fitness function outperforms the other three fitness
functions and the GA driven by it selected a good subset of features to discriminate the targets from
clutters effectively.
A genetic algorithm (GA) approach is presented to select a set of features to discriminate the targets from
the natural clutter false alarms in SAR images. A new fitness function based on minimum
description length principle (MDLP) is proposed to drive GA and it is compared with three other fitness
functions. Experimental results show that the new fitness function outperforms the other three fitness
functions and the GA driven by it selected a good subset of features to discriminate the targets from
clutters effectively.
Discovering operators and features for object detection
.png) In this paper, we learn to discover composite operators and features that are evolved from combinations of primitive image processing operations to extract regions-of-interest (ROls) in images. Our approach is based on genetic programming (GP). The motivation for using GP is that there are a great many ways of combining these primitive operations and the human expert, limited by experience, knowledge and time. can only try a very small number of conventional ways of combination. Genetic programming, on the other hand, attempts many unconventional ways of combination that may never be imagined by human experts. In some cases, these unconventional combinations yield exceptionally good results. Our experimental results show that GP can find good composite operators to effectively extract the regions of interest in an image and the. learned composite operators can be applied to extract ROls in other similar images.
In this paper, we learn to discover composite operators and features that are evolved from combinations of primitive image processing operations to extract regions-of-interest (ROls) in images. Our approach is based on genetic programming (GP). The motivation for using GP is that there are a great many ways of combining these primitive operations and the human expert, limited by experience, knowledge and time. can only try a very small number of conventional ways of combination. Genetic programming, on the other hand, attempts many unconventional ways of combination that may never be imagined by human experts. In some cases, these unconventional combinations yield exceptionally good results. Our experimental results show that GP can find good composite operators to effectively extract the regions of interest in an image and the. learned composite operators can be applied to extract ROls in other similar images.
Exploiting azimuthal variance of scatterers for multiple look SAR recognition
.png) The focus of this paper is optimizing the recognition of vehicles in Synthetic Aperture Radar (SAR) imagery using multiple SAR recognizers at different look angles. The variance of SAR scattering center locations with target azimuth leads to recognition system results at different azimuths that are independent, even for small azimuth deltas. Extensive experimental recognition results are presented in terms of receiver operating characteristic (ROC) curves to show the effects of multiple look angles on recognition performance for MSTAR vehicle targets with configuration variants, articulation, and occlusion.
The focus of this paper is optimizing the recognition of vehicles in Synthetic Aperture Radar (SAR) imagery using multiple SAR recognizers at different look angles. The variance of SAR scattering center locations with target azimuth leads to recognition system results at different azimuths that are independent, even for small azimuth deltas. Extensive experimental recognition results are presented in terms of receiver operating characteristic (ROC) curves to show the effects of multiple look angles on recognition performance for MSTAR vehicle targets with configuration variants, articulation, and occlusion.
Increasing the Discrimination of Synthetic Aperture Radar Recognition Models
 The focus of this work is optimizing recognition models for synthetic aperture radar (SAR)
signatures of vehicles to improve the performance of a recognition algorithm under the extended
operating conditions of target articulation, occlusion, and configuration variants. The approach
determines the similarities and differences among the various vehicle models. Methods to penalize similar
features or reward dissimilar features are used to increase the distinguishability of the recognition model
instances.
The focus of this work is optimizing recognition models for synthetic aperture radar (SAR)
signatures of vehicles to improve the performance of a recognition algorithm under the extended
operating conditions of target articulation, occlusion, and configuration variants. The approach
determines the similarities and differences among the various vehicle models. Methods to penalize similar
features or reward dissimilar features are used to increase the distinguishability of the recognition model
instances.
Feature selection for target detection in SAR images
.png) A genetic algorithm (GA) approach is presented to select a set of features to discriminate the targets from the natural clutter false alarms in SAR images. Four stages of an automatic target detection system are developed: the rough target detection, feature extraction from the potential target regions, GA based feature selection and the final Bayesian classification. Experimental results show that the GA selected a good subset of features that gave similar performance to using all the features.
A genetic algorithm (GA) approach is presented to select a set of features to discriminate the targets from the natural clutter false alarms in SAR images. Four stages of an automatic target detection system are developed: the rough target detection, feature extraction from the potential target regions, GA based feature selection and the final Bayesian classification. Experimental results show that the GA selected a good subset of features that gave similar performance to using all the features.
Multistrategy fusion using mixture model for moving object detection
.png) In a video surveillance domain, mixture models are used in conjunction with a variety of features and filters to detect and track moving objects. However, these systems do not provide clear performance results at the pixel detection level. In this paper, we apply the mixture model to provide several fusion strategies based on the competitive and cooperative principles of integration which we call OR, and AND strategies. In addition, we apply the Dempster-Shafer method to mixture models for object detection. Using two video databases, we show the performance of each fusion strategy using receiver operating characteristic (ROC) curves.
In a video surveillance domain, mixture models are used in conjunction with a variety of features and filters to detect and track moving objects. However, these systems do not provide clear performance results at the pixel detection level. In this paper, we apply the mixture model to provide several fusion strategies based on the competitive and cooperative principles of integration which we call OR, and AND strategies. In addition, we apply the Dempster-Shafer method to mixture models for object detection. Using two video databases, we show the performance of each fusion strategy using receiver operating characteristic (ROC) curves.
Predicting an Upper Bound on SAR ATR Performance
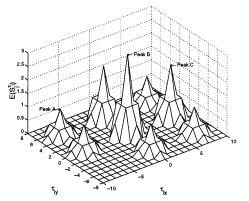 We present a method for predicting a tight upper bound on performance of a vote-based approach for
automatic target recognition (ATR) in synthetic aperture radar (SAR) images. The proposed method
considers data distortion factors such as uncertainty, occlusion,
and clutter, as well as model factors such as structural similarity. The proposed method is validated using
MSTAR public SAR data, which are obtained
under different depression angles, configurations, and articulations.
We present a method for predicting a tight upper bound on performance of a vote-based approach for
automatic target recognition (ATR) in synthetic aperture radar (SAR) images. The proposed method
considers data distortion factors such as uncertainty, occlusion,
and clutter, as well as model factors such as structural similarity. The proposed method is validated using
MSTAR public SAR data, which are obtained
under different depression angles, configurations, and articulations.
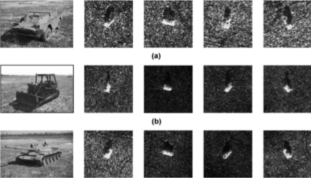
Recognizing Occluded Objects in SAR Images
 Recognition
algorithms, based on local features, are presented that successfully recognize highly occluded objects in both
XPATCH synthetic SAR signatures and real SAR images of actual vehicles from the MSTAR data. Extensive
experimental results are presented for a basic recognition algorithm and for an improved algorithm.
The results show the effect of occlusion on
recognition performance in terms of probability of correct identification (PCI), receiver operating characteristic
(ROC) curves, and confusion matrices.
Recognition
algorithms, based on local features, are presented that successfully recognize highly occluded objects in both
XPATCH synthetic SAR signatures and real SAR images of actual vehicles from the MSTAR data. Extensive
experimental results are presented for a basic recognition algorithm and for an improved algorithm.
The results show the effect of occlusion on
recognition performance in terms of probability of correct identification (PCI), receiver operating characteristic
(ROC) curves, and confusion matrices.
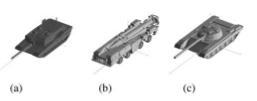
Recognizing target variants and articulations in synthetic aperture radar images
.png) The focus of this paper is recognizing articulated vehicles and actual vehicle configuration variants in real synthetic aperture radar (SAR) images. Using SAR scattering-center locations and magnitudes as features, the invariance of these features is shown with articulation (e.g., rotation of a tank turret), with configuration variants, and with a small change in depression angle. This scatterer-location and magnitude quasiinvariance is used as a basis for development of a SAR recognition system that successfully identifies real articulated and nonstandard- configuration vehicles based on nonarticulated, standard recognition models. Identification performance results are presented as vote-space scatterplots and receiver operating characteristic curves for configuration variants, for articulated objects, and for a small change in depression angle with the MSTAR public data.
The focus of this paper is recognizing articulated vehicles and actual vehicle configuration variants in real synthetic aperture radar (SAR) images. Using SAR scattering-center locations and magnitudes as features, the invariance of these features is shown with articulation (e.g., rotation of a tank turret), with configuration variants, and with a small change in depression angle. This scatterer-location and magnitude quasiinvariance is used as a basis for development of a SAR recognition system that successfully identifies real articulated and nonstandard- configuration vehicles based on nonarticulated, standard recognition models. Identification performance results are presented as vote-space scatterplots and receiver operating characteristic curves for configuration variants, for articulated objects, and for a small change in depression angle with the MSTAR public data.
Adaptive target recognition
.png) Target recognition is a multilevel process requiring a sequence of algorithms at low, intermediate and high levels. Generally, such systems are open loop with no feedback between levels and assuring their performance at the given probability of correct identification (PCI) and probability of false alarm (P f) is a key challenge in computer vision and pattern recognition research. In this paper, a robust closed-loop system for recognition of SAR images based on reinforcement learning is presented. The parameters in model-based SAR target recognition are learned. It has been experimentally validated by learning the parameters of the recognition system for SAR imagery, successfully recognizing articulated targets, targets of different configuration and targets at different depression angles.
Target recognition is a multilevel process requiring a sequence of algorithms at low, intermediate and high levels. Generally, such systems are open loop with no feedback between levels and assuring their performance at the given probability of correct identification (PCI) and probability of false alarm (P f) is a key challenge in computer vision and pattern recognition research. In this paper, a robust closed-loop system for recognition of SAR images based on reinforcement learning is presented. The parameters in model-based SAR target recognition are learned. It has been experimentally validated by learning the parameters of the recognition system for SAR imagery, successfully recognizing articulated targets, targets of different configuration and targets at different depression angles.
Predicting Performance of Object Recognition
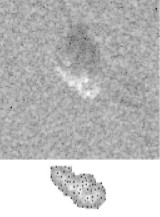 We present a method for predicting fundamental performance of object recognition.
The proposed method considers data distortion factors such as uncertainty,
occlusion, and clutter, in addition to model similarity. This is unlike previous approaches, which consider
only a subset of these factors. Performance is predicted in two stages. In the first stage, the similarity between
every pair of model objects is captured. In the second stage, the similarity information is used along with statistical
models of the data-distortion factors to determine an upper bound on the probability of recognition error.
This bound is directly used to determine a lower bound on the probability of correct recognition.
We present a method for predicting fundamental performance of object recognition.
The proposed method considers data distortion factors such as uncertainty,
occlusion, and clutter, in addition to model similarity. This is unlike previous approaches, which consider
only a subset of these factors. Performance is predicted in two stages. In the first stage, the similarity between
every pair of model objects is captured. In the second stage, the similarity information is used along with statistical
models of the data-distortion factors to determine an upper bound on the probability of recognition error.
This bound is directly used to determine a lower bound on the probability of correct recognition.
Recognition of occluded objects using stochastic models
.png) Recognition of occlude d objects in synthetic aperture radar (SAR) images is a significant problem for automatic target recognition. In this paper, we present a hidden Markov modeling (HMM) based approach for recognizing objects in synthetic aperturadar (SAR) images. We identify the peculiar characteristics of SAR sensors and using these characteristics we develop feature based multiple models for a given SAR image of an object. The models exploiting the relative geometry of feature locations or the amplitude of SAR radar return are based on sequentialization of scattering centers extracted from SAR images. In order to improve performance we integrate these models synergistically using their probabilistic estimates for recognition of a particular target at a specific azimuth. Experimental results are presented using both synthetic and real SAR images.
Recognition of occlude d objects in synthetic aperture radar (SAR) images is a significant problem for automatic target recognition. In this paper, we present a hidden Markov modeling (HMM) based approach for recognizing objects in synthetic aperturadar (SAR) images. We identify the peculiar characteristics of SAR sensors and using these characteristics we develop feature based multiple models for a given SAR image of an object. The models exploiting the relative geometry of feature locations or the amplitude of SAR radar return are based on sequentialization of scattering centers extracted from SAR images. In order to improve performance we integrate these models synergistically using their probabilistic estimates for recognition of a particular target at a specific azimuth. Experimental results are presented using both synthetic and real SAR images.
Object recognition results using MSTAR synthetic aperture radar data
.png) This paper outlines an approach and experimental results for Synthetic Aperture Radar (SAR) object recognition using the MSTAR data. With SAR scattering c enter locations and magnitudes as features, the invariance of these features is shown with object articulation (e.g., rotation of a tank turret) and with external configuration variants. This scatterer location and magnitude quasi-invariance is used as a basis for development of a SAR recognition system that successfully identifies articulated and non-standard configuration vehicles based on non-articulated, standard recognition models. The forced recognition results and pose accuracy are given. The effect of different confusers on the receiver operating characteristic (ROC) curves are illustrated along with ROC curves for configuration variants, articulations and small changes in depression angle. Results are given that show that integrating the results of multiple recognizers can lead to significantly improved performance over the single best recognizer.
This paper outlines an approach and experimental results for Synthetic Aperture Radar (SAR) object recognition using the MSTAR data. With SAR scattering c enter locations and magnitudes as features, the invariance of these features is shown with object articulation (e.g., rotation of a tank turret) and with external configuration variants. This scatterer location and magnitude quasi-invariance is used as a basis for development of a SAR recognition system that successfully identifies articulated and non-standard configuration vehicles based on non-articulated, standard recognition models. The forced recognition results and pose accuracy are given. The effect of different confusers on the receiver operating characteristic (ROC) curves are illustrated along with ROC curves for configuration variants, articulations and small changes in depression angle. Results are given that show that integrating the results of multiple recognizers can lead to significantly improved performance over the single best recognizer.
Recognizing Articulated Objects in SAR Images
 We introduced the first successful approach for recognizing articulated vehicles in real synthetic aperture
radar (SAR) images. Although related to geometric hashing, our recognition approach is specifically designed for
SAR, taking into account the great azimuthal variation and moderate articulation invariance of SAR signatures.
We present a basic recognition system for the XPATCH data, and an
improved recognition system that achieves excellent results
with the more limited articulation invariance encountered with the real SAR targets in the MSTAR data.
We introduced the first successful approach for recognizing articulated vehicles in real synthetic aperture
radar (SAR) images. Although related to geometric hashing, our recognition approach is specifically designed for
SAR, taking into account the great azimuthal variation and moderate articulation invariance of SAR signatures.
We present a basic recognition system for the XPATCH data, and an
improved recognition system that achieves excellent results
with the more limited articulation invariance encountered with the real SAR targets in the MSTAR data.
Recognition of Articulated and Occluded Objects
 A model-based automatic target recognition (ATR) system is developed to recognize articulated and
occluded objects in Synthetic Aperture Radar (SAR) images, based on invariant features of the objects.
The basic elements of the new recognition system are described and performance results are
given for articulated, occluded and occluded articulated objects and they are related to the target articulation
invariance and percent unoccluded.
A model-based automatic target recognition (ATR) system is developed to recognize articulated and
occluded objects in Synthetic Aperture Radar (SAR) images, based on invariant features of the objects.
The basic elements of the new recognition system are described and performance results are
given for articulated, occluded and occluded articulated objects and they are related to the target articulation
invariance and percent unoccluded.
Performance prediction and validation for object recognition
.png) This paper addresses the problem of predicting fundamental performance of vote-based object recognition using 2-0 point features. It presents Q method for predicting Q tight lower bound on performance. Unlike previous approaches, the proposed method considers data-distortion factors, namely uncertainty, occlusion, and clutter, in addition to model similarity, simultaneously. The similarity between every pair of model objects is captured by comparing their structures as a function of the relative transformation between them. This information is used along with statistical models of the data-distortion factors to determine an upper bound on the probability of recognition error. This bound is directly used to determine a lower bound on the probability of correct recognition. The validity of the method is experimentally demonstrated using synthetic aperture radar (SAR) data obtained under different depression angles and target configurations.
This paper addresses the problem of predicting fundamental performance of vote-based object recognition using 2-0 point features. It presents Q method for predicting Q tight lower bound on performance. Unlike previous approaches, the proposed method considers data-distortion factors, namely uncertainty, occlusion, and clutter, in addition to model similarity, simultaneously. The similarity between every pair of model objects is captured by comparing their structures as a function of the relative transformation between them. This information is used along with statistical models of the data-distortion factors to determine an upper bound on the probability of recognition error. This bound is directly used to determine a lower bound on the probability of correct recognition. The validity of the method is experimentally demonstrated using synthetic aperture radar (SAR) data obtained under different depression angles and target configurations.
Quasi-invariants for recognition of articulated and non-standard objects in SAR images
.png) Using SAR scattering center locations and magnitudes as features, invariances with articulation (i.e., turret rotation for the ZSU 23/4 gun and T72 tank), with configuration variants (e.g. fuel barrels, searchlights, etc.) and with a depression angle change are shown for real SAR images obtained from the MSTAR public data. This location and magnitude quasi-invariance forms a basis for an innovative SAR recognition engine that successfully identifies real articulated and non-standard configuration vehicles based on non-articulated, standard recognition models. Identification performance results are given as confusion matrices and ROC curves for articulated objects, for configuration variants, and for a small change in depression angle.
Using SAR scattering center locations and magnitudes as features, invariances with articulation (i.e., turret rotation for the ZSU 23/4 gun and T72 tank), with configuration variants (e.g. fuel barrels, searchlights, etc.) and with a depression angle change are shown for real SAR images obtained from the MSTAR public data. This location and magnitude quasi-invariance forms a basis for an innovative SAR recognition engine that successfully identifies real articulated and non-standard configuration vehicles based on non-articulated, standard recognition models. Identification performance results are given as confusion matrices and ROC curves for articulated objects, for configuration variants, and for a small change in depression angle.
Bounding SAR ATR performance based on model similarity
.png) We analyze the effect of model similarity on the performance of a vote- based approach for target recognition from SAR images. In such an approach, each model target is represented by a set of SAR views sampled at a variety of azimuth angles and a specific depression angle. The model hypothesis corresponding to a given data view is chosen to be the one with the highest number of data-supported model features (votes). We address three issues in this paper. Firstly, we present a quantitative measure of the similarity between a pair of model views. Such a measure depends on the degree of structural overlap between the two views, and the amount of uncertainty. Secondly, we describe a similarity- based framework for predicting an upper bound on recognition performance in the presence of uncertainty, occlusion and clutter. Thirdly, we validate the proposed framework using MSTAR public data, which are obtained under different depression angles, configurations and articulations.
We analyze the effect of model similarity on the performance of a vote- based approach for target recognition from SAR images. In such an approach, each model target is represented by a set of SAR views sampled at a variety of azimuth angles and a specific depression angle. The model hypothesis corresponding to a given data view is chosen to be the one with the highest number of data-supported model features (votes). We address three issues in this paper. Firstly, we present a quantitative measure of the similarity between a pair of model views. Such a measure depends on the degree of structural overlap between the two views, and the amount of uncertainty. Secondly, we describe a similarity- based framework for predicting an upper bound on recognition performance in the presence of uncertainty, occlusion and clutter. Thirdly, we validate the proposed framework using MSTAR public data, which are obtained under different depression angles, configurations and articulations.
Recognizing MSTAR target variants and articulations
.png) The focus of this paper is recognizing articulated vehicles and actual vehicle configuration variants in real SAR images from the MSTAR public data. Using SAR scattering center locations and magnitudes as features, the invariance of these features is shown with articulation (i.e. turret rotation for the T72 tank and ZSU 23/4 gun), with configuration variants and with a small change in depression angle. This scatterer location and magnitude quasi-invariance (e.g. location within one pixel, magnitude within about ten percent in radar cross- section) is used as a basis for development of a SAR recognition engine that successfully identified real articulated and non-standard configuration vehicles based on non-articulated, standard recognition models. Identification performance results are presented as vote space scatter plots and ROC curves for configuration variants, for articulated objects and for a small change in depression angle with the MSTAR data.
The focus of this paper is recognizing articulated vehicles and actual vehicle configuration variants in real SAR images from the MSTAR public data. Using SAR scattering center locations and magnitudes as features, the invariance of these features is shown with articulation (i.e. turret rotation for the T72 tank and ZSU 23/4 gun), with configuration variants and with a small change in depression angle. This scatterer location and magnitude quasi-invariance (e.g. location within one pixel, magnitude within about ten percent in radar cross- section) is used as a basis for development of a SAR recognition engine that successfully identified real articulated and non-standard configuration vehicles based on non-articulated, standard recognition models. Identification performance results are presented as vote space scatter plots and ROC curves for configuration variants, for articulated objects and for a small change in depression angle with the MSTAR data.
A system for model-based recognition of articulated objects
.png) This paper presents a model-based matching technique for recognition of articulated objects (with two parts) and the poses of these parts in SAR (Synthetic Aperture Radar) images. Using articulation invariants as features, the recognition system first hypothesizes the pose of the larger part and then the pose of the smaller part. Geometric reasoning is carried out to correct identification errors. The thresholds for the quality of match are determined dynamically by minimizing the probability of a random match. Results are presented using SAR images of three articulated objects. The system performance is evaluated with respect to identification performance, accuracy of estimates for the poses of the object parts and noise.
This paper presents a model-based matching technique for recognition of articulated objects (with two parts) and the poses of these parts in SAR (Synthetic Aperture Radar) images. Using articulation invariants as features, the recognition system first hypothesizes the pose of the larger part and then the pose of the smaller part. Geometric reasoning is carried out to correct identification errors. The thresholds for the quality of match are determined dynamically by minimizing the probability of a random match. Results are presented using SAR images of three articulated objects. The system performance is evaluated with respect to identification performance, accuracy of estimates for the poses of the object parts and noise.
Recognizing articulated objects and object articulation in SAR images
.png) In this paper, we are concerned with the problem of recognizing articulated objects (with two parts) and the poses of the articulated parts. Previous work in this area has used simple models (like scissors and lamps) in visual imagery and has used constraints around a joint to recognize these objects. Because of the unique characteristics of SAR image formation (specular reflection, multiple bounces, low resolution and non-literal nature of the sensor), it is difficult to extract linear features (commonly used in visual images), especially in SAR images at six inch to a foot resolution.
In this paper, we are concerned with the problem of recognizing articulated objects (with two parts) and the poses of the articulated parts. Previous work in this area has used simple models (like scissors and lamps) in visual imagery and has used constraints around a joint to recognize these objects. Because of the unique characteristics of SAR image formation (specular reflection, multiple bounces, low resolution and non-literal nature of the sensor), it is difficult to extract linear features (commonly used in visual images), especially in SAR images at six inch to a foot resolution.
Model-Based Recognition of Articulated Objects
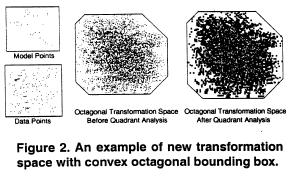 A model-based matching technique for recognition of articulated objects (with two parts) and the poses of these parts on SAR (Synthetic Aperture Radar) images is presented. Using articulation invariants as features, the recognition system first hypothesized the pose of the larger part and then the pose of the smaller part. Geometric reasoning was carried out to correct identification errors. The thresholds for the quality of match were determined dynamically by minimizing the probability of a random match. Results are presented using SAR images of three articulated objects. The system performance was evaluated with respect to identification performance, accuracy of estimates for the poses of the objects parts, and noise.
A model-based matching technique for recognition of articulated objects (with two parts) and the poses of these parts on SAR (Synthetic Aperture Radar) images is presented. Using articulation invariants as features, the recognition system first hypothesized the pose of the larger part and then the pose of the smaller part. Geometric reasoning was carried out to correct identification errors. The thresholds for the quality of match were determined dynamically by minimizing the probability of a random match. Results are presented using SAR images of three articulated objects. The system performance was evaluated with respect to identification performance, accuracy of estimates for the poses of the objects parts, and noise.
A System for Model-Based Object Recognition in Perspective Aerial Images
 Recognition of objects in complex, perspective aerial imagery was difficult because of occlusion, shadow, clutter and various forms of image degradation. A system for aircraft recognition under real-world conditions is presented. The approach was based on the use of a hierarchical database of object models and involved three key processes: the qualitative object recognition process performed heterogeneous model-based symbolic feature extraction and generic object recognition, the qualitative object recognition process performed heterogeneous model-based symbolic feature extraction and generic object recognition, and the primitive feature extraction process regulated the extracted features based on their saliency and interacted with the recognition and refining process.
Recognition of objects in complex, perspective aerial imagery was difficult because of occlusion, shadow, clutter and various forms of image degradation. A system for aircraft recognition under real-world conditions is presented. The approach was based on the use of a hierarchical database of object models and involved three key processes: the qualitative object recognition process performed heterogeneous model-based symbolic feature extraction and generic object recognition, the qualitative object recognition process performed heterogeneous model-based symbolic feature extraction and generic object recognition, and the primitive feature extraction process regulated the extracted features based on their saliency and interacted with the recognition and refining process.
Closed loop object recognition using reinforcement learning
.png) The system presented here achieves robust performance by using reinforcement learning to induce a mapping from input images to corresponding segmentation parameters. This is accomplished by using the confidence level of model matching as a reinforcement signal for a team of learning automata to search for segmentation parameters during training. The use of the recognition algorithm as part of the evaluation function for image segmentation gives rise to significant improvement of the system performance by automatic generation of recognition strategies. The system is verified through experiments on sequences of indoor and outdoor color images with varying external conditions.
The system presented here achieves robust performance by using reinforcement learning to induce a mapping from input images to corresponding segmentation parameters. This is accomplished by using the confidence level of model matching as a reinforcement signal for a team of learning automata to search for segmentation parameters during training. The use of the recognition algorithm as part of the evaluation function for image segmentation gives rise to significant improvement of the system performance by automatic generation of recognition strategies. The system is verified through experiments on sequences of indoor and outdoor color images with varying external conditions.
A System for Model-based Object Recognition in Perspective Aerial Images
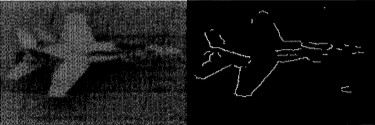 We present a system for aircraft recognition under
real-world conditions. The particular approach is based on the use of a hierarchical database of object models
and involves three key processes: (a) The qualitative object recognition process; (b) The refocused matching and
evaluation process; and (c)
The primitive feature extraction process .
Experimental results showing the qualitative recognition of aircraft in perspective, aerial images
are presented.
We present a system for aircraft recognition under
real-world conditions. The particular approach is based on the use of a hierarchical database of object models
and involves three key processes: (a) The qualitative object recognition process; (b) The refocused matching and
evaluation process; and (c)
The primitive feature extraction process .
Experimental results showing the qualitative recognition of aircraft in perspective, aerial images
are presented.
Bounding Fundamental Performance of Feature-Based Object Recognition
 Performance prediction was a crucial step for transforming the field of object recognition from an art to a science so we addressed this problem in the context of a vote-based approach for object recognition using 2D point features. A method is presented for predicting tight lower and upper bounds on fundamental performance of the selected recognition approach. Performance bounds were predicted by considering data-distortion factors, in addition to model structural similarity. Given a statistical model of data uncertainty, the structural similarity between every pair of model objects was computed as a function of the relative transformation between them. Model-similarity information was then used along with statistical data-distortion models to predict bounds on the probability of correct recognition.
Performance prediction was a crucial step for transforming the field of object recognition from an art to a science so we addressed this problem in the context of a vote-based approach for object recognition using 2D point features. A method is presented for predicting tight lower and upper bounds on fundamental performance of the selected recognition approach. Performance bounds were predicted by considering data-distortion factors, in addition to model structural similarity. Given a statistical model of data uncertainty, the structural similarity between every pair of model objects was computed as a function of the relative transformation between them. Model-similarity information was then used along with statistical data-distortion models to predict bounds on the probability of correct recognition.
Geometrical and Magnitude Invariants for Recognition of Articulated and Non-Standard Objects
 Using SAR scattering center locations and magnitudes as features, invariances with articulation (i.e. turret rotation for the T72 tank and ZSU 23/4 gun), with configurations variants (e.g. fuel barrels, searchlight, wire cables, etc.) and with a depression angle change was shown for real SAR images obtained from the MSTAR public data. This location and magnitude quasi-invariance was used as a basis for an innovative SAR recognition engine that successfully identified real articulated and non-standard configuration vehicles based on non-articulated, standard recognition models. Identification performance results are given as confusion matrices and ROC curves for articulated objects, for configuration variants, and for a small change in depression angle with the MSTAR data. The recognition rate is related to the percent of location and magnitude invariant scattering centers.
Using SAR scattering center locations and magnitudes as features, invariances with articulation (i.e. turret rotation for the T72 tank and ZSU 23/4 gun), with configurations variants (e.g. fuel barrels, searchlight, wire cables, etc.) and with a depression angle change was shown for real SAR images obtained from the MSTAR public data. This location and magnitude quasi-invariance was used as a basis for an innovative SAR recognition engine that successfully identified real articulated and non-standard configuration vehicles based on non-articulated, standard recognition models. Identification performance results are given as confusion matrices and ROC curves for articulated objects, for configuration variants, and for a small change in depression angle with the MSTAR data. The recognition rate is related to the percent of location and magnitude invariant scattering centers.
Interactive Target Recognition using a Database-Retrieval Oriented Approach
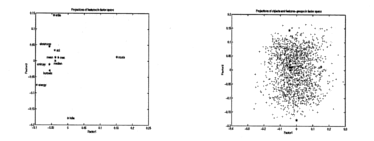 Recognition of Objects when the number of model objects becomes large was a challenging problem which made it increasingly difficult to view the object recognition problem as a “find the best match” problem. A database-retrieval oriented approach where the goal was to index, retrieve, rank, and output a few top-ranked models, according to their similarity with an input query object is presented. The approach consisted of three stages: feature-based representation of model objects and object-feature correspondence analysis, clustering and indexing of the model objects in the factor space, and ranking indexed models based on mutual information with query object. The approach was suitable for semi-automatic object recognition tasks which involved human interaction.
Recognition of Objects when the number of model objects becomes large was a challenging problem which made it increasingly difficult to view the object recognition problem as a “find the best match” problem. A database-retrieval oriented approach where the goal was to index, retrieve, rank, and output a few top-ranked models, according to their similarity with an input query object is presented. The approach consisted of three stages: feature-based representation of model objects and object-feature correspondence analysis, clustering and indexing of the model objects in the factor space, and ranking indexed models based on mutual information with query object. The approach was suitable for semi-automatic object recognition tasks which involved human interaction.
Performance Modeling of Feature-Based Classification in SAR Imagery
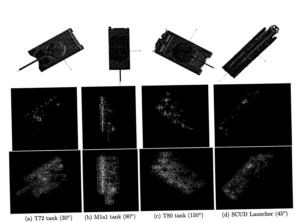 A method for modeling the performance of a vote-based approach for target classifications in SAR imagery is presented. In this approach, the geometric locations of the scattering centers was used to represent 2D model views of a 3D target for a specific sensor under a given viewing condition (azimuth, depression, and squint angles) and performance of such an approach was modeled in the presence of data uncertainty, occlusion, and clutter. The proposed method captured the structural similarity between model views, which played an important role in determining the classification performance and in particular, performance would improve if the model views were dissimilar and vice versa. The method consisted of the following steps: in the first step given a bound on data uncertainty, model similarity was determined by finding feature correspondence in the space of relative translations between each pair of model views, in the second step, statistical analysis was carried out in the vote , occlusion and clutter space, in order to determine the probability of misclassifying each model view, and finally in the third step, the misclassification probability was averaged for all model views to estimate the probability-of-correct-identification (PCI) plot as a function of occlusion and clutter rates. Validity of the method was demonstrated by comparing predicted PCI plots with ones that were obtained experimentally.
A method for modeling the performance of a vote-based approach for target classifications in SAR imagery is presented. In this approach, the geometric locations of the scattering centers was used to represent 2D model views of a 3D target for a specific sensor under a given viewing condition (azimuth, depression, and squint angles) and performance of such an approach was modeled in the presence of data uncertainty, occlusion, and clutter. The proposed method captured the structural similarity between model views, which played an important role in determining the classification performance and in particular, performance would improve if the model views were dissimilar and vice versa. The method consisted of the following steps: in the first step given a bound on data uncertainty, model similarity was determined by finding feature correspondence in the space of relative translations between each pair of model views, in the second step, statistical analysis was carried out in the vote , occlusion and clutter space, in order to determine the probability of misclassifying each model view, and finally in the third step, the misclassification probability was averaged for all model views to estimate the probability-of-correct-identification (PCI) plot as a function of occlusion and clutter rates. Validity of the method was demonstrated by comparing predicted PCI plots with ones that were obtained experimentally.
Predicting Object Recognition Performance under Data Uncertainty, Occlusion, and Clutter
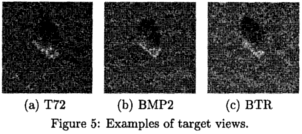 A method for predicting the performance of an object recognition approach in the presence of data uncertainty, occlusion and clutter is presented. The recognition approach used a vote-based decision criterion, which selected the object/pose hypotheses that had the maximum number of consistent features (votes) with the scene data. The prediction method determined a fundamental, optimistic, limit on achievable performance by any vote-based recognition system. It captured the structural similarity between model objects, which was a fundamental factor in determining the recognition performance. Given a bound on data uncertainty, we determined the structural similarity between every pair of model objects. This was done by computing the number of consistent features between the two objects as a function of the relative transformation between them. Similarity information was then used, along with statistical models for data distortion, to estimate the probability of correct recognition (PCR) as a function of occlusion and clutter rates.
A method for predicting the performance of an object recognition approach in the presence of data uncertainty, occlusion and clutter is presented. The recognition approach used a vote-based decision criterion, which selected the object/pose hypotheses that had the maximum number of consistent features (votes) with the scene data. The prediction method determined a fundamental, optimistic, limit on achievable performance by any vote-based recognition system. It captured the structural similarity between model objects, which was a fundamental factor in determining the recognition performance. Given a bound on data uncertainty, we determined the structural similarity between every pair of model objects. This was done by computing the number of consistent features between the two objects as a function of the relative transformation between them. Similarity information was then used, along with statistical models for data distortion, to estimate the probability of correct recognition (PCR) as a function of occlusion and clutter rates.
Target Recognition for Articulated and Occluded Objects in Synthetic Aperture Radar Imagery
 Recognition of articulated occluded real-world man-made objects in Synthetic Aperture Radar (SAR) imagery had not been addressed in the field of image processing and computer vision. The traditional approach to object recognition in SAR imagery (at one foot or worse resolution) typically involved template matching methods, which were not suited for these cases because articulation or occlusion changed global features like the object outline and major axis. The performance of a model-based automatic target recognition (ATR) engine with articulated and occluded objects in SAR imagery was characterized based on invariant properties of the objects. Although the approach was related to geometric hashing, it was a novel approach for recognizing objects in SAR images. The novelty and power of the approach came from a combination of a SAR specific method for recognition, taking into account azimuthal variation, articulation invariants and sensor resolution.
Recognition of articulated occluded real-world man-made objects in Synthetic Aperture Radar (SAR) imagery had not been addressed in the field of image processing and computer vision. The traditional approach to object recognition in SAR imagery (at one foot or worse resolution) typically involved template matching methods, which were not suited for these cases because articulation or occlusion changed global features like the object outline and major axis. The performance of a model-based automatic target recognition (ATR) engine with articulated and occluded objects in SAR imagery was characterized based on invariant properties of the objects. Although the approach was related to geometric hashing, it was a novel approach for recognizing objects in SAR images. The novelty and power of the approach came from a combination of a SAR specific method for recognition, taking into account azimuthal variation, articulation invariants and sensor resolution.
Invariants for the recognition of articulated and occluded objects in SAR images
.png) A model-based automatic target recognition (ATR) system is developed to recognize articulated and occluded objects in Synthetic Aperture Radar (SAR) images, based on invariant features of the objects. Characteristics of SAR target image scattering centers, azimuth variation, and articulation invariants are presented. The basic elements of the new recognition system are described and performance results are given for articulated, occluded and occluded articulated objects and they are related to the target articulation invariance and percent unoccluded.
A model-based automatic target recognition (ATR) system is developed to recognize articulated and occluded objects in Synthetic Aperture Radar (SAR) images, based on invariant features of the objects. Characteristics of SAR target image scattering centers, azimuth variation, and articulation invariants are presented. The basic elements of the new recognition system are described and performance results are given for articulated, occluded and occluded articulated objects and they are related to the target articulation invariance and percent unoccluded.
Gabor Wavelet Representation for 3D Object Recognition
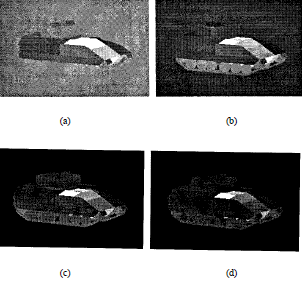 A model-based object recognition approach that used a Gabor wavelet representation is presented. The focus was to use magnitude, phase, and frequency measures of the Gabor wavelet representation in an innovative flexible matching approach that provided robust recognition. The Gabor grid, a topology-preserving map, efficiently encoded both signal energy and structural information of an object in a sparse multiresolution representation. The Gabor grid subsampled the Gabor wavelet decomposition of an object model and deformed to allow the indexed object model to match with similar representation obtained using image data. Flexible matching between the model and the image minimized a cost function based on local similarity and geometric distortion of the Gabor grid. Grid erosion and repairing was performed whenever a collapsed grid, due to object occlusion, was detected and the results on infrared imagery are presented, where objects underwent rotation, translation, scale, occlusion, and aspect variations under changing environmental conditions.
A model-based object recognition approach that used a Gabor wavelet representation is presented. The focus was to use magnitude, phase, and frequency measures of the Gabor wavelet representation in an innovative flexible matching approach that provided robust recognition. The Gabor grid, a topology-preserving map, efficiently encoded both signal energy and structural information of an object in a sparse multiresolution representation. The Gabor grid subsampled the Gabor wavelet decomposition of an object model and deformed to allow the indexed object model to match with similar representation obtained using image data. Flexible matching between the model and the image minimized a cost function based on local similarity and geometric distortion of the Gabor grid. Grid erosion and repairing was performed whenever a collapsed grid, due to object occlusion, was detected and the results on infrared imagery are presented, where objects underwent rotation, translation, scale, occlusion, and aspect variations under changing environmental conditions.
Stochastic Models for Recognition of Articulated Objects
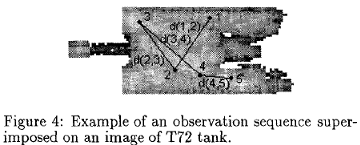 A hidden Markov modeling (HMM) based approach for recognition of articulated objects in synthetic aperture radar (SAR) images is presented. We developed multiple models for a given SAR image of an object and integrated these models synergistically using their probabilistic estimates for recognition and estimates of invariance of features as a result of articulation. The models were based on sequentialization of scattering centers extracted from SAR images. Experimental results are presented using 1440 training images and 2520 testing images for 4 classes.
A hidden Markov modeling (HMM) based approach for recognition of articulated objects in synthetic aperture radar (SAR) images is presented. We developed multiple models for a given SAR image of an object and integrated these models synergistically using their probabilistic estimates for recognition and estimates of invariance of features as a result of articulation. The models were based on sequentialization of scattering centers extracted from SAR images. Experimental results are presented using 1440 training images and 2520 testing images for 4 classes.
Target indexing in SAR images using scattering centers and the Hausdorff distance
 A method is presented with a concern for efficient and accurate indexing for target recognition in SAR images. The solution was a method that efficiently retrieved correct object hypotheses using the major axis of a pattern of scattering centers in SAR images and the Hausdorff distance measure. The features that were used are the locations of scattering centers in SAR returns. Experimental results showed that indexing using major axis efficiently narrows down the number of candidate hypotheses and that the Hausdorff distance measure performed well in picking the correct hypothesis. These properties of the algorithm along with computational efficiency made the method a promising approach to target indexing in SAR images.
A method is presented with a concern for efficient and accurate indexing for target recognition in SAR images. The solution was a method that efficiently retrieved correct object hypotheses using the major axis of a pattern of scattering centers in SAR images and the Hausdorff distance measure. The features that were used are the locations of scattering centers in SAR returns. Experimental results showed that indexing using major axis efficiently narrows down the number of candidate hypotheses and that the Hausdorff distance measure performed well in picking the correct hypothesis. These properties of the algorithm along with computational efficiency made the method a promising approach to target indexing in SAR images.
Generic Object Recognition using Multiple Representations
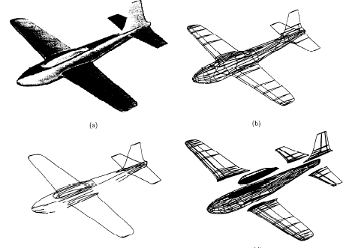 Real-world image understanding tasks often involved complex object models which were not adequately represented by a single representational scheme for the various recognition scenarios encountered in practice. Multiple representations, on the other hand, allowed different matching strategies to be applied for the same object, or even for different parts of the same object. A concern with the derivation of hierarchical CAD models having multiple representations - concave/convex edges and straight homogeneous generalized cylinder - and their use for generic object recognition in outdoor visible imagery is presented. It also presents a refocused matching algorithm that used a hierarchically structured model database to facilitate generic object recognition.
Real-world image understanding tasks often involved complex object models which were not adequately represented by a single representational scheme for the various recognition scenarios encountered in practice. Multiple representations, on the other hand, allowed different matching strategies to be applied for the same object, or even for different parts of the same object. A concern with the derivation of hierarchical CAD models having multiple representations - concave/convex edges and straight homogeneous generalized cylinder - and their use for generic object recognition in outdoor visible imagery is presented. It also presents a refocused matching algorithm that used a hierarchically structured model database to facilitate generic object recognition.
Adaptive Object Detection From Multi-Sensor Data
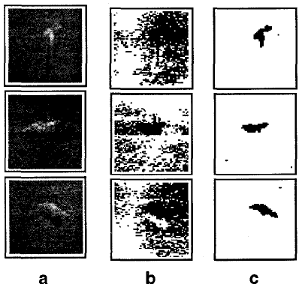 Two general methodologies for developing self-adapting automatic object detection systems to achieve robust performance are introduced. They were based on optimization of parameters of an algorithm and adaptation of the input to an algorithm. Different modified Hebbian learning rules were used to build adaptive feature extractors which transformed the input data into a desired form for a given object detection algorithm. To show its feasibility, input adaptors for object detection were designed and tested using multi-sensor data including SAR, FLIR, and color images.
Two general methodologies for developing self-adapting automatic object detection systems to achieve robust performance are introduced. They were based on optimization of parameters of an algorithm and adaptation of the input to an algorithm. Different modified Hebbian learning rules were used to build adaptive feature extractors which transformed the input data into a desired form for a given object detection algorithm. To show its feasibility, input adaptors for object detection were designed and tested using multi-sensor data including SAR, FLIR, and color images.
Automatic Model Construction for Object Recognition Using ISAR Images
 A learning-from-examples approach was used to construct recognition models of the objects from their ISAR data. Given a set of ISAR data of an object of interest, structural features were extracted from the images. Statistical analysis and geometrical reasoning were then used to analyze the features to find spatial and statistical invariance so that a structural model of the object suitable for object recognition could be constructed. Results of experiments using the automatically constructed models in object recognition are presented.
A learning-from-examples approach was used to construct recognition models of the objects from their ISAR data. Given a set of ISAR data of an object of interest, structural features were extracted from the images. Statistical analysis and geometrical reasoning were then used to analyze the features to find spatial and statistical invariance so that a structural model of the object suitable for object recognition could be constructed. Results of experiments using the automatically constructed models in object recognition are presented.
Modeling Clutter and Context for Target Detection in Infrared Images
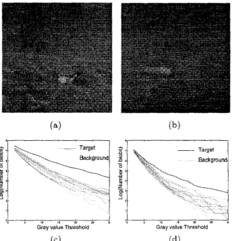 In order to reduce false alarms and to improve the target detection performance of an automatic target detection and recognition system operating in a cluttered environment, it was important to develop the models not only for man-made targets but also of natural background clutters. Because of the high complexity of natural clutters, this clutter model could only be reliably built through learning from real examples. If available, contextual information that characterizes each training example could be used to further improve the learned clutter model. We present such a clutter model aided target detection system. Emphasis was placed on two topics: learning the background clutter model from sensory data through a self-organizing process and reinforcing the learned clutter model using contextual information.
In order to reduce false alarms and to improve the target detection performance of an automatic target detection and recognition system operating in a cluttered environment, it was important to develop the models not only for man-made targets but also of natural background clutters. Because of the high complexity of natural clutters, this clutter model could only be reliably built through learning from real examples. If available, contextual information that characterizes each training example could be used to further improve the learned clutter model. We present such a clutter model aided target detection system. Emphasis was placed on two topics: learning the background clutter model from sensory data through a self-organizing process and reinforcing the learned clutter model using contextual information.
Composite Phase and Phase-Based Gabor Element Aggregation
 The phase, obtained by Gabor filtering an image, could be used to aggregate related Gabor elements (simple features identified by peaks in the Gabor magnitude). This phase-based feature grouping simplified the perennial problem of target/background segmentation because we only needed to determine if the aggregate feature was target or background, rather than determining the status of each feature independently. Since the phase from a single quadrature Gabor output could not tolerate large changes in orientation, a new local measure, which was referred to as the composite phase, was developed. It was a combination of the filter responses from multiple orientations which allowed the phase to follow contours with large changes in orientation. A constant composite phase contour was used to connect related Gabor elements that would otherwise appear separated within the magnitude response.
The phase, obtained by Gabor filtering an image, could be used to aggregate related Gabor elements (simple features identified by peaks in the Gabor magnitude). This phase-based feature grouping simplified the perennial problem of target/background segmentation because we only needed to determine if the aggregate feature was target or background, rather than determining the status of each feature independently. Since the phase from a single quadrature Gabor output could not tolerate large changes in orientation, a new local measure, which was referred to as the composite phase, was developed. It was a combination of the filter responses from multiple orientations which allowed the phase to follow contours with large changes in orientation. A constant composite phase contour was used to connect related Gabor elements that would otherwise appear separated within the magnitude response.
Error Bound for Multi-Stage Synthesis of Narrow Bandwidth Gabor Filters
 A study that developed an error bound for narrow bandwidth Gabor filters synthesized using multiple stages is presented. It is shown that the error introduced by approximating narrow bandwidth Gabor kernels by a weighted sum of spatially offset, separable kernels was a function of the frequency offset and the reduction in bandwidth of the desired kernel compared to the basis values, as well as the spatial subsampling rate between filter stages. This error bound was expected to prove useful in the design of a general basis filter set for multi-stage filtering because the maximum frequency offset was largely determined by the spacing of the basis filters.
A study that developed an error bound for narrow bandwidth Gabor filters synthesized using multiple stages is presented. It is shown that the error introduced by approximating narrow bandwidth Gabor kernels by a weighted sum of spatially offset, separable kernels was a function of the frequency offset and the reduction in bandwidth of the desired kernel compared to the basis values, as well as the spatial subsampling rate between filter stages. This error bound was expected to prove useful in the design of a general basis filter set for multi-stage filtering because the maximum frequency offset was largely determined by the spacing of the basis filters.
Gabor Wavelets for 3-D Object Recognition
 A model-based object recognition approach that used a hierarchical Gabor wavelet representation is presented. The key idea was to use magnitude, phase and frequency measures of Gabor wavelet representation in an innovative flexible matching approach that was able to provide robust recognition. A Gabor grid, a topology-preserving map, efficiently encoded both signal energy and structural information of an object in a sparse multi-resolution representation and the Gabor grid subsampled the Gabor wavelet decomposition of an object model and was deformed to allow the indexed object model match with the image data. Flexible matching between the model and the image minimized a cost function based on local similarity and geometric distortion of the Gabor grid. Grid erosion and repairing was performed whenever a collapsed grid, due to object occlusion, was detected. The results on infrared imagery are presented, where objects underwent rotation, translation, scale, occlusion and aspect variations under changing environmental conditions.
A model-based object recognition approach that used a hierarchical Gabor wavelet representation is presented. The key idea was to use magnitude, phase and frequency measures of Gabor wavelet representation in an innovative flexible matching approach that was able to provide robust recognition. A Gabor grid, a topology-preserving map, efficiently encoded both signal energy and structural information of an object in a sparse multi-resolution representation and the Gabor grid subsampled the Gabor wavelet decomposition of an object model and was deformed to allow the indexed object model match with the image data. Flexible matching between the model and the image minimized a cost function based on local similarity and geometric distortion of the Gabor grid. Grid erosion and repairing was performed whenever a collapsed grid, due to object occlusion, was detected. The results on infrared imagery are presented, where objects underwent rotation, translation, scale, occlusion and aspect variations under changing environmental conditions.
A System for Aircraft Recognition in Perspective Aerial Images
 Recognition of aircraft in complex, perspective aerial imagery had to be accomplished in presence of clutter, occlusion, shadow, and various forms of image degradation. A system for aircraft recognition under real-world conditions that was based on the use of a hierarchical database of object models is presented. This particular approach involved three key processes: (a) The qualitative object recognition process performed model-based symbolic feature extraction and generic object recognition; (b) The refocused matching and evaluation process refined the extracted features for more specific classification with input from (a); and (c) The primitive feature extraction process regulated the extracted features based on their saliency and interacted with (a) and (b). Experimental results showing the qualitative recognition of aircraft in perspective, aerial images are presented.
Recognition of aircraft in complex, perspective aerial imagery had to be accomplished in presence of clutter, occlusion, shadow, and various forms of image degradation. A system for aircraft recognition under real-world conditions that was based on the use of a hierarchical database of object models is presented. This particular approach involved three key processes: (a) The qualitative object recognition process performed model-based symbolic feature extraction and generic object recognition; (b) The refocused matching and evaluation process refined the extracted features for more specific classification with input from (a); and (c) The primitive feature extraction process regulated the extracted features based on their saliency and interacted with (a) and (b). Experimental results showing the qualitative recognition of aircraft in perspective, aerial images are presented.
Background Modeling for Target Detection and Recognition
 In order to reduce false alarms and to improve the detection and recognition performance in cluttered environments, it was important to develop not only the models for man-made targets but also the models of natural backgrounds. A learning based approach to construct and to maintain a concise and accurate background model bank by learning from positive and negative examples is presented. Features used to characterize the natural backgrounds included joint space-frequency features based on the Gabor transform, and localized statistics of geometric elements. An open-structure representation was used to manage the background modeling process so that it was easy to include new sensors, new features, and other contextual information.
In order to reduce false alarms and to improve the detection and recognition performance in cluttered environments, it was important to develop not only the models for man-made targets but also the models of natural backgrounds. A learning based approach to construct and to maintain a concise and accurate background model bank by learning from positive and negative examples is presented. Features used to characterize the natural backgrounds included joint space-frequency features based on the Gabor transform, and localized statistics of geometric elements. An open-structure representation was used to manage the background modeling process so that it was easy to include new sensors, new features, and other contextual information.
Generic Object Recognition Using CAD-Based Multiple Representations
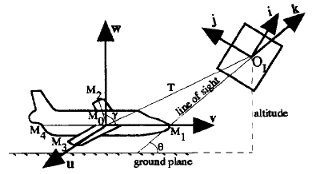 Real-world applications of computer vision usually involves a variety of object models making a single model representation somewhat inadequate for object recognition. Multiple representations, on the other hand, allow different matching strategies to be applied for the same object, or even for different parts of the same object. Our concern was the use of CAD-derived hierarchical models having multiple representations - concave/convex edges and straight homogeneous generalized cylinder - for generic object recognition in outdoor visible imagery. It also presents a refocused matching algorithm that used a hierarchically structured model database to facilitate generic object recognition.
Real-world applications of computer vision usually involves a variety of object models making a single model representation somewhat inadequate for object recognition. Multiple representations, on the other hand, allow different matching strategies to be applied for the same object, or even for different parts of the same object. Our concern was the use of CAD-derived hierarchical models having multiple representations - concave/convex edges and straight homogeneous generalized cylinder - for generic object recognition in outdoor visible imagery. It also presents a refocused matching algorithm that used a hierarchically structured model database to facilitate generic object recognition.
Hierarchical Gabor Filters for Object Detection in Infrared Images
 A new representation called “Hierarchical Gabor Filters” and associated local measures which were used to detect potential objects of interest in images is presented. The “first stage” of the approach used a wavelet set of wide-bandwidth separable Gabor filters to extract local measures from an image. The “second stage made certain spatial groupings explicit by creating small-bandwidth, non-separable Gabor filters that were tuned to elongated contours or periodic patterns. The non-separable filter responses were obtained from a weighted combination of the separable basis filters, which preserved the computational efficiency of separable filters while providing the distinctiveness required to discriminate objects from clutter.
A new representation called “Hierarchical Gabor Filters” and associated local measures which were used to detect potential objects of interest in images is presented. The “first stage” of the approach used a wavelet set of wide-bandwidth separable Gabor filters to extract local measures from an image. The “second stage made certain spatial groupings explicit by creating small-bandwidth, non-separable Gabor filters that were tuned to elongated contours or periodic patterns. The non-separable filter responses were obtained from a weighted combination of the separable basis filters, which preserved the computational efficiency of separable filters while providing the distinctiveness required to discriminate objects from clutter.
Image Understanding for Automatic Target Recognition
 Automatic Target Recognition (ATR) was an extremely important capability for defense applications. Many aspects of Image Understanding (IU) research were traditionally used to solve ATR problems. ATR applications and problems in developing real-world ATR systems, and the status of technology for these systems are presented. We identified several IU problems that needed to be resolved in order to enhance the effectiveness of ATR-based weapon systems. Technological gains in developing robust ATR systems were shown to lead to significant advances in many other areas of applications of image understanding.
Automatic Target Recognition (ATR) was an extremely important capability for defense applications. Many aspects of Image Understanding (IU) research were traditionally used to solve ATR problems. ATR applications and problems in developing real-world ATR systems, and the status of technology for these systems are presented. We identified several IU problems that needed to be resolved in order to enhance the effectiveness of ATR-based weapon systems. Technological gains in developing robust ATR systems were shown to lead to significant advances in many other areas of applications of image understanding.
Recognition of Occluded Objects: A Cluster-Structure Algorithm
 We applied clustering methods to a new problem domain and presented a new method based on a cluster-structure approach for the recognition of 2-D partially occluded objects. Basically, the technique consisted of three steps: clustering of border segment transformations; finding continuous sequences of segments in appropriately chosen clusters; and clustering of sequence average transformation values. As compared to some of the earlier methods, which identified an object based on only one sequence of matched segments, the newer approach allowed for the identification of all parts of the model which matched in the occluded scene. We also discuss the application of the clustering techniques to 3D scene analysis. In both cases, the cluster-structure algorithm entailed the application of clustering concepts in a hierarchical manner, resulting in a decrease in the computational effort as the recognition algorithm progressed. The implementation of the techniques discussed for the 2-D case was completed and the algorithm was evaluated with respect to a large number of examples where several objects partially occluded one another. The method was able to tolerate a moderate change in scale and a significant amount of shape distortion arising as a result of segmentation and/or the polygonal approximation of the boundary of the object.
We applied clustering methods to a new problem domain and presented a new method based on a cluster-structure approach for the recognition of 2-D partially occluded objects. Basically, the technique consisted of three steps: clustering of border segment transformations; finding continuous sequences of segments in appropriately chosen clusters; and clustering of sequence average transformation values. As compared to some of the earlier methods, which identified an object based on only one sequence of matched segments, the newer approach allowed for the identification of all parts of the model which matched in the occluded scene. We also discuss the application of the clustering techniques to 3D scene analysis. In both cases, the cluster-structure algorithm entailed the application of clustering concepts in a hierarchical manner, resulting in a decrease in the computational effort as the recognition algorithm progressed. The implementation of the techniques discussed for the 2-D case was completed and the algorithm was evaluated with respect to a large number of examples where several objects partially occluded one another. The method was able to tolerate a moderate change in scale and a significant amount of shape distortion arising as a result of segmentation and/or the polygonal approximation of the boundary of the object.
Knowledge-Based Robust Target Recognition & Tracking
In the Honeywell Strategic Computing Computer Vision Program, we worked on demonstrating knowledge-based robust target recognition and tracking technology.The focus of our work was to use artificial intelligence techniques in computer vision, spatial-reasoning, temporal reasoning, incorporation of a priori, and contextual and multisensory information for dynamic scene understanding. The topics under investigation were: landmark and target recognition using multi-source a priori information, robust target motion detection and tracking using qualitative reasoning, and interpretation of terrain using symbolic grouping. An integrated system concept for these topics is presented, along with results on real imagery. Practical applications of work involve vision controlled navigation/guidance of the autonomous land vehicle, reconnaissance, surveillance, photo-interpretation, and other military applications such as search and rescue and targeting missions.
Automatic Target Recognition: State of the Art Survey
 A review of the techniques used to solve the automatic target recognition (ATR) problem is given. Emphasis is placed on algorithmic and implementation approaches. ATR algorithms such as target detection, segmentation, feature computation, classification, etc. are evaluated and several new quantitative criteria are presented. Evaluation approaches are discussed and various problems encountered in the evaluation of algorithms are addressed. Techniques such as the use of contextual cues, semantic and structural information, hierarchical reasoning in the classification and incorporation of multi-sensors in ATR systems are also presented.
A review of the techniques used to solve the automatic target recognition (ATR) problem is given. Emphasis is placed on algorithmic and implementation approaches. ATR algorithms such as target detection, segmentation, feature computation, classification, etc. are evaluated and several new quantitative criteria are presented. Evaluation approaches are discussed and various problems encountered in the evaluation of algorithms are addressed. Techniques such as the use of contextual cues, semantic and structural information, hierarchical reasoning in the classification and incorporation of multi-sensors in ATR systems are also presented.
Clustering Based Recognition of Occluded Objects
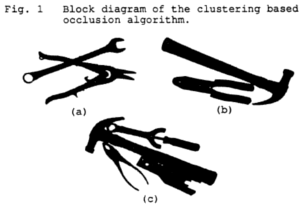 Clustering techniques have been used to perform image segmentation, to detect lines and curves in the images and to solve several other problems in pattern recognition and image analysis. We applied clustering methods to a problem domain and present a method based on a cluster-structure paradigm for the recognition of 2D partially occluded objects and also discuss the application of the clustering techniques to 3D object recognition. In both cases, the cluster-structure paradigm entails the application of clustering concepts in a hierarchical manner. The amount of computational effort decreased as the recognition algorithm progressed. The implementation of the technique discussed for the 2D case was completed and evaluated with respect to a large number of examples where several objects partially occluded one another. The method was able to tolerate a moderate change in scale and a significant amount of shape distortion arising as a result of segmentation and/or the polygonal approximation of the boundary of the object.
Clustering techniques have been used to perform image segmentation, to detect lines and curves in the images and to solve several other problems in pattern recognition and image analysis. We applied clustering methods to a problem domain and present a method based on a cluster-structure paradigm for the recognition of 2D partially occluded objects and also discuss the application of the clustering techniques to 3D object recognition. In both cases, the cluster-structure paradigm entails the application of clustering concepts in a hierarchical manner. The amount of computational effort decreased as the recognition algorithm progressed. The implementation of the technique discussed for the 2D case was completed and evaluated with respect to a large number of examples where several objects partially occluded one another. The method was able to tolerate a moderate change in scale and a significant amount of shape distortion arising as a result of segmentation and/or the polygonal approximation of the boundary of the object.
Recognition of Occluded Objects: A Cluster Structure Paradigm
 Clustering techniques have been used to perform image segmentation, to detect lines and curves in the images and to solve several other problems in pattern recognition and image analysis. Here we applied clustering methods to a problem domain and present a new method based on a cluster-structure paradigm for the recognition of 2-D partially occluded objects. The cluster structure paradigm entailed the application of clustering concepts in a hierarchical manner. The amount of computational effort decreased as the recognition algorithm progresses. As compared to some of the earlier methods, which identify an object based on only one sequence of matched segments, this technique allows for the identification of all parts of the model which match with the apparent object. Also the method was able to tolerate a moderate change in scale and a significant amount of shape distortion arising as a result of segmentation and/or the polygonal approximation of the boundary of the object.
Clustering techniques have been used to perform image segmentation, to detect lines and curves in the images and to solve several other problems in pattern recognition and image analysis. Here we applied clustering methods to a problem domain and present a new method based on a cluster-structure paradigm for the recognition of 2-D partially occluded objects. The cluster structure paradigm entailed the application of clustering concepts in a hierarchical manner. The amount of computational effort decreased as the recognition algorithm progresses. As compared to some of the earlier methods, which identify an object based on only one sequence of matched segments, this technique allows for the identification of all parts of the model which match with the apparent object. Also the method was able to tolerate a moderate change in scale and a significant amount of shape distortion arising as a result of segmentation and/or the polygonal approximation of the boundary of the object.
Shape Matching of Two-Dimensional Objects
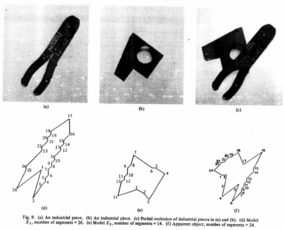 Results in the areas of shape matching of non-occluded and occluded two-dimensional objects are presented. This technique was based on a stochastic labeling procedure which explicitly maximized a criterion function based on the ambiguity and inconsistency of classification. To reduce the computation time, the technique was hierarchical and used results obtained at low levels to speed up and improve the accuracy of results at higher levels. This basic technique was extended to the situation where various objects partially occluded each other to form an apparent object and our interest was to find all the objects participating in the occlusion. In such a case several hierarchical processes were executed in parallel for every object participating in the occlusion and were coordinated in such a way that the same segment of the apparent object was not matched to the segments of different actual objects. These techniques were applied to two-dimensional simple closed curves represented by polygons and the power of the techniques was demonstrated by the examples taken from synthetic, aerial, industrial, and biological images where the matching was done after using the actual segmentation methods.
Results in the areas of shape matching of non-occluded and occluded two-dimensional objects are presented. This technique was based on a stochastic labeling procedure which explicitly maximized a criterion function based on the ambiguity and inconsistency of classification. To reduce the computation time, the technique was hierarchical and used results obtained at low levels to speed up and improve the accuracy of results at higher levels. This basic technique was extended to the situation where various objects partially occluded each other to form an apparent object and our interest was to find all the objects participating in the occlusion. In such a case several hierarchical processes were executed in parallel for every object participating in the occlusion and were coordinated in such a way that the same segment of the apparent object was not matched to the segments of different actual objects. These techniques were applied to two-dimensional simple closed curves represented by polygons and the power of the techniques was demonstrated by the examples taken from synthetic, aerial, industrial, and biological images where the matching was done after using the actual segmentation methods.
Evaluation of Automatic Target Recognition Algorithms
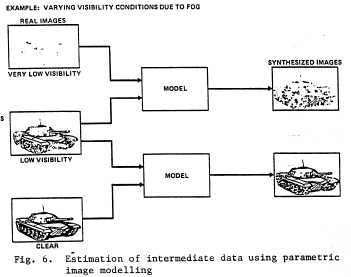 We briefly review the techniques used to solve the automatic target recognition (ATR) problem. Emphasis is placed on the algorithmic and implementation approaches. The evaluation of ATR algorithms such as target detection, segmentation, feature evaluation, and classification are discussed in detail and several quantitative criteria are suggested. The evaluation approach is discussed and various problems encountered in the evaluation of algorithms are addressed. Strategies used in the database design are outlined. Techniques such as the use of semantic and structural information, hierarchical reasoning in the classification, and incorporation of multi-sensor in the ATR systems are also presented.
We briefly review the techniques used to solve the automatic target recognition (ATR) problem. Emphasis is placed on the algorithmic and implementation approaches. The evaluation of ATR algorithms such as target detection, segmentation, feature evaluation, and classification are discussed in detail and several quantitative criteria are suggested. The evaluation approach is discussed and various problems encountered in the evaluation of algorithms are addressed. Strategies used in the database design are outlined. Techniques such as the use of semantic and structural information, hierarchical reasoning in the classification, and incorporation of multi-sensor in the ATR systems are also presented.
Intelligent Auto-Cueing of Tactical Targets in FLIR Images
 Algorithms used to automatically detect segment and classify tactical targets in FLIR (Forward Looking InfraRed) images are presented. The results are shown on a FLIR database consisting of 480, 512x512, 8 bit air-to-ground images.
Algorithms used to automatically detect segment and classify tactical targets in FLIR (Forward Looking InfraRed) images are presented. The results are shown on a FLIR database consisting of 480, 512x512, 8 bit air-to-ground images.
Recognition of Occluded Objects
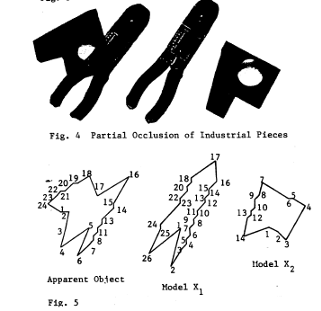 Matching of occluded objects was one of the prime capabilities of any computer vision system. A hierarchical stochastic labeling technique that did shape matching of 2D occluded objects is presented. The technique explicitly maximized a criterion function based on the ambiguity and inconsistency of classification. The 2D shapes were represented by their polygonal approximation. For each of the objects that participated in the occlusion, there was a hierarchical process. These processes were executed in parallel and were coordinated in such a way that the same segment of the apparent object, formed as a result of occlusion of two or more actual objects, was not matched to the segments of different actual objects.
Matching of occluded objects was one of the prime capabilities of any computer vision system. A hierarchical stochastic labeling technique that did shape matching of 2D occluded objects is presented. The technique explicitly maximized a criterion function based on the ambiguity and inconsistency of classification. The 2D shapes were represented by their polygonal approximation. For each of the objects that participated in the occlusion, there was a hierarchical process. These processes were executed in parallel and were coordinated in such a way that the same segment of the apparent object, formed as a result of occlusion of two or more actual objects, was not matched to the segments of different actual objects.
Shape Matching of 2D Objects Using a Hierarchical Stochastic Labeling Technique
 A stochastic labeling technique to do shape matching of non-occluded and occluded 2D objects is presented. The technique explicitly maximized a criterion function based on the ambiguity and inconsistency of classification. The technique was hierarchical and used results obtained at low levels to speed up and improve the accuracy of results at higher levels. This basic technique had been extended to the situation when various objects partially occlude. In such a case several hierarchical processes were executed in the occlusion and were coordinated in such a way that the same segment of the apparent object was not matched to the segments of different actual objects.
A stochastic labeling technique to do shape matching of non-occluded and occluded 2D objects is presented. The technique explicitly maximized a criterion function based on the ambiguity and inconsistency of classification. The technique was hierarchical and used results obtained at low levels to speed up and improve the accuracy of results at higher levels. This basic technique had been extended to the situation when various objects partially occlude. In such a case several hierarchical processes were executed in the occlusion and were coordinated in such a way that the same segment of the apparent object was not matched to the segments of different actual objects.
Shape Matching of Two-Dimensional Occluded Objects
 A hierarchical stochastic labeling technique to do shape matching of 2D occluded objects is presented. The technique explicitly maximized a criterion function based on the ambiguity and inconsistency of classification and the hierarchical nature of the algorithm reduced the computation time and used results obtained at low levels to speed up and improve accuracy of results at higher levels. The 2D shapes were represented by their polygonal approximation. For each of the objects participating in the occlusion, there was a hierarchical process. These processes were executed in parallel and were coordinated in such a way that the same segment of the apparent object, formed as a result of occlusion of two or more actual objects, was not matched to the segments of different actual objects. This problem was solved by combining the gradient projection method and penalty function approach. Objects participating in the occlusion may move, rotate, undergo significant changes in shape and their scale may also change.
A hierarchical stochastic labeling technique to do shape matching of 2D occluded objects is presented. The technique explicitly maximized a criterion function based on the ambiguity and inconsistency of classification and the hierarchical nature of the algorithm reduced the computation time and used results obtained at low levels to speed up and improve accuracy of results at higher levels. The 2D shapes were represented by their polygonal approximation. For each of the objects participating in the occlusion, there was a hierarchical process. These processes were executed in parallel and were coordinated in such a way that the same segment of the apparent object, formed as a result of occlusion of two or more actual objects, was not matched to the segments of different actual objects. This problem was solved by combining the gradient projection method and penalty function approach. Objects participating in the occlusion may move, rotate, undergo significant changes in shape and their scale may also change.
Recognition of Occluded Two Dimensional Objects
 The problem of recognizing occluded or partially occluded objects has become more and more important in applications such as biomedical image analysis, industrial inspection, and robotics. We proposed a hierarchical stochastic labeling technique to identify parts of two dimensional shapes represented by their polygonal approximations.
The problem of recognizing occluded or partially occluded objects has become more and more important in applications such as biomedical image analysis, industrial inspection, and robotics. We proposed a hierarchical stochastic labeling technique to identify parts of two dimensional shapes represented by their polygonal approximations.
Improve transmission by designing filters for image dehazing
.png) Image haze removal techniques have a promising application prospects. However, color distortion by excessive dehazing is a common problem especially for images containing light color surface objects. To solve this problem, an improved image dehazing method based on dark channel prior with color fidelity is proposed in this paper. First, filters (Sobel operator and mean filter) are used to refine the initial transmission map estimated from the dark channel prior. Second, a piecewise constrained function is proposed to keep color fidelity. Experimental results on real world images show that the approach is effective in haze removal and preventing the color distortion from excessive dehazing. Preferable results of recovered images with bright and realistic colors and enhanced details are achieved.
Image haze removal techniques have a promising application prospects. However, color distortion by excessive dehazing is a common problem especially for images containing light color surface objects. To solve this problem, an improved image dehazing method based on dark channel prior with color fidelity is proposed in this paper. First, filters (Sobel operator and mean filter) are used to refine the initial transmission map estimated from the dark channel prior. Second, a piecewise constrained function is proposed to keep color fidelity. Experimental results on real world images show that the approach is effective in haze removal and preventing the color distortion from excessive dehazing. Preferable results of recovered images with bright and realistic colors and enhanced details are achieved.
|



 Nous montrons comment le problème de la Reconnaissance de l’occurence d’une forme plane à l’interieur d’une autre forme indépendemment d’un facteur d’échelle et de rotation peut être
resolu par une méthode hiérarchique d’étiquetage probabiliste. Des examples d’application à des silhouettes de pièces industrielles sont présentés.
Nous montrons comment le problème de la Reconnaissance de l’occurence d’une forme plane à l’interieur d’une autre forme indépendemment d’un facteur d’échelle et de rotation peut être
resolu par une méthode hiérarchique d’étiquetage probabiliste. Des examples d’application à des silhouettes de pièces industrielles sont présentés.