Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi klrd takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
Semantic concept co-occurrence patterns for image annotation and retrieval
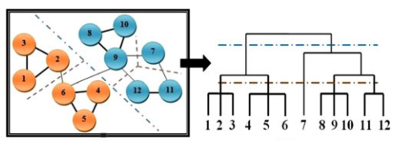 Presented is a novel approach to automatically generate intermediate image descriptors by exploiting concept co-occurrence patterns in the pre-labeled training set that renders it possible to depict complex scene images semantically. This work is motivated by the fact that multiple concepts that frequently co-occur across images form patterns which could provide contextual cues for individual concept inference. The co-occurrence patterns were discovered as hierarchical communities by graph modularity maximization in a network with nodes and edges representing concepts and co-occurrence relationships separately. A random walk process working on the inferred concept probabilities with the discovered co-occurrence patterns was applied to acquire the refined concept signature representation. Through experiments in automatic image annotation and semantic image retrieval on several challenging datasets, the effectiveness of the proposed concept co-occurrence patterns as well as the concept signature representation in comparison with state-of-the-art approaches was demonstrated.
Presented is a novel approach to automatically generate intermediate image descriptors by exploiting concept co-occurrence patterns in the pre-labeled training set that renders it possible to depict complex scene images semantically. This work is motivated by the fact that multiple concepts that frequently co-occur across images form patterns which could provide contextual cues for individual concept inference. The co-occurrence patterns were discovered as hierarchical communities by graph modularity maximization in a network with nodes and edges representing concepts and co-occurrence relationships separately. A random walk process working on the inferred concept probabilities with the discovered co-occurrence patterns was applied to acquire the refined concept signature representation. Through experiments in automatic image annotation and semantic image retrieval on several challenging datasets, the effectiveness of the proposed concept co-occurrence patterns as well as the concept signature representation in comparison with state-of-the-art approaches was demonstrated.
A software system for automated identification and retrieval of moth images based on wing attributes
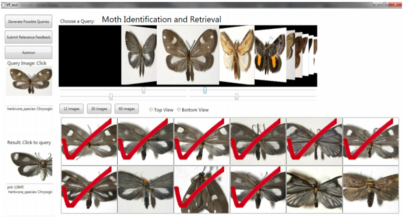 Described is the development of an automated moth species identification and retrieval system (SPIR) using computer vision and pattern recognition techniques. The core of the system was a probabilistic model that infered Semantically Related Visual (SRV) attributes from low-level visual features of moth images in the training set, where moth wings were segmented into information-rich patches from which the local features were extracted, and the SRV attributes were provided by human experts as ground-truth. For the large amount of unlabeled test images in the database or added into the database later on, an automated identification process was evoked to translate the detected salient regions of low-level visual features on the moth wings into meaningful semantic SRV attributes. We further proposed a novel network analysis based approach to explore and utilize the co-occurrence patterns of SRV attributes as contextual cues to improve individual attribute detection accuracy. Working with a small set of labeled training images, the approach constructed a network with nodes representing the SRV attributes and weighted edges denoting the co-occurrence correlation.
Described is the development of an automated moth species identification and retrieval system (SPIR) using computer vision and pattern recognition techniques. The core of the system was a probabilistic model that infered Semantically Related Visual (SRV) attributes from low-level visual features of moth images in the training set, where moth wings were segmented into information-rich patches from which the local features were extracted, and the SRV attributes were provided by human experts as ground-truth. For the large amount of unlabeled test images in the database or added into the database later on, an automated identification process was evoked to translate the detected salient regions of low-level visual features on the moth wings into meaningful semantic SRV attributes. We further proposed a novel network analysis based approach to explore and utilize the co-occurrence patterns of SRV attributes as contextual cues to improve individual attribute detection accuracy. Working with a small set of labeled training images, the approach constructed a network with nodes representing the SRV attributes and weighted edges denoting the co-occurrence correlation.
Discrete Cosine Transform Locality-Sensitive Hashes for Face Retrieval
![Sample images from LFW [44],FERET [40], RaFD [42], BioID [43],FEI [41], and Multi-PIE [39]](../research_images/DiscreteCosineTransformLocality-SensitiveHashes14.png) Searching large databases using local binary patterns for face recognition has been problematic due to
the cost of the linear search, and the inadequate performance of existing indexing
methods. We present Discrete Cosine Transform (DCT) hashing for creating index structures for
face descriptors. Hashes play the role of keywords: an index is created, and queried to find
the images most similar to the query image. It is shown in this research that DCT hashing has significantly
better retrieval accuracy and it is more efficient compared to other popular state-of-the-art
hash algorithms.
Searching large databases using local binary patterns for face recognition has been problematic due to
the cost of the linear search, and the inadequate performance of existing indexing
methods. We present Discrete Cosine Transform (DCT) hashing for creating index structures for
face descriptors. Hashes play the role of keywords: an index is created, and queried to find
the images most similar to the query image. It is shown in this research that DCT hashing has significantly
better retrieval accuracy and it is more efficient compared to other popular state-of-the-art
hash algorithms.
Automated Identification and Retrieval of Moth Images with Semantically Related Visual Attributes on the Wings
 A new automated identification and retrieval system is proposed
that aims to provide entomologists, who manage insect
specimen images, with fast computer-based processing
and analyzing techniques. Several relevant image attributes
were designed, such as the so-called semantically-related
visual (SRV) attributes detected from the insect wings and
the co-occurrence patterns of the SRV attributes which are
uncovered from manually labeled training samples. A joint
probabilistic model is used as SRV attribute detector working
on image visual contents. The identification and retrieval of
moth species are conducted by comparing the similarity of
SRV attributes and their co-occurrence patterns. The prototype
system used moth images while it can be generalized
to any insect species with wing structures. The system performed
with good stability and the accuracy reached 85%
for species identification and 71% for content-based image
retrieval on a entomology database.
A new automated identification and retrieval system is proposed
that aims to provide entomologists, who manage insect
specimen images, with fast computer-based processing
and analyzing techniques. Several relevant image attributes
were designed, such as the so-called semantically-related
visual (SRV) attributes detected from the insect wings and
the co-occurrence patterns of the SRV attributes which are
uncovered from manually labeled training samples. A joint
probabilistic model is used as SRV attribute detector working
on image visual contents. The identification and retrieval of
moth species are conducted by comparing the similarity of
SRV attributes and their co-occurrence patterns. The prototype
system used moth images while it can be generalized
to any insect species with wing structures. The system performed
with good stability and the accuracy reached 85%
for species identification and 71% for content-based image
retrieval on a entomology database.
Improving Large-scale Face Image Retrieval using Multi-level Features
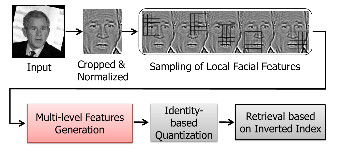 In recent years, extensive efforts have been made for face
recognition and retrieval systems. However, there remain
several challenging tasks for face image retrieval in unconstrained
databases where the face images were captured
with varying poses, lighting conditions, etc. In addition,
the databases are often large-scale, which demand efficient
retrieval algorithms that have the merit of scalability. To
improve the retrieval accuracy of the face images with different
poses and imaging characteristics, we introduce a novel
feature extraction method to bag-of-words (BoW) based face
image retrieval system. It employs various scales of features
simultaneously to encode different texture information and
emphasizes image patches that are more discriminative as
parts of the face. Moreover, the overlapping image patches
at different scales compensate for the pose variation and face
misalignment. Experiments conducted on a large-scale public
face database demonstrate the superior performance of the
proposed approach compared to the state-of-the-art method.
In recent years, extensive efforts have been made for face
recognition and retrieval systems. However, there remain
several challenging tasks for face image retrieval in unconstrained
databases where the face images were captured
with varying poses, lighting conditions, etc. In addition,
the databases are often large-scale, which demand efficient
retrieval algorithms that have the merit of scalability. To
improve the retrieval accuracy of the face images with different
poses and imaging characteristics, we introduce a novel
feature extraction method to bag-of-words (BoW) based face
image retrieval system. It employs various scales of features
simultaneously to encode different texture information and
emphasizes image patches that are more discriminative as
parts of the face. Moreover, the overlapping image patches
at different scales compensate for the pose variation and face
misalignment. Experiments conducted on a large-scale public
face database demonstrate the superior performance of the
proposed approach compared to the state-of-the-art method.
Integrated Personalized Video Summarization and Retrieval
.png) We propose an integrated and personalized video retrieval and summarization system. We estimate and impose appropriate preference values on affinity propagation graph of the video frames. Then, our system produces the summary which is useful for the user in her/his relevance feedback and for the retrieval module for comparing video pairs. The experiments confirm the effectiveness of our approach for various query types.
We propose an integrated and personalized video retrieval and summarization system. We estimate and impose appropriate preference values on affinity propagation graph of the video frames. Then, our system produces the summary which is useful for the user in her/his relevance feedback and for the retrieval module for comparing video pairs. The experiments confirm the effectiveness of our approach for various query types.
Semantic-visual Concept Relatedness and Co-Occurrences for Image Retrieval
 We introduce a novel approach that allows the retrieval
of complex images by integrating visual and semantic
concepts. The basic idea consists of three aspects. First,
we measure the relatedness of semantic and visual concepts
and select the visually separable semantic concepts as elements
in the proposed image signature representation. Second,
we demonstrate the existence of concept co-occurrence
patterns. We propose to uncover those underlying patterns
by detecting the communities in a network structure. Third,
we leverage the visual and semantic correspondence and the
co-occurrence patterns to improve the accuracy and efficiency
for image retrieval. We perform experiments on two popular
datasets that confirm the effectiveness of our approach.
We introduce a novel approach that allows the retrieval
of complex images by integrating visual and semantic
concepts. The basic idea consists of three aspects. First,
we measure the relatedness of semantic and visual concepts
and select the visually separable semantic concepts as elements
in the proposed image signature representation. Second,
we demonstrate the existence of concept co-occurrence
patterns. We propose to uncover those underlying patterns
by detecting the communities in a network structure. Third,
we leverage the visual and semantic correspondence and the
co-occurrence patterns to improve the accuracy and efficiency
for image retrieval. We perform experiments on two popular
datasets that confirm the effectiveness of our approach.
Concept Learning with Co-occurrence Network for Image Retrieval
 We addresses the problem of concept learning
for semantic image retrieval in this research. Two types of semantic concepts
are introduced in our system: the individual concept and the
scene concept. The individual concepts are explicitly provided
in a vocabulary of semantic words, which are the labels or
annotations in an image database. Scene concepts are higher
level concepts which are defined as potential patterns of cooccurrence
of individual concepts. Scene concepts exist since some
of the individual concepts co-occur frequently across different
images. This is similar to human learning where understanding
of simpler ideas is generally useful prior to developing more
sophisticated ones. Scene concepts can have more discriminative
power compared to individual concepts but methods are needed
to find them. A novel method for deriving scene concepts is presented.
It is based on a weighted concept co-occurrence network
(graph) with detected community structure property. An image
similarity comparison and retrieval framework is described with
the proposed individual and scene concept signature as the image
semantic descriptors. Extensive experiments are conducted on a
publicly available dataset to demonstrate the effectiveness of our
concept learning and semantic image retrieval framework.
We addresses the problem of concept learning
for semantic image retrieval in this research. Two types of semantic concepts
are introduced in our system: the individual concept and the
scene concept. The individual concepts are explicitly provided
in a vocabulary of semantic words, which are the labels or
annotations in an image database. Scene concepts are higher
level concepts which are defined as potential patterns of cooccurrence
of individual concepts. Scene concepts exist since some
of the individual concepts co-occur frequently across different
images. This is similar to human learning where understanding
of simpler ideas is generally useful prior to developing more
sophisticated ones. Scene concepts can have more discriminative
power compared to individual concepts but methods are needed
to find them. A novel method for deriving scene concepts is presented.
It is based on a weighted concept co-occurrence network
(graph) with detected community structure property. An image
similarity comparison and retrieval framework is described with
the proposed individual and scene concept signature as the image
semantic descriptors. Extensive experiments are conducted on a
publicly available dataset to demonstrate the effectiveness of our
concept learning and semantic image retrieval framework.
Image Retrieval for Highly Similar Objects
 In content-based image retrieval, precision is usually regarded as the top metric used for performance
measurement. With image databases reaching hundreds of millions of records, it is apparent that many
retrieval strategies will not scale. Data representation and organization has to be better understood.
This research focuses on: (a) feature selection and optimal representation of features and (b) multidimensional
tree indexing structure. The paper proposes the use of a forward and conditional backward searching
feature selection algorithm. The data is then put through a minimum description length based optimal
non-uniform bit allocation algorithm to reduce the size of the stored data, while preserving the structure of
the data. The results of our experiments show that the proposed feature selection process with a minimum
description length based non-uniform bit allocation method gives a system that improves retrieval time
and precision.
In content-based image retrieval, precision is usually regarded as the top metric used for performance
measurement. With image databases reaching hundreds of millions of records, it is apparent that many
retrieval strategies will not scale. Data representation and organization has to be better understood.
This research focuses on: (a) feature selection and optimal representation of features and (b) multidimensional
tree indexing structure. The paper proposes the use of a forward and conditional backward searching
feature selection algorithm. The data is then put through a minimum description length based optimal
non-uniform bit allocation algorithm to reduce the size of the stored data, while preserving the structure of
the data. The results of our experiments show that the proposed feature selection process with a minimum
description length based non-uniform bit allocation method gives a system that improves retrieval time
and precision.
Image Retrieval with Feature Selection and Relevance Feedback
 We propose a new content based image retrieval
(CBIR) system combined with relevance feedback and the
online feature selection procedures. A measure of
inconsistency from relevance feedback is explicitly used as
a new semantic criterion to guide the feature selection. By
integrating the user feedback information, the feature
selection is able to bridge the gap between low-level visual
features and high-level semantic information, leading to the
improved image retrieval accuracy. Experimental results
show that the proposed method obtains higher retrieval
accuracy than a commonly used approach.
We propose a new content based image retrieval
(CBIR) system combined with relevance feedback and the
online feature selection procedures. A measure of
inconsistency from relevance feedback is explicitly used as
a new semantic criterion to guide the feature selection. By
integrating the user feedback information, the feature
selection is able to bridge the gap between low-level visual
features and high-level semantic information, leading to the
improved image retrieval accuracy. Experimental results
show that the proposed method obtains higher retrieval
accuracy than a commonly used approach.
Feature Synthesized EM Algorithm for Image Retrieval
 Expectation-Maximization (EM) algorithms have several limitations, including the curse of dimensionality and
the convergence at a local maximum. In this article, we propose a novel learning approach, namely
Coevolutionary Feature Synthesized Expectation-Maximization (CFS-EM), to address the above problems.
Experiments on real image databases show that CFS-EM
out performs Radial Basis Function Support Vector Machine (RBF-SVM), CGP, Discriminant-EM (D-EM)
and Transductive-SVM (TSVM) in the sense of classification performance and it is computationally more efficient
than RBF-SVM in the query phase.
Expectation-Maximization (EM) algorithms have several limitations, including the curse of dimensionality and
the convergence at a local maximum. In this article, we propose a novel learning approach, namely
Coevolutionary Feature Synthesized Expectation-Maximization (CFS-EM), to address the above problems.
Experiments on real image databases show that CFS-EM
out performs Radial Basis Function Support Vector Machine (RBF-SVM), CGP, Discriminant-EM (D-EM)
and Transductive-SVM (TSVM) in the sense of classification performance and it is computationally more efficient
than RBF-SVM in the query phase.
Coevolutionary feature synthesized EM algorithm for image retrieval
.png) In this paper, we propose a unified framework of a novel learning approach, namely Coevolutionary Feature Synthesized Expectation-Maximization (CFSEM), to achieve satisfactory learning in spite of these difficulties. The CFS-EM is a hybrid of coevolutionary genetic programming (CGP) and EM algorithm. The advantages of CFS-EM are: 1) it synthesizes low-dimensional features based on CGP algorithm, which yields near optimal nonlinear transformation and classification precision comparable to kernel methods such as the support vector machine (SVM); 2) the explicitness of feature transformation is especially suitable for image retrieval because the images can be searched in the synthesized low-dimensional space, while kernel-based methods have to make classification computation in the original high-dimensional space; 3) the unlabeled data can be boosted with the help of the class distribution learning using CGP feature synthesis approach. Experimental results show that CFS-EM outperforms pure EM and CGP alone, and is comparable to SVM in the sense of classification. It is computationally more efficient than SVM in query phase. Moreover, it has a high likelihood that it will jump out of a local maximum to provide near optimal results and a better estimation of parameters.
In this paper, we propose a unified framework of a novel learning approach, namely Coevolutionary Feature Synthesized Expectation-Maximization (CFSEM), to achieve satisfactory learning in spite of these difficulties. The CFS-EM is a hybrid of coevolutionary genetic programming (CGP) and EM algorithm. The advantages of CFS-EM are: 1) it synthesizes low-dimensional features based on CGP algorithm, which yields near optimal nonlinear transformation and classification precision comparable to kernel methods such as the support vector machine (SVM); 2) the explicitness of feature transformation is especially suitable for image retrieval because the images can be searched in the synthesized low-dimensional space, while kernel-based methods have to make classification computation in the original high-dimensional space; 3) the unlabeled data can be boosted with the help of the class distribution learning using CGP feature synthesis approach. Experimental results show that CFS-EM outperforms pure EM and CGP alone, and is comparable to SVM in the sense of classification. It is computationally more efficient than SVM in query phase. Moreover, it has a high likelihood that it will jump out of a local maximum to provide near optimal results and a better estimation of parameters.
Integrating Relevance Feedback Techniques for Image Retrieval
 We propose an image relevance
reinforcement learning (IRRL) model for integrating existing RF techniques in a content-based image
retrieval system. Various integration schemes are presented and a long-term shared memory is used to
exploit the retrieval experience from multiple users. The experimental results manifest that the integration of
multiple RF
approaches gives better retrieval performance than using one RF technique alone. Further, the
storage demand is significantly reduced by the concept digesting technique.
We propose an image relevance
reinforcement learning (IRRL) model for integrating existing RF techniques in a content-based image
retrieval system. Various integration schemes are presented and a long-term shared memory is used to
exploit the retrieval experience from multiple users. The experimental results manifest that the integration of
multiple RF
approaches gives better retrieval performance than using one RF technique alone. Further, the
storage demand is significantly reduced by the concept digesting technique.
Evolutionary feature synthesis for image databases
.png) In this paper, we investigate the effectiveness of coevolutionary genetic programming (CGP) in synthesizing feature vectors for image databases from traditional features that are commonly used. The transformation for feature dimensionality reduction by CGP has two unique characteristics for image retrieval: 1) nonlinearlity: CGP does not assume any class distribution in the original visual feature space; 2) explicitness: unlike kernel trick, CGP yields explicit transformation for dimensionality reduction so that the images can be searched in the low-dimensional feature space. The experimental results on multiple databases show that (a) CGP approach has distinct advantage over the linear transformation approach of Multiple Discriminant Analysis (MDA) in the sense of the discrimination ability of the low-dimensional features, and (b) the classification performance using the features synthesized by our CGP approach is comparable to or even superior to that of support vector machine (SVM) approach using the original visual features.
In this paper, we investigate the effectiveness of coevolutionary genetic programming (CGP) in synthesizing feature vectors for image databases from traditional features that are commonly used. The transformation for feature dimensionality reduction by CGP has two unique characteristics for image retrieval: 1) nonlinearlity: CGP does not assume any class distribution in the original visual feature space; 2) explicitness: unlike kernel trick, CGP yields explicit transformation for dimensionality reduction so that the images can be searched in the low-dimensional feature space. The experimental results on multiple databases show that (a) CGP approach has distinct advantage over the linear transformation approach of Multiple Discriminant Analysis (MDA) in the sense of the discrimination ability of the low-dimensional features, and (b) the classification performance using the features synthesized by our CGP approach is comparable to or even superior to that of support vector machine (SVM) approach using the original visual features.
Uncertain Spatial Data Handling: Modeling, Indexing and Query
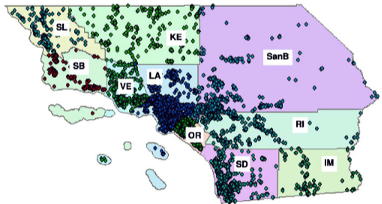 Managing and manipulating uncertainty in spatial databases are important problems for various
practical applications of geographic information systems. We present a probability-based method to
model and index uncertain spatial
data. In this scheme, each object is represented by a probability density function (PDF) and a
general measure is proposed for measuring similarity between the objects. To index objects, an optimized
Gaussian mixture hierarchy (OGMH) is designed to support both certain/uncertain data and certain/uncertain
queries. As an example of uncertain query support OGMH is applied
to the Mojave Desert endangered species protection real dataset. It is found that OGMH provides more selective,
efficient and flexible search than the results provided by the existing trial and error approach for endangered
species habitat search.
Managing and manipulating uncertainty in spatial databases are important problems for various
practical applications of geographic information systems. We present a probability-based method to
model and index uncertain spatial
data. In this scheme, each object is represented by a probability density function (PDF) and a
general measure is proposed for measuring similarity between the objects. To index objects, an optimized
Gaussian mixture hierarchy (OGMH) is designed to support both certain/uncertain data and certain/uncertain
queries. As an example of uncertain query support OGMH is applied
to the Mojave Desert endangered species protection real dataset. It is found that OGMH provides more selective,
efficient and flexible search than the results provided by the existing trial and error approach for endangered
species habitat search.
Handling Uncertain Spatial Data: Comparisons Between Indexing Structures
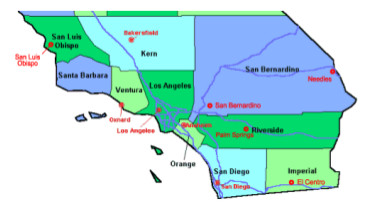 Managing and manipulating uncertainty in spatial
databases are important problems for various practical
applications. Unlike the traditional fuzzy approaches in relational
databases, in this research we propose a probability-based method to
model and index uncertain spatial data where every object is
represented by a probability density function (PDF). To index
PDFs, we construct an optimized Gaussian mixture hierarchy
(OGMH) and two variants of uncertain R-tree. We provide a
comprehensive comparison among these three indices and plain
R-tree on TIGER/Line Southern California landmark point
dataset. We find that uncertain R-tree is the best for fixed query
and OGMH is suitable for both certain and uncertain queries.
Moreover, OGMH is suitable not only for spatial databases, but
also for multi-dimensional indexing applications like content
based image retrieval, where R-tree is inefficient in high
dimensions.
Managing and manipulating uncertainty in spatial
databases are important problems for various practical
applications. Unlike the traditional fuzzy approaches in relational
databases, in this research we propose a probability-based method to
model and index uncertain spatial data where every object is
represented by a probability density function (PDF). To index
PDFs, we construct an optimized Gaussian mixture hierarchy
(OGMH) and two variants of uncertain R-tree. We provide a
comprehensive comparison among these three indices and plain
R-tree on TIGER/Line Southern California landmark point
dataset. We find that uncertain R-tree is the best for fixed query
and OGMH is suitable for both certain and uncertain queries.
Moreover, OGMH is suitable not only for spatial databases, but
also for multi-dimensional indexing applications like content
based image retrieval, where R-tree is inefficient in high
dimensions.
Discriminant features for Model-Based Image Databases
.png) A challenging topic in content-based image retrieval is to determine the discriminant features that improve classification performance. An approach to learn concepts is by estimating mixture model for image databases using EM algorithm; however, this approach is impractical to be implemented for large databases due to the high dimensionality of the feature space. Based on the over-splitting nature of our EM algorithm and the Bayesian analysis of the multiple users' labelling information derived from their relevance feedbacks, we propose a probabilistic MDA to find the discriminating features, and integrate it with the EM framework. The experimental results on Corel images show the effectiveness of concept learning with the probabilistic MDA, and the improvement of the retrieval performance.
A challenging topic in content-based image retrieval is to determine the discriminant features that improve classification performance. An approach to learn concepts is by estimating mixture model for image databases using EM algorithm; however, this approach is impractical to be implemented for large databases due to the high dimensionality of the feature space. Based on the over-splitting nature of our EM algorithm and the Bayesian analysis of the multiple users' labelling information derived from their relevance feedbacks, we propose a probabilistic MDA to find the discriminating features, and integrate it with the EM framework. The experimental results on Corel images show the effectiveness of concept learning with the probabilistic MDA, and the improvement of the retrieval performance.
Active Concept Learning for Image Retrieval in Dynamic Databases
.png) Concept learning in content-based image retrieval (CBIR) systems is a challenging task. This paper presents an active concept learning approach based on mixture model to deal with the two basic aspects of a database system: changing (image insertion or removal) nature of a database and user queries. To achieve concept learning, we develop a novel model selection method based on Bayesian analysis that evaluates the consistency of hypothesized models with the available information. The analysis of exploitation vs. exploration in the search space helps to find optimal model efficiently. Experimental results on Corel database show the efficacy of our approach.
Concept learning in content-based image retrieval (CBIR) systems is a challenging task. This paper presents an active concept learning approach based on mixture model to deal with the two basic aspects of a database system: changing (image insertion or removal) nature of a database and user queries. To achieve concept learning, we develop a novel model selection method based on Bayesian analysis that evaluates the consistency of hypothesized models with the available information. The analysis of exploitation vs. exploration in the search space helps to find optimal model efficiently. Experimental results on Corel database show the efficacy of our approach.
Probabilistic Spatial Database Operations
.png) Spatial databases typically assume that the positional attributes of spatial objects are precisely known. In practice, however, they are known only approximately, with the error depending on the nature of the measurement and the source of data. In this paper, we address the problem how to perform spatial database operations in the presence of uncertainty. We first discuss a probabilistic spatial data model to represent the positional uncertainty. We then present a method for performing the probabilistic spatial join operations, which, given two uncertain data sets, find all pairs of polygons whose probability of overlap is larger than a given threshold. This method uses an R-tree based probabilistic index structure (PrR-tree) to support probabilistic filtering, and an efficient algorithm to compute the intersection probability between two uncertain polygons for the refinement step. Our experiments show that our method achieves higher accuracy than methods based on traditional spatial joins, while reducing overall cost by a factor of more than two.
Spatial databases typically assume that the positional attributes of spatial objects are precisely known. In practice, however, they are known only approximately, with the error depending on the nature of the measurement and the source of data. In this paper, we address the problem how to perform spatial database operations in the presence of uncertainty. We first discuss a probabilistic spatial data model to represent the positional uncertainty. We then present a method for performing the probabilistic spatial join operations, which, given two uncertain data sets, find all pairs of polygons whose probability of overlap is larger than a given threshold. This method uses an R-tree based probabilistic index structure (PrR-tree) to support probabilistic filtering, and an efficient algorithm to compute the intersection probability between two uncertain polygons for the refinement step. Our experiments show that our method achieves higher accuracy than methods based on traditional spatial joins, while reducing overall cost by a factor of more than two.
Concept learning and transplantation for dynamic image databases
.png) The task of a content-based image retrieval (CBIR) system is to cater to users who ezpect to get relevant images with high precision and eficiency in response to query images. This paper presents a concept learning approach that integrates a mixture model of the data, relevance feedback and long-term continuous learning. The concepts are incrementally refined with increased retrieval ezperiences. The concept knowledge can be immediately tmnsplanted to deal with the dynamic database situations such as insertion of new images, removal of ensting images and query images which are outside the database. Experimental results on Core1 database show the eficacy of our approach.
The task of a content-based image retrieval (CBIR) system is to cater to users who ezpect to get relevant images with high precision and eficiency in response to query images. This paper presents a concept learning approach that integrates a mixture model of the data, relevance feedback and long-term continuous learning. The concepts are incrementally refined with increased retrieval ezperiences. The concept knowledge can be immediately tmnsplanted to deal with the dynamic database situations such as insertion of new images, removal of ensting images and query images which are outside the database. Experimental results on Core1 database show the eficacy of our approach.
A New Semi-Supervised EM Algorithm for Image Retrieval
 One of the main tasks in content-based image retrieval
(CBIR) is to reduce the gap between low-level visual
features and high-level human concepts. This research
presents a new semi-supervised EM algorithm (NSSEM),
where the image distribution in feature space is
modeled as a mixture of Gaussian densities. Due to
the statistical mechanism of accumulating and processing
meta knowledge, the NSS-EM algorithm with longterm
learning of mixture model parameters can deal
with the cases where users may mislabel images during
relevance feedback. Our approach that integrates
mixture model of the data, relevance feedback and longterm
learning helps to improve retrieval performance.
The concept learning is incrementally refined with increased
retrieval experiences. Experiment results on
Corel database show the efficacy of our proposed concept
learning approach.
One of the main tasks in content-based image retrieval
(CBIR) is to reduce the gap between low-level visual
features and high-level human concepts. This research
presents a new semi-supervised EM algorithm (NSSEM),
where the image distribution in feature space is
modeled as a mixture of Gaussian densities. Due to
the statistical mechanism of accumulating and processing
meta knowledge, the NSS-EM algorithm with longterm
learning of mixture model parameters can deal
with the cases where users may mislabel images during
relevance feedback. Our approach that integrates
mixture model of the data, relevance feedback and longterm
learning helps to improve retrieval performance.
The concept learning is incrementally refined with increased
retrieval experiences. Experiment results on
Corel database show the efficacy of our proposed concept
learning approach.
Exploitation of meta knowledge for learning visual concepts
.png) The paper proposes a content-based image retrieval system which can learn visual concepts and refine them incrementally with increased retrieval experiences captured over time. The approach consists of using fuzzy clustering for learning concepts in conjunction with statistical learning for computing "relevance" weights of features used to represent images in the database. As the clusters become relatively stable and correspond to human concept distribution, the system can yield fast retrievals with higher precision. The paper presents a discussion on problems such as the system mistakenly indentifying a concept, a large number of trials to achieve clustering, etc. Experiments on synthetic data and real image database demonstrate the efficacy of this approach.
The paper proposes a content-based image retrieval system which can learn visual concepts and refine them incrementally with increased retrieval experiences captured over time. The approach consists of using fuzzy clustering for learning concepts in conjunction with statistical learning for computing "relevance" weights of features used to represent images in the database. As the clusters become relatively stable and correspond to human concept distribution, the system can yield fast retrievals with higher precision. The paper presents a discussion on problems such as the system mistakenly indentifying a concept, a large number of trials to achieve clustering, etc. Experiments on synthetic data and real image database demonstrate the efficacy of this approach.
A triplet based approach for indexing of fingerprint database for identification
.png) This paper presents a model-based approach, which efficiently retrieves correct hypotheses using properties of triangles formed by the triplets of minutiae as the basic representation unit. We show that the uncertainty of minutiae locations associated with feature extraction and shear does not affect the angles of a triangle arbitrarily. Geometric constraints based on characteristics of minutiae are used to eliminate erroneous correspondences. We present an analysis to characterize the discriminating power of our indexing approach. Experimental results on fingerprint images of varying quality show that our approach efficiently narrows down the number of candidate hypotheses in the presence of translation, rotation, scale, shear, occlusion and clutter.
This paper presents a model-based approach, which efficiently retrieves correct hypotheses using properties of triangles formed by the triplets of minutiae as the basic representation unit. We show that the uncertainty of minutiae locations associated with feature extraction and shear does not affect the angles of a triangle arbitrarily. Geometric constraints based on characteristics of minutiae are used to eliminate erroneous correspondences. We present an analysis to characterize the discriminating power of our indexing approach. Experimental results on fingerprint images of varying quality show that our approach efficiently narrows down the number of candidate hypotheses in the presence of translation, rotation, scale, shear, occlusion and clutter.
Independent Feature Analysis for Image Retrieval
 Content-based image retrieval methods based on the Euclidean metric expect the feature space to be
isotropic. They suffer from unequal differential relevance of features in computing the similarity between
images in the input feature space. We propose a learning method that attempts to overcome this limitation
by capturing local differential relevance of features based on user feedback. This feedback is used to locally
estimate the strength
of features along each dimension while taking into consideration the correlation between features.
In addition to exploring and exploiting local principal information, the system
seeks a global space for efficient independent feature analysis by combining such local information.
Content-based image retrieval methods based on the Euclidean metric expect the feature space to be
isotropic. They suffer from unequal differential relevance of features in computing the similarity between
images in the input feature space. We propose a learning method that attempts to overcome this limitation
by capturing local differential relevance of features based on user feedback. This feedback is used to locally
estimate the strength
of features along each dimension while taking into consideration the correlation between features.
In addition to exploring and exploiting local principal information, the system
seeks a global space for efficient independent feature analysis by combining such local information.
Feature relevance estimation for image databases
.png) Content-based image retrieval methods based on the Euclidean metric expect the feature space to be isotropic. They suffer from unequal differential relevance of features in computing the similarity between images in the input feature space. We propose a learning method that attempts to overcome this limitation by capturing local differential relevance of features based on user feedback. This feedback, in the form of accept or reject examples generated in response to a query image, is used to locally estimate the strength of features along each dimension. This results in local neighborhoods that are constricted along feature dimensions that are most relevant, while enlongated along less relevant ones. We provide experimental results that demonstrate the efficacy of our technique using real-world data.
Content-based image retrieval methods based on the Euclidean metric expect the feature space to be isotropic. They suffer from unequal differential relevance of features in computing the similarity between images in the input feature space. We propose a learning method that attempts to overcome this limitation by capturing local differential relevance of features based on user feedback. This feedback, in the form of accept or reject examples generated in response to a query image, is used to locally estimate the strength of features along each dimension. This results in local neighborhoods that are constricted along feature dimensions that are most relevant, while enlongated along less relevant ones. We provide experimental results that demonstrate the efficacy of our technique using real-world data.
Probabilistic Feature Relevance Learning for Content-Based Image Retrieval
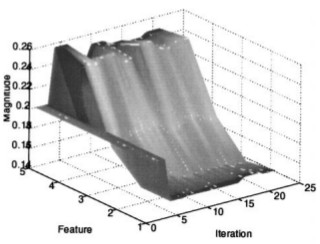 Most of the current image retrieval systems use “one-shot” queries to a database to retrieve
similar images. Typically a K-nearest neighbor kind of algorithm is used, where weights measuring
feature importance along each input dimension remain fixed (or manually tweaked by the user), in the
computation of a given similarity metric. In this
paper, we present a novel probabilistic method that enables image retrieval procedures to automatically
capture feature relevance based on user's feedback and that is highly adaptive to query locations. Experimental
results are presented that demonstrate the efficacy of our technique using both simulated and real-world data.
Most of the current image retrieval systems use “one-shot” queries to a database to retrieve
similar images. Typically a K-nearest neighbor kind of algorithm is used, where weights measuring
feature importance along each input dimension remain fixed (or manually tweaked by the user), in the
computation of a given similarity metric. In this
paper, we present a novel probabilistic method that enables image retrieval procedures to automatically
capture feature relevance based on user's feedback and that is highly adaptive to query locations. Experimental
results are presented that demonstrate the efficacy of our technique using both simulated and real-world data.
|


