Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi klrd takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
DeepDriver: Automated system for measuring valence and arousal in car driver videos
.png) We develop an automated system for analyzing facial expressions using valence and arousal measurements of a car driver. Our approach is a data driven approach and does not include any pre-processing done to the faces of the drivers. The motivation of this paper is to show that with large amount of data, deep learning networks can extract better and more robust facial features compared to state of-the-art hand crafted features. The network was trained on just the raw facial images and achieves better results compared to state-of-the-art methods. Our system incorporates Convolutional Neural Networks (CNN) for detecting the face and extracting the facial features, and a Long Short Term Memory (LSTM) for modelling the changes in CNN features with respect to time.
We develop an automated system for analyzing facial expressions using valence and arousal measurements of a car driver. Our approach is a data driven approach and does not include any pre-processing done to the faces of the drivers. The motivation of this paper is to show that with large amount of data, deep learning networks can extract better and more robust facial features compared to state of-the-art hand crafted features. The network was trained on just the raw facial images and achieves better results compared to state-of-the-art methods. Our system incorporates Convolutional Neural Networks (CNN) for detecting the face and extracting the facial features, and a Long Short Term Memory (LSTM) for modelling the changes in CNN features with respect to time.
Novel Representation for Driver Emotion Recognition in Motor Vehicle Videos
.png) A novel feature representation of human facial expressions for emotion recognition is developed. The representation leveraged the background texture removal ability of Anisotropic Inhibited Gabor Filtering (AIGF) with the compact representation of spatiotemporal local binary patterns. The emotion recognition system incorporated face detection and registration followed by the proposed feature representation: Local Anisotropic Inhibited Binary Patterns in Three Orthogonal Planes (LAIBP-TOP) and classification. The system is evaluated on videos from Motor Trend Magazine’s Best Driver Car of the Year 2014-2016. The results showed improved performance compared to other state-of-the-art feature representations.
A novel feature representation of human facial expressions for emotion recognition is developed. The representation leveraged the background texture removal ability of Anisotropic Inhibited Gabor Filtering (AIGF) with the compact representation of spatiotemporal local binary patterns. The emotion recognition system incorporated face detection and registration followed by the proposed feature representation: Local Anisotropic Inhibited Binary Patterns in Three Orthogonal Planes (LAIBP-TOP) and classification. The system is evaluated on videos from Motor Trend Magazine’s Best Driver Car of the Year 2014-2016. The results showed improved performance compared to other state-of-the-art feature representations.
A dense flow-based framework for real-time object registration under compound motion
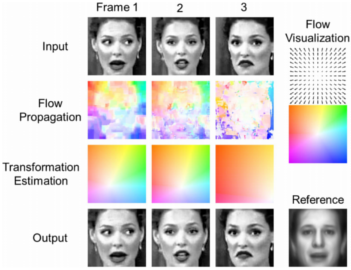 Tracking and measuring surface deformation while the object itself is also moving was a challenging, yet important problem in many video analysis tasks. For example, video-based facial expression recognition required tracking non-rigid motions of facial features without being affected by any rigid motions of the head. Presented is a generic video alignment framework to extract and characterize surface deformations accompanied by rigid-body motions with respect to a fixed reference (a canonical form). Also proposed is a generic model for object alignment in a Bayesian framework, and rigorously showed that a special case of the model results in a SIFT flow and optical flow based least-square problem. The proposed algorithm was evaluated on three applications, including the analysis of subtle facial muscle dynamics in spontaneous expressions, face image super-resolution, and generic object registration.
Tracking and measuring surface deformation while the object itself is also moving was a challenging, yet important problem in many video analysis tasks. For example, video-based facial expression recognition required tracking non-rigid motions of facial features without being affected by any rigid motions of the head. Presented is a generic video alignment framework to extract and characterize surface deformations accompanied by rigid-body motions with respect to a fixed reference (a canonical form). Also proposed is a generic model for object alignment in a Bayesian framework, and rigorously showed that a special case of the model results in a SIFT flow and optical flow based least-square problem. The proposed algorithm was evaluated on three applications, including the analysis of subtle facial muscle dynamics in spontaneous expressions, face image super-resolution, and generic object registration.
To Skip or not to Skip? A Dataset of Spontaneous Affective Response of Online Advertising (SARA) for Audience Behavior Analysis
 Researchers analyze audience’s behavior in order to prevent zapping, which helps advertisers to design effective commercial advertisements. Since emotions can be used to engage consumers we leverage automated facial expression analysis to understand consumers’ zapping behavior. To this end, we collect 612 sequences of spontaneous facial expression videos by asking 51 participants to watch 12 advertisements from three different categories, namely Car, Fast Food, and Running Shoe. We adopt a datadriven approach to formulate a zapping/non-zapping binary classification problem.
Researchers analyze audience’s behavior in order to prevent zapping, which helps advertisers to design effective commercial advertisements. Since emotions can be used to engage consumers we leverage automated facial expression analysis to understand consumers’ zapping behavior. To this end, we collect 612 sequences of spontaneous facial expression videos by asking 51 participants to watch 12 advertisements from three different categories, namely Car, Fast Food, and Running Shoe. We adopt a datadriven approach to formulate a zapping/non-zapping binary classification problem.
One Shot Emotion Scores for Facial Emotion Recognition
 Facial emotion recognition in unconstrained settings is a
difficult task. They key problems are that people express their
emotions in ways that are different from other people, and
for large datasets there are not enough examples of a specific
person to model his/her emotion. A model for predicting
emotions will not generalize well to predicting the emotions
of a person who has not been encountered during the training.
We propose a system that addresses these issues by matching
a face video to references of emotion. It does not require examples
from the person in the video being queried. We compute
the matching scores without requiring fine registration.
The method is called one-shot emotion score. We improve
classification rate of interdataset experiments over a baseline
system by 23% when training on MMI and testing on CK+.
Facial emotion recognition in unconstrained settings is a
difficult task. They key problems are that people express their
emotions in ways that are different from other people, and
for large datasets there are not enough examples of a specific
person to model his/her emotion. A model for predicting
emotions will not generalize well to predicting the emotions
of a person who has not been encountered during the training.
We propose a system that addresses these issues by matching
a face video to references of emotion. It does not require examples
from the person in the video being queried. We compute
the matching scores without requiring fine registration.
The method is called one-shot emotion score. We improve
classification rate of interdataset experiments over a baseline
system by 23% when training on MMI and testing on CK+.
Zapping Index: Using Smile to Measure Advertisement Zapping Likelihood
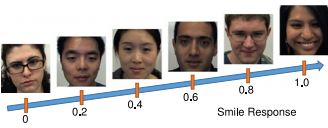 In marketing and advertising research, “zapping” is defined as the action when a viewer stops watching a commercial.
Researchers analyze users’ behavior in order to prevent zapping which helps advertisers to design effective commercials. Since
emotions can be used to engage consumers we leverage automated facial expression analysis to understand
consumers’ zapping behavior. Firstly, we provide an accurate moment-to-moment smile detection algorithm. Secondly, we formulate a
binary classification problem (zapping/non-zapping) based on real-world scenarios, and adopt smile response as the feature to predict
zapping. Thirdly, to cope with the lack of a metric in advertising evaluation, we propose a new metric called Zapping Index (ZI). ZI is a
moment-to-moment measurement of a user’s zapping probability. It gauges not only the reaction of a user, but also the preference of a
user to commercials. Finally, extensive experiments are performed to provide insights and we make recommendations that will be
useful to both advertisers and advertisement publishers.
In marketing and advertising research, “zapping” is defined as the action when a viewer stops watching a commercial.
Researchers analyze users’ behavior in order to prevent zapping which helps advertisers to design effective commercials. Since
emotions can be used to engage consumers we leverage automated facial expression analysis to understand
consumers’ zapping behavior. Firstly, we provide an accurate moment-to-moment smile detection algorithm. Secondly, we formulate a
binary classification problem (zapping/non-zapping) based on real-world scenarios, and adopt smile response as the feature to predict
zapping. Thirdly, to cope with the lack of a metric in advertising evaluation, we propose a new metric called Zapping Index (ZI). ZI is a
moment-to-moment measurement of a user’s zapping probability. It gauges not only the reaction of a user, but also the preference of a
user to commercials. Finally, extensive experiments are performed to provide insights and we make recommendations that will be
useful to both advertisers and advertisement publishers.
Vision and Attention Theory Based Sampling for Continuous Facial Emotion Recognition
(Video Link)
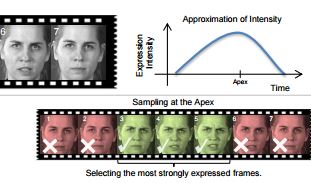 Affective computing—the emergent field in which computers detect emotions and project appropriate expressions of their
own—has reached a bottleneck where algorithms are not able to
infer a person’s emotions from natural and spontaneous facial
expressions captured in video. While the field of emotion recognition
has seen many advances in the past decade, a facial emotion
recognition approach has not yet been revealed which performs well
in unconstrained settings. In this paper, we propose a principled
method which addresses the temporal dynamics of facial emotions
and expressions in video with a sampling approach inspired from
human perceptual psychology. We test the efficacy of the method on
the Audio/Visual Emotion Challenge 2011 and 2012, Cohn-Kanade
and the MMI Facial Expression Database. The method shows an
average improvement of 9.8% over the baseline for weighted accuracy
on the Audio/Visual Emotion Challenge 2011 video-based
frame-level subchallenge testing set
Affective computing—the emergent field in which computers detect emotions and project appropriate expressions of their
own—has reached a bottleneck where algorithms are not able to
infer a person’s emotions from natural and spontaneous facial
expressions captured in video. While the field of emotion recognition
has seen many advances in the past decade, a facial emotion
recognition approach has not yet been revealed which performs well
in unconstrained settings. In this paper, we propose a principled
method which addresses the temporal dynamics of facial emotions
and expressions in video with a sampling approach inspired from
human perceptual psychology. We test the efficacy of the method on
the Audio/Visual Emotion Challenge 2011 and 2012, Cohn-Kanade
and the MMI Facial Expression Database. The method shows an
average improvement of 9.8% over the baseline for weighted accuracy
on the Audio/Visual Emotion Challenge 2011 video-based
frame-level subchallenge testing set
Background suppressing Gabor energy filtering
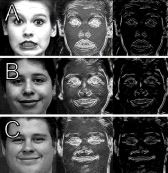 In the field of facial emotion recognition, early research advanced with the use of Gabor filters.
However, these filters lack generalization and result in undesirably large feature vector size.
In recent work, more attention has been given to other local appearance features. Two desired
characteristics in a facial appearance feature are generalization capability, and the
compactness of representation. In this paper, we propose a novel texture feature inspired
by Gabor energy filters, called background suppressing Gabor energy filtering. The feature
has a generalization component that removes background texture. It has a reduced feature
vector size due to maximal representation and soft orientation histograms, and it is a white
box representation. We demonstrate improved performance on the non-trivial Audio/Visual Emotion
Challenge 2012 grand-challenge dataset by a factor of 7.17 over the Gabor filter on the
development set. We also demonstrate applicability of our approach beyond facial emotion
recognition which yields improved classification rate over the Gabor filter for four bioimaging
datasets by an average of 8.22%.
In the field of facial emotion recognition, early research advanced with the use of Gabor filters.
However, these filters lack generalization and result in undesirably large feature vector size.
In recent work, more attention has been given to other local appearance features. Two desired
characteristics in a facial appearance feature are generalization capability, and the
compactness of representation. In this paper, we propose a novel texture feature inspired
by Gabor energy filters, called background suppressing Gabor energy filtering. The feature
has a generalization component that removes background texture. It has a reduced feature
vector size due to maximal representation and soft orientation histograms, and it is a white
box representation. We demonstrate improved performance on the non-trivial Audio/Visual Emotion
Challenge 2012 grand-challenge dataset by a factor of 7.17 over the Gabor filter on the
development set. We also demonstrate applicability of our approach beyond facial emotion
recognition which yields improved classification rate over the Gabor filter for four bioimaging
datasets by an average of 8.22%.
Efficient smile detection by Extreme Learning Machine
(Video Link 1) (Video Link 2)
 Smile detection is a specialized task in facial expression analysis with applications such as photo
selection, user experience analysis, and patient monitoring. As one of the most important and
informative expressions, smile conveys the underlying emotion status such as joy, happiness, and
satisfaction. We propose an efficient smile detection approach based on Extreme Learning
Machine (ELM). The faces are first detected and a holistic flow-based face registration is applied which
does not need any manual labeling or key point detection. Then ELM is used to train the classifier. The
proposed smile detector is tested with different feature descriptors on publicly available databases
including real-world face images. The comparisons against benchmark classifiers including Support
Vector Machine (SVM) and Linear Discriminant Analysis (LDA) suggest that the proposed ELM based
smile detector in general performs better and is very efficient. Compared to state-of-the-art smile
detector, the proposed method achieves competitive results without preprocessing and manual
registration.
Smile detection is a specialized task in facial expression analysis with applications such as photo
selection, user experience analysis, and patient monitoring. As one of the most important and
informative expressions, smile conveys the underlying emotion status such as joy, happiness, and
satisfaction. We propose an efficient smile detection approach based on Extreme Learning
Machine (ELM). The faces are first detected and a holistic flow-based face registration is applied which
does not need any manual labeling or key point detection. Then ELM is used to train the classifier. The
proposed smile detector is tested with different feature descriptors on publicly available databases
including real-world face images. The comparisons against benchmark classifiers including Support
Vector Machine (SVM) and Linear Discriminant Analysis (LDA) suggest that the proposed ELM based
smile detector in general performs better and is very efficient. Compared to state-of-the-art smile
detector, the proposed method achieves competitive results without preprocessing and manual
registration.
Continuous Facial Emotion Recognition
 Affective computing -- the emergent field in which computers detect emotions and project appropriate
expressions of their own -- has reached a bottleneck where algorithms are not able to infer a person’s
emotions from natural and spontaneous facial expressions captured in video. We propose a principled method
which addresses the temporal dynamics of facial emotions and expressions in video with a sampling approach
inspired from human perceptual psychology. The method shows an
average improvement of 9.8% over the baseline for weighted accuracy on the Audio/Visual Emotion Challenge
2011 video-based frame level sub-challenge testing set.
Affective computing -- the emergent field in which computers detect emotions and project appropriate
expressions of their own -- has reached a bottleneck where algorithms are not able to infer a person’s
emotions from natural and spontaneous facial expressions captured in video. We propose a principled method
which addresses the temporal dynamics of facial emotions and expressions in video with a sampling approach
inspired from human perceptual psychology. The method shows an
average improvement of 9.8% over the baseline for weighted accuracy on the Audio/Visual Emotion Challenge
2011 video-based frame level sub-challenge testing set.
Facial Emotion Recognition with Anisotropic Inhibited Gabor Energy Histograms
 State-of-the-art approaches have yet to deliver a feature representation
for facial emotion recognition that can be applied
to non-trivial unconstrained, continuous video data sets. Initially,
research advanced with the use of Gabor energy filters.
However, in recent work more attention has been given
to other features. Gabor energy filters lack generalization
needed in unconstrained situations. Additionally, they result
in an undesirably high feature vector dimensionality. Nontrivial
data sets have millions of samples; feature vectors must
be as low dimensional as possible. We propose a novel texture
feature based on Gabor energy filters that offers generalization
with a background texture suppression component and is
as compact as possible due to a maximal response representation
and local histograms. We improve performance on the
non-trivial Audio/Visual Emotion Challenge 2012 grandchallenge
data set.
State-of-the-art approaches have yet to deliver a feature representation
for facial emotion recognition that can be applied
to non-trivial unconstrained, continuous video data sets. Initially,
research advanced with the use of Gabor energy filters.
However, in recent work more attention has been given
to other features. Gabor energy filters lack generalization
needed in unconstrained situations. Additionally, they result
in an undesirably high feature vector dimensionality. Nontrivial
data sets have millions of samples; feature vectors must
be as low dimensional as possible. We propose a novel texture
feature based on Gabor energy filters that offers generalization
with a background texture suppression component and is
as compact as possible due to a maximal response representation
and local histograms. We improve performance on the
non-trivial Audio/Visual Emotion Challenge 2012 grandchallenge
data set.
Improving Action Units Recognition Using Dense Flow-based Face Registration in Video
 Aligning faces with non-rigid muscle motion in
the real-world streaming video is a challenging problem. We
propose a novel automatic video-based face registration architecture for facial expression recognition. The registration
process is formulated as a dense SIFT-flow- and optical-flow-
based affine warping problem. We start off by estimating the
transformation of an arbitrary face to a generic reference
face with canonical pose. This initialization in our framework
establishes a head pose and person independent face model. The
affine transformation computed from the initialization is then
propagated by affine transformation estimated from the dense
optical flow to guarantee the temporal smoothness of the non-
rigid facial appearance. We call this method SIFT and optical
flow affine image transform (SOFAIT). This real-time algorithm
is designed for realistic streaming data, allowing us to analyze
the facial muscle dynamics in a meaningful manner. Visual and
quantitative results demonstrate that the proposed automatic
video-based face registration technique captures the appearance
changes in spontaneous expressions and outperforms the state-
of-the-art technique.
Aligning faces with non-rigid muscle motion in
the real-world streaming video is a challenging problem. We
propose a novel automatic video-based face registration architecture for facial expression recognition. The registration
process is formulated as a dense SIFT-flow- and optical-flow-
based affine warping problem. We start off by estimating the
transformation of an arbitrary face to a generic reference
face with canonical pose. This initialization in our framework
establishes a head pose and person independent face model. The
affine transformation computed from the initialization is then
propagated by affine transformation estimated from the dense
optical flow to guarantee the temporal smoothness of the non-
rigid facial appearance. We call this method SIFT and optical
flow affine image transform (SOFAIT). This real-time algorithm
is designed for realistic streaming data, allowing us to analyze
the facial muscle dynamics in a meaningful manner. Visual and
quantitative results demonstrate that the proposed automatic
video-based face registration technique captures the appearance
changes in spontaneous expressions and outperforms the state-
of-the-art technique.
\
Understanding Discrete Facial Expressions in Video Using an Emotion Avatar Image
 Existing video-based facial expression recognition techniques analyze the geometry-based and
appearance-based information in every frame as well as explore the temporal relation among frames.
On the contrary, we present a new image-based representation and an associated reference image called
the emotion avatar image (EAI), and the avatar reference, respectively.
The approach to facial expression analysis consists of
the following steps: 1) face detection; 2) face registration of video frames with the avatar reference to form the
EAI representation; 3) computation of features from EAIs using both local binary patterns and local phase
quantization; and 4) the classification of the feature as one of the emotion type by using a linear support
vector machine classifier. The experimental results demonstrate that the information captured in an EAI for a
facial expression is a very strong cue for emotion inference.
Existing video-based facial expression recognition techniques analyze the geometry-based and
appearance-based information in every frame as well as explore the temporal relation among frames.
On the contrary, we present a new image-based representation and an associated reference image called
the emotion avatar image (EAI), and the avatar reference, respectively.
The approach to facial expression analysis consists of
the following steps: 1) face detection; 2) face registration of video frames with the avatar reference to form the
EAI representation; 3) computation of features from EAIs using both local binary patterns and local phase
quantization; and 4) the classification of the feature as one of the emotion type by using a linear support
vector machine classifier. The experimental results demonstrate that the information captured in an EAI for a
facial expression is a very strong cue for emotion inference.
Facial Emotion Recognition With Expression Energy
 Facial emotion recognition
in unconstrained settings is a typical case where algorithms perform poorly. A property of the AVEC2012 data set
is that individuals in testing data are not encountered in training data. In these situations, conventional approaches
suffer because models developed from training data cannot properly discriminate unforeseen testing samples.
We propose
two similarity metrics that address the problems of a conventional approach: neutral similarity, measuring the
intensity of an expression; and temporal similarity, measuring changes in an expression over time. These
similarities are taken to be the energy of facial expressions.
Our method improves correlation by 35.5% over the baseline approach on the frame-level sub-challenge.
Facial emotion recognition
in unconstrained settings is a typical case where algorithms perform poorly. A property of the AVEC2012 data set
is that individuals in testing data are not encountered in training data. In these situations, conventional approaches
suffer because models developed from training data cannot properly discriminate unforeseen testing samples.
We propose
two similarity metrics that address the problems of a conventional approach: neutral similarity, measuring the
intensity of an expression; and temporal similarity, measuring changes in an expression over time. These
similarities are taken to be the energy of facial expressions.
Our method improves correlation by 35.5% over the baseline approach on the frame-level sub-challenge.
A Biologically Inspired Approach for Fusing Facial Expression and
Appearance for Emotion Recognition
 Facial emotion recognition from video is an exemplar case
where both humans and computers underperform. In recent
emotion recognition competitions, top approaches were using
either geometric relationships that best captured facial dynamics
or an accurate registration technique to develop appearance
features. These two methods capture two different
types of facial information similarly to how the human visual
system divides information when perceiving faces. We propose a biologically-inspired fusion approach that
emulates this process. The efficacy of the approach is tested
with the Audio/Visual Emotion Challenge 2011 data set, a
non-trivial data set where state-of-the-art approaches perform
under chance. The proposed approach increases classification
rates by 18.5% on publicly available data.
Facial emotion recognition from video is an exemplar case
where both humans and computers underperform. In recent
emotion recognition competitions, top approaches were using
either geometric relationships that best captured facial dynamics
or an accurate registration technique to develop appearance
features. These two methods capture two different
types of facial information similarly to how the human visual
system divides information when perceiving faces. We propose a biologically-inspired fusion approach that
emulates this process. The efficacy of the approach is tested
with the Audio/Visual Emotion Challenge 2011 data set, a
non-trivial data set where state-of-the-art approaches perform
under chance. The proposed approach increases classification
rates by 18.5% on publicly available data.
Facial Emotion Recognition in Continuous Video
 Facial emotion recognition–the detection of emotion states from video of facial expressions–has appli-
cations in video games, medicine, and affective computing. While there have been many advances, an
approach has yet to be revealed that performs well on the
non-trivial Audio/Visual Emotion Challenge 2011 data
set. A majority of approaches still employ single frame
classification, or temporally aggregate features. We assert that in unconstrained emotion video, a better
classification strategy should model the change in features,
versus simply combining them. We compute a derivative of features with histogram differencing and derivative
of Gaussians and model the changes with a hidden
Markov model. We are the first to incorporate temporal
information in terms of derivatives. The efficacy of the
approach is tested on the non-trivial AVEC2011 data
set and increases classification rates on the data by as
much as 13%.
Facial emotion recognition–the detection of emotion states from video of facial expressions–has appli-
cations in video games, medicine, and affective computing. While there have been many advances, an
approach has yet to be revealed that performs well on the
non-trivial Audio/Visual Emotion Challenge 2011 data
set. A majority of approaches still employ single frame
classification, or temporally aggregate features. We assert that in unconstrained emotion video, a better
classification strategy should model the change in features,
versus simply combining them. We compute a derivative of features with histogram differencing and derivative
of Gaussians and model the changes with a hidden
Markov model. We are the first to incorporate temporal
information in terms of derivatives. The efficacy of the
approach is tested on the non-trivial AVEC2011 data
set and increases classification rates on the data by as
much as 13%.
A Psychologically-Inspired Match-Score Fusion Model for Video-Based Facial Expression Recognition
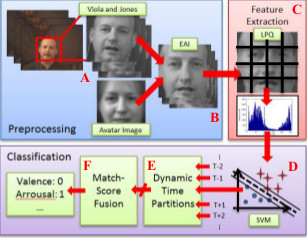 Communication between humans is rich in complexity and is not limited to verbal signals; emotions are
conveyed with gesture, pose and facial expression. Facial Emotion Recognition and Analysis (FERA),
the set of techniques by which non-verbal communication is quantified, is an exemplar case where humans
consistently outperform computer methods. While the field of FERA has seen many advances, no system
has been proposed which scales well to very large data sets. The challenge for computer vision is how to
automatically and non-heuristically downsample the data while maintaining a minimum representational
power that does not sacrifice accuracy. We propose a method inspired by human vision and
attention theory. Video is segmented into temporal partitions with a dynamic sampling rate based on the
frequency of visual information. Regions are homogenized by an experimentally selected match-score fusion
technique. The approach is shown to increase classification rates by over baseline with the AVEC 2011
video-subchallenge.
Communication between humans is rich in complexity and is not limited to verbal signals; emotions are
conveyed with gesture, pose and facial expression. Facial Emotion Recognition and Analysis (FERA),
the set of techniques by which non-verbal communication is quantified, is an exemplar case where humans
consistently outperform computer methods. While the field of FERA has seen many advances, no system
has been proposed which scales well to very large data sets. The challenge for computer vision is how to
automatically and non-heuristically downsample the data while maintaining a minimum representational
power that does not sacrifice accuracy. We propose a method inspired by human vision and
attention theory. Video is segmented into temporal partitions with a dynamic sampling rate based on the
frequency of visual information. Regions are homogenized by an experimentally selected match-score fusion
technique. The approach is shown to increase classification rates by over baseline with the AVEC 2011
video-subchallenge.
Facial Expression Recognition Using Emotion Avatar Image
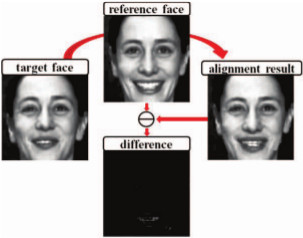 Existing facial expression recognition techniques
analyze the spatial and temporal information for every single
frame in a human emotion video. On the contrary, we create the
Emotion Avatar Image (EAI) as a single good representation for
each video or image sequence for emotion recognition. In this
paper, we adopt the recently introduced SIFT flow algorithm to
register every frame with respect to an Avatar reference face
model. Then, an iterative algorithm is used not only to superresolve
the EAI representation for each video and the Avatar
reference, but also to improve the recognition performance.
Subsequently, we extract the features from EAIs using both
Local Binary Pattern (LBP) and Local Phase Quantization
(LPQ). Then the results from both texture descriptors are tested
on the Facial Expression Recognition and Analysis Challenge
(FERA2011) data, GEMEP-FERA dataset. To evaluate this
simple yet powerful idea, we train our algorithm only using the
given 155 videos of training data from GEMEP-FERA dataset.
The result shows that our algorithm eliminates the personspecific
information for emotion and performs well on unseen
data.
Existing facial expression recognition techniques
analyze the spatial and temporal information for every single
frame in a human emotion video. On the contrary, we create the
Emotion Avatar Image (EAI) as a single good representation for
each video or image sequence for emotion recognition. In this
paper, we adopt the recently introduced SIFT flow algorithm to
register every frame with respect to an Avatar reference face
model. Then, an iterative algorithm is used not only to superresolve
the EAI representation for each video and the Avatar
reference, but also to improve the recognition performance.
Subsequently, we extract the features from EAIs using both
Local Binary Pattern (LBP) and Local Phase Quantization
(LPQ). Then the results from both texture descriptors are tested
on the Facial Expression Recognition and Analysis Challenge
(FERA2011) data, GEMEP-FERA dataset. To evaluate this
simple yet powerful idea, we train our algorithm only using the
given 155 videos of training data from GEMEP-FERA dataset.
The result shows that our algorithm eliminates the personspecific
information for emotion and performs well on unseen
data.
Super-Resolution of Deformed Facial Images in Video
 Super-resolution (SR) of facial images from video suffers
from facial expression changes. Most of the existing SR algorithms
for facial images make an unrealistic assumption
that the “perfect” registration has been done prior to the SR
process. However, the registration is a challenging task for
SR with expression changes. This research proposes a new
method for enhancing the resolution of low-resolution (LR)
facial image by handling the facial image in a non-rigid manner.
It consists of global tracking, local alignment for precise
registration and SR algorithms. A B-spline based Resolution
Aware Incremental Free Form Deformation (RAIFFD) model
is used to recover a dense local non-rigid flow field. In this
scheme, low-resolution image model is explicitly embedded
in the optimization function formulation to simulate the formation
of low resolution image. The results achieved by the
proposed approach are significantly better as compared to
the SR approaches applied on the whole face image without
considering local deformations.
Super-resolution (SR) of facial images from video suffers
from facial expression changes. Most of the existing SR algorithms
for facial images make an unrealistic assumption
that the “perfect” registration has been done prior to the SR
process. However, the registration is a challenging task for
SR with expression changes. This research proposes a new
method for enhancing the resolution of low-resolution (LR)
facial image by handling the facial image in a non-rigid manner.
It consists of global tracking, local alignment for precise
registration and SR algorithms. A B-spline based Resolution
Aware Incremental Free Form Deformation (RAIFFD) model
is used to recover a dense local non-rigid flow field. In this
scheme, low-resolution image model is explicitly embedded
in the optimization function formulation to simulate the formation
of low resolution image. The results achieved by the
proposed approach are significantly better as compared to
the SR approaches applied on the whole face image without
considering local deformations.
Super-resolution of Facial Images in Video with Expression Changes
 Super-resolution (SR) of facial images from video suffers
from facial expression changes. Most of the existing SR
algorithms for facial images make an unrealistic assumption
that the “perfect” registration has been done prior to
the SR process. However, the registration is a challenging
task for SR with expression changes. This research proposes a
new method for enhancing the resolution of low-resolution
(LR) facial image by handling the facial image in a nonrigid
manner. It consists of global tracking, local alignment
for precise registration and SR algorithms. A B-spline
based Resolution Aware Incremental Free Form Deformation
(RAIFFD) model is used to recover a dense local nonrigid
flow field. In this scheme, low-resolution image model
is explicitly embedded in the optimization function formulation
to simulate the formation of low resolution image.
The results achieved by the proposed approach are significantly
better as compared to the SR approaches applied
on the whole face image without considering local deformations.
The results are also compared with two state-ofthe-
art SR algorithms to show the effectiveness of the approach
in super-resolving facial images with local expression
changes.
Super-resolution (SR) of facial images from video suffers
from facial expression changes. Most of the existing SR
algorithms for facial images make an unrealistic assumption
that the “perfect” registration has been done prior to
the SR process. However, the registration is a challenging
task for SR with expression changes. This research proposes a
new method for enhancing the resolution of low-resolution
(LR) facial image by handling the facial image in a nonrigid
manner. It consists of global tracking, local alignment
for precise registration and SR algorithms. A B-spline
based Resolution Aware Incremental Free Form Deformation
(RAIFFD) model is used to recover a dense local nonrigid
flow field. In this scheme, low-resolution image model
is explicitly embedded in the optimization function formulation
to simulate the formation of low resolution image.
The results achieved by the proposed approach are significantly
better as compared to the SR approaches applied
on the whole face image without considering local deformations.
The results are also compared with two state-ofthe-
art SR algorithms to show the effectiveness of the approach
in super-resolving facial images with local expression
changes.
Super-resolution Restoration of Facial Images in Video
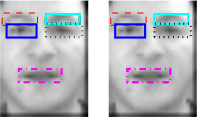 Reconstruction-based super-resolution has been widely
treated in computer vision. However, super-resolution of
facial images has received very little attention. Since different
parts of a face may have different motions in normal
videos, this research proposes a new method for enhancing
the resolution of low-resolution facial image by handling
the facial image non-uniformly. We divide low-resolution
face image into different regions based on facial features
and estimate motions of each of these regions using different
motion models. Our experimental results show we can
achieve better results than applying super-resolution on the
whole face image uniformly.
Reconstruction-based super-resolution has been widely
treated in computer vision. However, super-resolution of
facial images has received very little attention. Since different
parts of a face may have different motions in normal
videos, this research proposes a new method for enhancing
the resolution of low-resolution facial image by handling
the facial image non-uniformly. We divide low-resolution
face image into different regions based on facial features
and estimate motions of each of these regions using different
motion models. Our experimental results show we can
achieve better results than applying super-resolution on the
whole face image uniformly.
Evolutionary Feature Synthesis for Facial Expression Recognition
 We present a novel genetically
inspired learning method for facial expression recognition (FER). Our learning method can select visually meaningful
features automatically in a genetic programming-based approach that uses Gabor wavelet representation for
primitive features and linear/nonlinear operators to synthesize new features. To make use of random nature of a genetic
program, we design a multi-agent scheme to boost the performance. We compare the performance of our
approach with several approaches in the literature and show that our approach can perform the task of facial
expression recognition effectively.
We present a novel genetically
inspired learning method for facial expression recognition (FER). Our learning method can select visually meaningful
features automatically in a genetic programming-based approach that uses Gabor wavelet representation for
primitive features and linear/nonlinear operators to synthesize new features. To make use of random nature of a genetic
program, we design a multi-agent scheme to boost the performance. We compare the performance of our
approach with several approaches in the literature and show that our approach can perform the task of facial
expression recognition effectively.
Feature Synthesis Using Genetic Programming for Face Expression Recognition
 We have introduced a novel genetically-inspired learning method for face expression recognition (FER) in visible images. Unlike
current research for FER that generally uses visually meaningful feature, we
proposed a Genetic Programming based technique, which learns to discover
composite operators and features that are evolved from combinations of
primitive image processing operations. In this approach, the output of the
learned composite operator is a feature vector that is used for FER. The
experimental results show that our approach can find good composite operators
to effectively extract useful features.
We have introduced a novel genetically-inspired learning method for face expression recognition (FER) in visible images. Unlike
current research for FER that generally uses visually meaningful feature, we
proposed a Genetic Programming based technique, which learns to discover
composite operators and features that are evolved from combinations of
primitive image processing operations. In this approach, the output of the
learned composite operator is a feature vector that is used for FER. The
experimental results show that our approach can find good composite operators
to effectively extract useful features.
|


