Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi klrd takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
DYFUSION: Dynamic IR/RGB fusion for maritime vessel recognition
.png) We propose a novel multi-sensor data fusion approach called DyFusion for maritime vessel recognition using long-wave infrared and visible images. DyFusion consists of a decision level fusion of convolutional networks using a probabilistic model that can adapt to changes in the scene. The probabilistic model avails of contextual clues from each sensor decision pipeline to maximize accuracy and to update probabilities given to each sensor pipeline. Additional sensors are simulated by applying simple transformations on visible images. Evaluation is presented on the VAIS dataset, demonstrating the effectiveness and robustness of DyFusion with a reliable accuracy of up to 88% in hard scenarios.
We propose a novel multi-sensor data fusion approach called DyFusion for maritime vessel recognition using long-wave infrared and visible images. DyFusion consists of a decision level fusion of convolutional networks using a probabilistic model that can adapt to changes in the scene. The probabilistic model avails of contextual clues from each sensor decision pipeline to maximize accuracy and to update probabilities given to each sensor pipeline. Additional sensors are simulated by applying simple transformations on visible images. Evaluation is presented on the VAIS dataset, demonstrating the effectiveness and robustness of DyFusion with a reliable accuracy of up to 88% in hard scenarios.
A dense flow-based framework for real-time object registration under compound motion
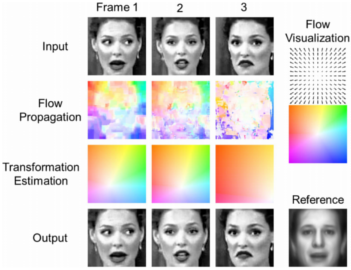 Tracking and measuring surface deformation while the object itself is also moving was a challenging, yet important problem in many video analysis tasks. For example, video-based facial expression recognition required tracking non-rigid motions of facial features without being affected by any rigid motions of the head. Presented is a generic video alignment framework to extract and characterize surface deformations accompanied by rigid-body motions with respect to a fixed reference (a canonical form). Also proposed is a generic model for object alignment in a Bayesian framework, and rigorously showed that a special case of the model results in a SIFT flow and optical flow based least-square problem. The proposed algorithm was evaluated on three applications, including the analysis of subtle facial muscle dynamics in spontaneous expressions, face image super-resolution, and generic object registration.
Tracking and measuring surface deformation while the object itself is also moving was a challenging, yet important problem in many video analysis tasks. For example, video-based facial expression recognition required tracking non-rigid motions of facial features without being affected by any rigid motions of the head. Presented is a generic video alignment framework to extract and characterize surface deformations accompanied by rigid-body motions with respect to a fixed reference (a canonical form). Also proposed is a generic model for object alignment in a Bayesian framework, and rigorously showed that a special case of the model results in a SIFT flow and optical flow based least-square problem. The proposed algorithm was evaluated on three applications, including the analysis of subtle facial muscle dynamics in spontaneous expressions, face image super-resolution, and generic object registration.
Segmentation of pollen tube growth videos using dynamic bi-modal fusion and seam carving
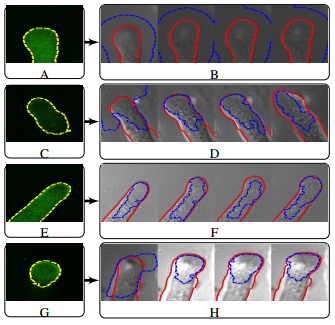
 A new automated technique is presented for boundary detection by fusing fluorescence and brightfield images, and a new efficient method of obtaining the final cell boundary through the process of Seam Carving is proposed. This approach took advantage of the nature of the fusion process and also the shape of the pollen tube to efficiently search for the optimal cell boundary. In video segmentation, the first two frames were used to initialize the segmentation process by creating a search space based on a parametric model of the cell shape. Updates to the search space were performed based on the location of past segmentations and a prediction of the next segmentation.
A new automated technique is presented for boundary detection by fusing fluorescence and brightfield images, and a new efficient method of obtaining the final cell boundary through the process of Seam Carving is proposed. This approach took advantage of the nature of the fusion process and also the shape of the pollen tube to efficiently search for the optimal cell boundary. In video segmentation, the first two frames were used to initialize the segmentation process by creating a search space based on a parametric model of the cell shape. Updates to the search space were performed based on the location of past segmentations and a prediction of the next segmentation.
Dynamic Bi-modal fusion of images for segmentation of pollen tubes in video
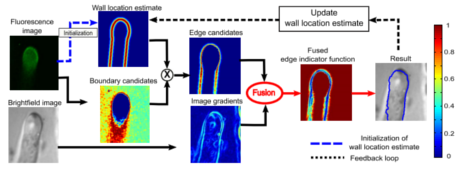
 Biologists studied pollen tube growth to understand how internal cell dynamics affected observable structural characteristics like cell diameter, length, and growth rate. Fluorescence microscopy was used to study the dynamics of internal proteins and ions, but this often produced images with missing parts of the pollen tube. Brightfield microscopy provided a low-cost way of obtaining structural information about the pollen tube, but the images were crowded with false edges. We proposed a dynamic segmentation fusion scheme that used both Bright-Field and Fluorescence images of growing pollen tubes to get a unified segmentation. Knowledge of the image formation process was used to create an initial estimate of the location of the cell boundary. Fusing this estimate with an edge indicator function amplified desired edges and attenuated undesired edges. The cell boundary was obtained using Level Set evolution on the fused edge indicator function.
Biologists studied pollen tube growth to understand how internal cell dynamics affected observable structural characteristics like cell diameter, length, and growth rate. Fluorescence microscopy was used to study the dynamics of internal proteins and ions, but this often produced images with missing parts of the pollen tube. Brightfield microscopy provided a low-cost way of obtaining structural information about the pollen tube, but the images were crowded with false edges. We proposed a dynamic segmentation fusion scheme that used both Bright-Field and Fluorescence images of growing pollen tubes to get a unified segmentation. Knowledge of the image formation process was used to create an initial estimate of the location of the cell boundary. Fusing this estimate with an edge indicator function amplified desired edges and attenuated undesired edges. The cell boundary was obtained using Level Set evolution on the fused edge indicator function.
Improving Action Units Recognition Using Dense Flow-based Face Registration in Video
 Aligning faces with non-rigid muscle motion in
the real-world streaming video is a challenging problem. We
propose a novel automatic video-based face registration architecture for facial expression recognition. The registration
process is formulated as a dense SIFT-flow- and optical-flow-
based affine warping problem. We start off by estimating the
transformation of an arbitrary face to a generic reference
face with canonical pose. This initialization in our framework
establishes a head pose and person independent face model. The
affine transformation computed from the initialization is then
propagated by affine transformation estimated from the dense
optical flow to guarantee the temporal smoothness of the non-
rigid facial appearance. We call this method SIFT and optical
flow affine image transform (SOFAIT). This real-time algorithm
is designed for realistic streaming data, allowing us to analyze
the facial muscle dynamics in a meaningful manner. Visual and
quantitative results demonstrate that the proposed automatic
video-based face registration technique captures the appearance
changes in spontaneous expressions and outperforms the state-
of-the-art technique.
Aligning faces with non-rigid muscle motion in
the real-world streaming video is a challenging problem. We
propose a novel automatic video-based face registration architecture for facial expression recognition. The registration
process is formulated as a dense SIFT-flow- and optical-flow-
based affine warping problem. We start off by estimating the
transformation of an arbitrary face to a generic reference
face with canonical pose. This initialization in our framework
establishes a head pose and person independent face model. The
affine transformation computed from the initialization is then
propagated by affine transformation estimated from the dense
optical flow to guarantee the temporal smoothness of the non-
rigid facial appearance. We call this method SIFT and optical
flow affine image transform (SOFAIT). This real-time algorithm
is designed for realistic streaming data, allowing us to analyze
the facial muscle dynamics in a meaningful manner. Visual and
quantitative results demonstrate that the proposed automatic
video-based face registration technique captures the appearance
changes in spontaneous expressions and outperforms the state-
of-the-art technique.
Fusion of Multiple Trackers in Video Networks
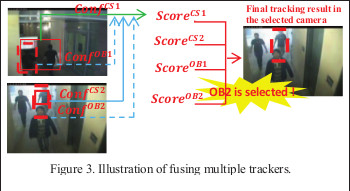 We address the camera selection
problem by fusing the performance of multiple trackers.
Currently, all the camera selection/hand-off approaches largely
depend on the performance of the tracker deployed to decide
when to hand-off from one camera to another. However, a slight
inaccuracy of the tracker may pass the wrong information to the
system such that the wrong camera may be selected and error
may be propagated. We present a novel approach to use multiple
state-of-the-art trackers based on different features and
principles to generate multiple hypotheses and fuse the
performance of multiple trackers for camera selection. The
proposed approach has very low computational overhead and
can achieve real-time performance. We perform experiments
with different numbers of cameras and persons on different
datasets to show the superior results of the proposed approach.
We also compare results with a single tracker to show the merits
of integrating results from multiple trackers.
We address the camera selection
problem by fusing the performance of multiple trackers.
Currently, all the camera selection/hand-off approaches largely
depend on the performance of the tracker deployed to decide
when to hand-off from one camera to another. However, a slight
inaccuracy of the tracker may pass the wrong information to the
system such that the wrong camera may be selected and error
may be propagated. We present a novel approach to use multiple
state-of-the-art trackers based on different features and
principles to generate multiple hypotheses and fuse the
performance of multiple trackers for camera selection. The
proposed approach has very low computational overhead and
can achieve real-time performance. We perform experiments
with different numbers of cameras and persons on different
datasets to show the superior results of the proposed approach.
We also compare results with a single tracker to show the merits
of integrating results from multiple trackers.
Ethnicity Classification Based on Gait Using Multi-view Fusion
 The determination of ethnicity of an individual, as a soft
biometric, can be very useful in a video-based surveillance
system. Currently, face is commonly used to determine the
ethnicity of a person. Up to now, gait has been used for
individual recognition and gender classification but not for
ethnicity determination. This research focuses on the ethnicity
determination based on fusion of multi-view gait. Gait Energy
Image (GEI) is used to analyze the recognition power
of gait for ethnicity. Feature fusion, score fusion and decision
fusion from multiple views of gait are explored. For
the feature fusion, GEI images and camera views are put
together to render a third-order tensor (x; y; view). A multilinear
principal component analysis (MPCA) is used to extract
features from tensor objects which integrate all views.
For the score fusion, the similarity scores measured from
single views are combined with a weighted SUM rule. For
the decision fusion, ethnicity classification is realized on
each individual view first. The classification results are then
combined to make the final determination with a majority
vote rule. A database of 36 walking people (East Asian
and South American) was acquired from 7 different camera
views. The experimental results show that ethnicity can
be determined from human gait in video automatically. The
classification rate is improved by fusing multiple camera
views and a comparison among different fusion schemes
shows that the MPCA based feature fusion performs the
best.
The determination of ethnicity of an individual, as a soft
biometric, can be very useful in a video-based surveillance
system. Currently, face is commonly used to determine the
ethnicity of a person. Up to now, gait has been used for
individual recognition and gender classification but not for
ethnicity determination. This research focuses on the ethnicity
determination based on fusion of multi-view gait. Gait Energy
Image (GEI) is used to analyze the recognition power
of gait for ethnicity. Feature fusion, score fusion and decision
fusion from multiple views of gait are explored. For
the feature fusion, GEI images and camera views are put
together to render a third-order tensor (x; y; view). A multilinear
principal component analysis (MPCA) is used to extract
features from tensor objects which integrate all views.
For the score fusion, the similarity scores measured from
single views are combined with a weighted SUM rule. For
the decision fusion, ethnicity classification is realized on
each individual view first. The classification results are then
combined to make the final determination with a majority
vote rule. A database of 36 walking people (East Asian
and South American) was acquired from 7 different camera
views. The experimental results show that ethnicity can
be determined from human gait in video automatically. The
classification rate is improved by fusing multiple camera
views and a comparison among different fusion schemes
shows that the MPCA based feature fusion performs the
best.
On the Performance Prediction and Validation for Multisensor Fusion
.png) Multiple sensors are commonly fused to improve the detection and recognition performance of computer vision and pattern recognition systems. The traditional approach to determine the optimal sensor combination is to try all possible sensor combinations by performing exhaustive experiments. In this paper, we present a theoretical approach that predicts the performance of sensor fusion that allows us to select the optimal combination. We start with the characteristics of each sensor by computing the match score and non-match score distributions of objects to be recognized. These distributions are modeled as a mixture of Gaussians. Then, we use an explicit Φ transformation that maps a receiver operating characteristic (ROC) curve to a straight line in 2-D space whose axes are related to the false alarm rate (F AR) and the Hit rate (Hit). Finally, using this representation, we derive a set of metrics to evaluate the sensor fusion performance and find the optimal sensor combination. We verify our prediction approach on the publicly available XM2VTS database as well as other databases.
Multiple sensors are commonly fused to improve the detection and recognition performance of computer vision and pattern recognition systems. The traditional approach to determine the optimal sensor combination is to try all possible sensor combinations by performing exhaustive experiments. In this paper, we present a theoretical approach that predicts the performance of sensor fusion that allows us to select the optimal combination. We start with the characteristics of each sensor by computing the match score and non-match score distributions of objects to be recognized. These distributions are modeled as a mixture of Gaussians. Then, we use an explicit Φ transformation that maps a receiver operating characteristic (ROC) curve to a straight line in 2-D space whose axes are related to the false alarm rate (F AR) and the Hit rate (Hit). Finally, using this representation, we derive a set of metrics to evaluate the sensor fusion performance and find the optimal sensor combination. We verify our prediction approach on the publicly available XM2VTS database as well as other databases.
Feature Fusion of Face and Gait for Human Recognition at a Distance in Video
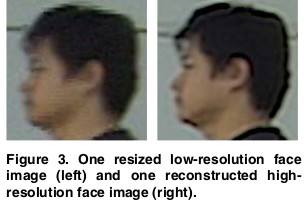 A new video based recognition method is presented
to recognize non-cooperating individuals at a distance in
video, who expose side views to the camera. Information
from two biometric sources, side face and gait, is utilized
and integrated at feature level. For face, a high-resolution
side face image is constructed from multiple video frames.
For gait, Gait Energy Image (GEI), a spatio-temporal compact
representation of gait in video, is used to characterize
human walking properties. Face features and gait features
are obtained separately using Principal Component Analysis
(PCA) and Multiple Discriminant Analysis (MDA) combined
method from the high-resolution side face image and
Gait Energy Image (GEI), respectively. The system is tested
on a database of video sequences corresponding to 46 people.
The results showed that the integrated face and gait
features carry the most discriminating power compared to
any individual biometric.
A new video based recognition method is presented
to recognize non-cooperating individuals at a distance in
video, who expose side views to the camera. Information
from two biometric sources, side face and gait, is utilized
and integrated at feature level. For face, a high-resolution
side face image is constructed from multiple video frames.
For gait, Gait Energy Image (GEI), a spatio-temporal compact
representation of gait in video, is used to characterize
human walking properties. Face features and gait features
are obtained separately using Principal Component Analysis
(PCA) and Multiple Discriminant Analysis (MDA) combined
method from the high-resolution side face image and
Gait Energy Image (GEI), respectively. The system is tested
on a database of video sequences corresponding to 46 people.
The results showed that the integrated face and gait
features carry the most discriminating power compared to
any individual biometric.
Global-to-Local Non-Rigid Shape Registration
 Non-rigid shape registration is an important issue in
computer vision. We present a novel global-to-
local procedure for aligning non-rigid shapes. The
global similarity transformation is obtained based on the
corresponding pairs found by matching shape context descriptors.
The local deformation is performed within an
optimization formulation, in which the bending energy of
thin plate spline transformation is incorporated as a regularization
term to keep the structure of the model shape
preserved under the shape deformation. The optimization
procedure drives the initial global registration towards the
target shape that results in the one-to-one correspondence
between the model and target shape. Experimental results
demonstrate the effectiveness of the proposed approach.
Non-rigid shape registration is an important issue in
computer vision. We present a novel global-to-
local procedure for aligning non-rigid shapes. The
global similarity transformation is obtained based on the
corresponding pairs found by matching shape context descriptors.
The local deformation is performed within an
optimization formulation, in which the bending energy of
thin plate spline transformation is incorporated as a regularization
term to keep the structure of the model shape
preserved under the shape deformation. The optimization
procedure drives the initial global registration towards the
target shape that results in the one-to-one correspondence
between the model and target shape. Experimental results
demonstrate the effectiveness of the proposed approach.
Hierarchical mutli-sensor image registration using evolutionary computation
.png) Image registration between multi-sensor imagery is a challenging problem due to the difficulties associated with finding a correspondence between pixels from images taken by the two sensors. However, the moving people in a static scene provide cues to address this problem. In this paper, we propose a hierarchical approach to automatically find the correspondence between the preliminary human silhouettes extracted from synchronous color and infrared (IR) image sequences for image registration using evolutionary computation. The proposed approach reduces the overall computational load without decreasing the final estimation accuracy. Experimental results show that the proposed approach achieves good results for image registration between color and IR imagery.
Image registration between multi-sensor imagery is a challenging problem due to the difficulties associated with finding a correspondence between pixels from images taken by the two sensors. However, the moving people in a static scene provide cues to address this problem. In this paper, we propose a hierarchical approach to automatically find the correspondence between the preliminary human silhouettes extracted from synchronous color and infrared (IR) image sequences for image registration using evolutionary computation. The proposed approach reduces the overall computational load without decreasing the final estimation accuracy. Experimental results show that the proposed approach achieves good results for image registration between color and IR imagery.
Tracking humans using multimodal fusion
.png) Human motion detection plays an important role in automated surveillance systems. However, it is challenging to detect non-rigid moving objects (e.g. human) robustly in a cluttered environment. In this paper, we compare two approaches for detecting walking humans using multi-modal measurementsvideo and audio sequences. The first approach is based on the Time-Delay Neural Network (TDNN), which fuses the audio and visual data at the feature level to detect the walking human. The second approach employs the Bayesian Network (BN) for jointly modeling the video and audio signals. Parameter estimation of the graphical models is executed using the Expectation-Maximization (EM) algorithm. And the location of the target is tracked by the Bayes inference. Experiments are performed in several indoor and outdoor scenarios: in the lab, more than one person walking, occlusion by bushes etc. The comparison of performance and efficiency of the two approaches are also presented.
Human motion detection plays an important role in automated surveillance systems. However, it is challenging to detect non-rigid moving objects (e.g. human) robustly in a cluttered environment. In this paper, we compare two approaches for detecting walking humans using multi-modal measurementsvideo and audio sequences. The first approach is based on the Time-Delay Neural Network (TDNN), which fuses the audio and visual data at the feature level to detect the walking human. The second approach employs the Bayesian Network (BN) for jointly modeling the video and audio signals. Parameter estimation of the graphical models is executed using the Expectation-Maximization (EM) algorithm. And the location of the target is tracked by the Bayes inference. Experiments are performed in several indoor and outdoor scenarios: in the lab, more than one person walking, occlusion by bushes etc. The comparison of performance and efficiency of the two approaches are also presented.
Moving Humans Detection Based on Multi-modal Sensor Fusion
 Moving object detection plays an important role in automated surveillance systems. However, it is
challenging to detect moving objects robustly in a cluttered environment. We propose an
approach for detecting humans using multi-modal measurements. The approach is based on using Time-Delay
Neural Netwrok (TDNN) to fuse the audio and video data at the feature level for detecting the walker with multiple
persons in the scene. The main contribution of this research is the introduction of Time-Delay Neural Network in
learning the relation between visual motion and step sounds of the walking person. Experimental results are presented.
Moving object detection plays an important role in automated surveillance systems. However, it is
challenging to detect moving objects robustly in a cluttered environment. We propose an
approach for detecting humans using multi-modal measurements. The approach is based on using Time-Delay
Neural Netwrok (TDNN) to fuse the audio and video data at the feature level for detecting the walker with multiple
persons in the scene. The main contribution of this research is the introduction of Time-Delay Neural Network in
learning the relation between visual motion and step sounds of the walking person. Experimental results are presented.
Cooperative coevolution fusion for moving object detection
.png) In this paper we introduce a novel sensor fusion algorithm based on the cooperative coevolutionary paradigm. We develop a multisensor robust moving object detection system that can operate under a variety of illumination and environmental conditions. Our experiments indicate that this evolutionary paradigm is well suited as a sensor fusion model and can be extended to different sensing modalities.
In this paper we introduce a novel sensor fusion algorithm based on the cooperative coevolutionary paradigm. We develop a multisensor robust moving object detection system that can operate under a variety of illumination and environmental conditions. Our experiments indicate that this evolutionary paradigm is well suited as a sensor fusion model and can be extended to different sensing modalities.
Adaptive Fusion for Diurnal Moving Object Detection
 Fusion of different sensor types (e.g. video, thermal infrared)
and sensor selection strategy at signal or pixel
level is a non-trivial task that requires a well-defined
structure. We provide a novel fusion architecture
that is flexible and can be adapted to different
types of sensors. The new fusion architecture provides an
elegant approach to integrating different sensing phenomenology,
sensor readings, and contextual information.
A cooperative coevolutionary method is introduced
for optimally selecting fusion strategies. We provide results
in the context of a moving object detection system
for a full 24 hours diurnal cycle in an outdoor environment.
The results indicate that our architecture is robust
to adverse illumination conditions and the evolutionary
paradigm can provide an adaptable and flexible method
for combining signals of different modality.
Fusion of different sensor types (e.g. video, thermal infrared)
and sensor selection strategy at signal or pixel
level is a non-trivial task that requires a well-defined
structure. We provide a novel fusion architecture
that is flexible and can be adapted to different
types of sensors. The new fusion architecture provides an
elegant approach to integrating different sensing phenomenology,
sensor readings, and contextual information.
A cooperative coevolutionary method is introduced
for optimally selecting fusion strategies. We provide results
in the context of a moving object detection system
for a full 24 hours diurnal cycle in an outdoor environment.
The results indicate that our architecture is robust
to adverse illumination conditions and the evolutionary
paradigm can provide an adaptable and flexible method
for combining signals of different modality.
Physics-based Cooperative Sensor Fusion for Moving Object Detection
 A robust moving object detection system for an outdoor
scene must be able to handle adverse illumination
conditions such as sudden illumination changes or lack of
illumination in a scene. This is of particular importance
for scenarios where active illumination cannot be relied
upon. Utilizing infrared and video sensors, we propose a
novel sensor fusion algorithm that automatically adapts
to the environmental changes that effect sensor measurements.
The adaptation is done through a new cooperative
coevolutionary algorithm that fuses the scene contextual
and statistical information through a physics-based
method. Our sensor fusion algorithm maintains high detection
rates under a variety of conditions and sensor
failure. The results are shown for a full 24 hour diurnal
cycle.
A robust moving object detection system for an outdoor
scene must be able to handle adverse illumination
conditions such as sudden illumination changes or lack of
illumination in a scene. This is of particular importance
for scenarios where active illumination cannot be relied
upon. Utilizing infrared and video sensors, we propose a
novel sensor fusion algorithm that automatically adapts
to the environmental changes that effect sensor measurements.
The adaptation is done through a new cooperative
coevolutionary algorithm that fuses the scene contextual
and statistical information through a physics-based
method. Our sensor fusion algorithm maintains high detection
rates under a variety of conditions and sensor
failure. The results are shown for a full 24 hour diurnal
cycle.
Detecting moving humans using color and infrared video
.png) We approach the task of human silhouette extraction from color and infrared video using automatic image registration. Image registration between color and thermal images is a challengingproblem due to the dificulties associated with finding correspondence. Howevel; the moving people in a static scene provide cues to address this problem. In this paper, we propose a hierarchical scheme to automatically find the correspondence between the preliminary human silhouettes extracted from color and infrared video for image registration. Next, we discuss some strategies for probabilistically combining cues from registered color and thermal images. It is shown that the proposed approach achieves good results for image registration and human silhouette extraction. Experimental results also show a comparison of sensor fusion strategies and demonstrate the improvement in performance for human silhouette extraction.
We approach the task of human silhouette extraction from color and infrared video using automatic image registration. Image registration between color and thermal images is a challengingproblem due to the dificulties associated with finding correspondence. Howevel; the moving people in a static scene provide cues to address this problem. In this paper, we propose a hierarchical scheme to automatically find the correspondence between the preliminary human silhouettes extracted from color and infrared video for image registration. Next, we discuss some strategies for probabilistically combining cues from registered color and thermal images. It is shown that the proposed approach achieves good results for image registration and human silhouette extraction. Experimental results also show a comparison of sensor fusion strategies and demonstrate the improvement in performance for human silhouette extraction.
Physics-based models of color and IR video for sensor fusion
.png) Physics based sensor fusion attempts to utilize the phenomenology of sensors to combine external conditions with data collected by the sensors into a global consistent dynamic representation. Although there have been a few approaches using this paradigm, it is still not entirely clear what kinds of physical models are appropriate for different sensing devices and conditions. We provide physical models that are suitable for the visible and infrared region of the spectrum. The physical models are described in detail. Moreover, the advantages and disadvantages of each model, their applicability, and guidelines for selecting the appropriate parameters are provided. Experimental results are also provided to indicate the applicability of the physical models.
Physics based sensor fusion attempts to utilize the phenomenology of sensors to combine external conditions with data collected by the sensors into a global consistent dynamic representation. Although there have been a few approaches using this paradigm, it is still not entirely clear what kinds of physical models are appropriate for different sensing devices and conditions. We provide physical models that are suitable for the visible and infrared region of the spectrum. The physical models are described in detail. Moreover, the advantages and disadvantages of each model, their applicability, and guidelines for selecting the appropriate parameters are provided. Experimental results are also provided to indicate the applicability of the physical models.
Multistrategy fusion using mixture model for moving object detection
.png) In a video surveillance domain, mixture models are used in conjunction with a variety of features and filters to detect and track moving objects. However, these systems do not provide clear performance results at the pixel detection level. In this paper, we apply the mixture model to provide several fusion strategies based on the competitive and cooperative principles of integration which we call OR, and AND strategies. In addition, we apply the Dempster-Shafer method to mixture models for object detection. Using two video databases, we show the performance of each fusion strategy using receiver operating characteristic (ROC) curves.
In a video surveillance domain, mixture models are used in conjunction with a variety of features and filters to detect and track moving objects. However, these systems do not provide clear performance results at the pixel detection level. In this paper, we apply the mixture model to provide several fusion strategies based on the competitive and cooperative principles of integration which we call OR, and AND strategies. In addition, we apply the Dempster-Shafer method to mixture models for object detection. Using two video databases, we show the performance of each fusion strategy using receiver operating characteristic (ROC) curves.
|


