
|

|
Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
3D Reconstruction of phase contrast images using focus measures
.png) In this paper, we present an approach for 3D phase-contrast microscopy using focus measure features. By using fluorescence data from the same location as the phase contrast data, we can train supervised regression algorithms to compute a depth map indicating the height of objects in imaged volume. From these depth maps, a 3D reconstruction of phase contrast images can be generated. This paper has shown the ability to reconstruct 3D phase contrast images using a variance metric inspired by all-in-focus methods. The proposed method has been used on A549 lung epithelial cells.
In this paper, we present an approach for 3D phase-contrast microscopy using focus measure features. By using fluorescence data from the same location as the phase contrast data, we can train supervised regression algorithms to compute a depth map indicating the height of objects in imaged volume. From these depth maps, a 3D reconstruction of phase contrast images can be generated. This paper has shown the ability to reconstruct 3D phase contrast images using a variance metric inspired by all-in-focus methods. The proposed method has been used on A549 lung epithelial cells.
Removing Moving Objects from Point Cloud Scenes
 Three-dimensional simultaneous localization and mapping is a topic of significant interest in the
research community, particularly so since the introduction of cheap consumer RGB-D sensors such
as the Microsoft Kinect. Current algorithms are able to create rich, visually appealing maps of indoor
environments using such sensors. However, state-of-the-art systems are designed for use in static
environments. This restriction means, for instance, that there can be no people moving around the
environment while the mapping is being done. This severely limits the application space for such systems.
To address this is-sue, we present an algorithm to explicitly identify and remove moving objects from
multiple views of a scene. We do this by finding corresponding objects in two views of a scene. If the
position of an object with respect to the other objects changes between the two views, we conclude
that the object is moving and should therefore be removed. After the algorithm is run, the two views
can be merged using any existing registration algorithm. We present results on scenes collected around
a university building.
Three-dimensional simultaneous localization and mapping is a topic of significant interest in the
research community, particularly so since the introduction of cheap consumer RGB-D sensors such
as the Microsoft Kinect. Current algorithms are able to create rich, visually appealing maps of indoor
environments using such sensors. However, state-of-the-art systems are designed for use in static
environments. This restriction means, for instance, that there can be no people moving around the
environment while the mapping is being done. This severely limits the application space for such systems.
To address this is-sue, we present an algorithm to explicitly identify and remove moving objects from
multiple views of a scene. We do this by finding corresponding objects in two views of a scene. If the
position of an object with respect to the other objects changes between the two views, we conclude
that the object is moving and should therefore be removed. After the algorithm is run, the two views
can be merged using any existing registration algorithm. We present results on scenes collected around
a university building.
3D Human Body Modeling Using Range Data
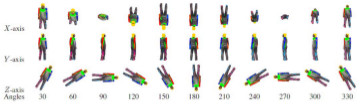 For the 3D modeling of walking humans the determination
of body pose and extraction of body parts, from
the sensed 3D range data, are challenging image processing
problems. Real body data may have holes because
of self-occlusions and grazing angle views. Most
of the existing modeling methods rely on direct fitting
a 3D model into the data without considering the fact
that the parts in an image are indeed the human body
parts. We present a method for 3D human
body modeling using range data that attempts to
overcome these problems. In our approach the entire
human body is first decomposed into major body parts
by a parts-based image segmentation method, and then
a kinematics model is fitted to the segmented body parts
in an optimized manner. The fitted model is adjusted by
the iterative closest point (ICP) algorithm to resolve the
gaps in the body data. Experimental results and comparisons
demonstrate the effectiveness of our approach.
For the 3D modeling of walking humans the determination
of body pose and extraction of body parts, from
the sensed 3D range data, are challenging image processing
problems. Real body data may have holes because
of self-occlusions and grazing angle views. Most
of the existing modeling methods rely on direct fitting
a 3D model into the data without considering the fact
that the parts in an image are indeed the human body
parts. We present a method for 3D human
body modeling using range data that attempts to
overcome these problems. In our approach the entire
human body is first decomposed into major body parts
by a parts-based image segmentation method, and then
a kinematics model is fitted to the segmented body parts
in an optimized manner. The fitted model is adjusted by
the iterative closest point (ICP) algorithm to resolve the
gaps in the body data. Experimental results and comparisons
demonstrate the effectiveness of our approach.
Efficient Recognition of Highly Similar 3D Objects in Range Images
 For rapid indexing and recognition of highly similar objects, we
introduce a novel method which combines feature embedding for the fast retrieval of surface descriptors,
novel similarity measures for correspondence, and a support vector machine-based learning technique for
ranking the hypotheses. By searching the nearest neighbors
in low dimensions, the similarity between a model-test pair is computed using the novel features. The
similarities for all model-test pairs are ranked using the learning algorithm to generate a short-list of candidate
models for verification. The verification is performed by aligning a model with the test object. The experimental
results, on the University of Notre Dame data set (302 subjects with 604 images) and the University of
California at Riverside data set (155 subjects with 902 images) which contain 3D human ears, are presented
and compared with the geometric hashing technique to demonstrate the efficiency and effectiveness of the
proposed approach.
For rapid indexing and recognition of highly similar objects, we
introduce a novel method which combines feature embedding for the fast retrieval of surface descriptors,
novel similarity measures for correspondence, and a support vector machine-based learning technique for
ranking the hypotheses. By searching the nearest neighbors
in low dimensions, the similarity between a model-test pair is computed using the novel features. The
similarities for all model-test pairs are ranked using the learning algorithm to generate a short-list of candidate
models for verification. The verification is performed by aligning a model with the test object. The experimental
results, on the University of Notre Dame data set (302 subjects with 604 images) and the University of
California at Riverside data set (155 subjects with 902 images) which contain 3D human ears, are presented
and compared with the geometric hashing technique to demonstrate the efficiency and effectiveness of the
proposed approach.
Recognition of Walking Humans in 3D: Initial Result
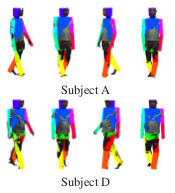 It has been challenging to recognize walking humans
at arbitrary poses from a single or small number of video
cameras. Attempts have been made mostly using a 2D
image/silhouette-based representation and a limited use of
3D kinematic model-based approaches. Unlike all the previous work in computer vision
and pattern recognition the models of walking humans
are built using the sensed 3D range data at selected poses
without any markers. An instance of a walking individual
at a different pose is recognized using the 3D range data at
that pose. Both modeling and recognition of an individual
are done using the dense 3D range data. The proposed approach
first measures 3D human body data that consists of
the representative poses during a gait cycle. Next, a 3D human
body model is fitted to the body data using an approach
that overcomes the inherent gaps in the data and estimates
the body pose with high accuracy. A gait sequence is synthesized
by interpolation of joint positions and their movements
from the fitted body models. Both dynamic and static
gait features are obtained which are used to define a similarity
measure for an individual recognition in the database.
The experimental results show high recognition rates using
our range based 3D gait database.
It has been challenging to recognize walking humans
at arbitrary poses from a single or small number of video
cameras. Attempts have been made mostly using a 2D
image/silhouette-based representation and a limited use of
3D kinematic model-based approaches. Unlike all the previous work in computer vision
and pattern recognition the models of walking humans
are built using the sensed 3D range data at selected poses
without any markers. An instance of a walking individual
at a different pose is recognized using the 3D range data at
that pose. Both modeling and recognition of an individual
are done using the dense 3D range data. The proposed approach
first measures 3D human body data that consists of
the representative poses during a gait cycle. Next, a 3D human
body model is fitted to the body data using an approach
that overcomes the inherent gaps in the data and estimates
the body pose with high accuracy. A gait sequence is synthesized
by interpolation of joint positions and their movements
from the fitted body models. Both dynamic and static
gait features are obtained which are used to define a similarity
measure for an individual recognition in the database.
The experimental results show high recognition rates using
our range based 3D gait database.
Super-resolved facial texture under changing pose and illumination
.png) In this paper, we propose a method to incrementally superresolve 3D facial texture by integrating information frame by frame from a video captured under changing poses and illuminations. First, we recover illumination, 3D motion and shape parameters from our tracking algorithm. This information is then used to super-resolve 3D texture using Iterative BackProjection (IBP) method. Finally, the super-resolved texture is fed back to the tracking part to improve the estimation of illumination and motion parameters. This closed-loop process continues to refine the texture as new frames come in. We also propose a local-region based scheme to handle non-rigidity of the human face. Experiments demonstrate that our framework not only incrementally super-resolves facial images, but recovers the detailed expression changes in high quality.
In this paper, we propose a method to incrementally superresolve 3D facial texture by integrating information frame by frame from a video captured under changing poses and illuminations. First, we recover illumination, 3D motion and shape parameters from our tracking algorithm. This information is then used to super-resolve 3D texture using Iterative BackProjection (IBP) method. Finally, the super-resolved texture is fed back to the tracking part to improve the estimation of illumination and motion parameters. This closed-loop process continues to refine the texture as new frames come in. We also propose a local-region based scheme to handle non-rigidity of the human face. Experiments demonstrate that our framework not only incrementally super-resolves facial images, but recovers the detailed expression changes in high quality.
3D Free-Form Object Recognition in Range Images Using Local Surface Patches
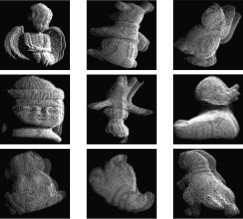 We introduce an integrated local surface descriptor
for surface representation and object recognition.
A local surface descriptor is defined by a centroid, its surface
type and 2D histogram. The 2D histogram consists
of shape indexes, calculated from principal curvatures, and
angles between the normal of reference point and that of its
neighbors. Instead of calculating local surface descriptors
for all the 3D surface points, we only calculate them for feature
points which are areas with large shape variation. Furthermore,
in order to speed up the search process and deal
with a large set of objects, model local surface patches are
indexed into a hash table. Given a set of test local surface
patches, we cast votes for models containing similar surface
descriptors. Potential corresponding local surface patches
and candidate models are hypothesized. Verification is performed
by aligning models with scenes for the most likely
models. Experiment results with real range data are presented
to demonstrate the effectiveness of our approach.
We introduce an integrated local surface descriptor
for surface representation and object recognition.
A local surface descriptor is defined by a centroid, its surface
type and 2D histogram. The 2D histogram consists
of shape indexes, calculated from principal curvatures, and
angles between the normal of reference point and that of its
neighbors. Instead of calculating local surface descriptors
for all the 3D surface points, we only calculate them for feature
points which are areas with large shape variation. Furthermore,
in order to speed up the search process and deal
with a large set of objects, model local surface patches are
indexed into a hash table. Given a set of test local surface
patches, we cast votes for models containing similar surface
descriptors. Potential corresponding local surface patches
and candidate models are hypothesized. Verification is performed
by aligning models with scenes for the most likely
models. Experiment results with real range data are presented
to demonstrate the effectiveness of our approach.
Performance evaluation and prediction for 3-D ear recognition
.png) Existing ear recognition approaches do not give theoretical or experimental performance prediction. Therefore, the discriminating power of ear biometric for human identification cannot be evaluated. This paper addresses two interrelated problems: (a) proposes an integrated local descriptor for representation to recognize human ears in 3D. Comparing local surface descriptors between a test and a model image, an initial correspondence of local surface patches is established and then filtered using simple geometric constraints. The performance of the proposed ear recognition system is evaluated on a real range image database of 52 subjects. (b) A binomial model is also presented to predict the ear recognition performance. Match and non-matched distances obtained from the database of 52 subjects are used to estimate the distributions. By modeling cumulative match characteristic (CMC) curve as a binomial distribution, the ear recognition performance can be predicted on a larger gallery.
Existing ear recognition approaches do not give theoretical or experimental performance prediction. Therefore, the discriminating power of ear biometric for human identification cannot be evaluated. This paper addresses two interrelated problems: (a) proposes an integrated local descriptor for representation to recognize human ears in 3D. Comparing local surface descriptors between a test and a model image, an initial correspondence of local surface patches is established and then filtered using simple geometric constraints. The performance of the proposed ear recognition system is evaluated on a real range image database of 52 subjects. (b) A binomial model is also presented to predict the ear recognition performance. Match and non-matched distances obtained from the database of 52 subjects are used to estimate the distributions. By modeling cumulative match characteristic (CMC) curve as a binomial distribution, the ear recognition performance can be predicted on a larger gallery.
Shape Model-Based 3D Ear Detection from Side Face Range Images
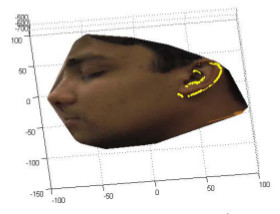 Ear detection is an important part of an ear recognition
system. We propose a shape model-based
technique for locating human ears in side face range images.
The ear shape model is represented by a set of discrete
3D vertices corresponding to ear helix and anti-helix parts.
Given side face range images, step edges are extracted considering
the fact that there are strong step edges around the
ear helix part. Then the edge segments are dilated, thinned
and grouped into different clusters which are potential regions
containing ears. For each cluster, we register the ear
shape model with the edges. The region with the minimum
mean registration error is declared as the detected ear region;
the ear helix and anti-helix parts are meanwhile identified.
Experiments are performed with a large number of
real face range images to demonstrate the effectiveness of
our approach. The contributions of this research are: (a) a
ear shape model for locating 3D ears in side face range images,
(b) an effective approach to detect human ears from
side face range images, (c) experimental results on a large
number of ear images.
Ear detection is an important part of an ear recognition
system. We propose a shape model-based
technique for locating human ears in side face range images.
The ear shape model is represented by a set of discrete
3D vertices corresponding to ear helix and anti-helix parts.
Given side face range images, step edges are extracted considering
the fact that there are strong step edges around the
ear helix part. Then the edge segments are dilated, thinned
and grouped into different clusters which are potential regions
containing ears. For each cluster, we register the ear
shape model with the edges. The region with the minimum
mean registration error is declared as the detected ear region;
the ear helix and anti-helix parts are meanwhile identified.
Experiments are performed with a large number of
real face range images to demonstrate the effectiveness of
our approach. The contributions of this research are: (a) a
ear shape model for locating 3D ears in side face range images,
(b) an effective approach to detect human ears from
side face range images, (c) experimental results on a large
number of ear images.
3-D free-form object recognition in range images using local surface patches
.png) This paper introduces an integrated local surface descriptor for surface representation and object recognition. A local surface descriptor is defined by a centroid, its surface type and 2D histogram. The 2D histogram consists of shape indexes, calculated from principal curvatures, and angles between the normal of reference point and that of its neighbors. Instead of calculating local surface descriptors for all the 3D surface points, we only calculate them for feature points which are areas with large shape variation. Furthermore, in order to speed up the search process and deal with a large set of objects, model local surface patches are indexed into a hash table. Given a set of test local surface patches, we cast votes for models containing similar surface descriptors. Potential corresponding local surface patches and candidate models are hypothesized. Verification is performed by aligning models with scenes for the most likely models. Experiment results with real range data are presented to demonstrate the effectiveness of our approach.
This paper introduces an integrated local surface descriptor for surface representation and object recognition. A local surface descriptor is defined by a centroid, its surface type and 2D histogram. The 2D histogram consists of shape indexes, calculated from principal curvatures, and angles between the normal of reference point and that of its neighbors. Instead of calculating local surface descriptors for all the 3D surface points, we only calculate them for feature points which are areas with large shape variation. Furthermore, in order to speed up the search process and deal with a large set of objects, model local surface patches are indexed into a hash table. Given a set of test local surface patches, we cast votes for models containing similar surface descriptors. Potential corresponding local surface patches and candidate models are hypothesized. Verification is performed by aligning models with scenes for the most likely models. Experiment results with real range data are presented to demonstrate the effectiveness of our approach.
Human Ear Recognition from Side Face Range Images
.png) Ear detection is an important part of an ear recognition system. In this paper we address human ear detection from side face range images. We introduce a simple and effective method to detect ears, which has two stages: offline model template building and on-line detection. The model template is represented by an averaged histogram of shape index. The on-line detection is a four-step process: step edge detection and thresholding, image dilation, connectcomponent labeling and template matching. Experiment results with real ear images are presented to demonstrate the effectiveness of our approach.
Ear detection is an important part of an ear recognition system. In this paper we address human ear detection from side face range images. We introduce a simple and effective method to detect ears, which has two stages: offline model template building and on-line detection. The model template is represented by an averaged histogram of shape index. The on-line detection is a four-step process: step edge detection and thresholding, image dilation, connectcomponent labeling and template matching. Experiment results with real ear images are presented to demonstrate the effectiveness of our approach.
Gabor Wavelet Representation for 3-D Object Recognition
 We present a model-based object recognition approach that uses a Gabor wavelet representation.
The Gabor grid, a
topology-preserving map, efficiently encodes both signal energy and structural information of an object in
a sparse multi-resolution representation. Grid erosion and repairing is
performed whenever a collapsed grid, due to object occlusion, is detected. The results on infrared
imagery are presented, where objects undergo rotation, translation, scale, occlusion, and aspect variations
under changing environmental conditions.
We present a model-based object recognition approach that uses a Gabor wavelet representation.
The Gabor grid, a
topology-preserving map, efficiently encodes both signal energy and structural information of an object in
a sparse multi-resolution representation. Grid erosion and repairing is
performed whenever a collapsed grid, due to object occlusion, is detected. The results on infrared
imagery are presented, where objects undergo rotation, translation, scale, occlusion, and aspect variations
under changing environmental conditions.
Generic Object Recognition using Multiple Representations
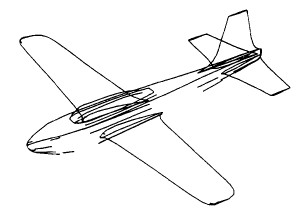 Real-world image understanding tasks often involve complex object models which are not adequately
represented by a single representational scheme for the various recognition scenarios encountered in
practice. Multiple representations, on the other hand, allow different matching strategies to be applied for
the same object, or even for different parts of the same object. This paper is concerned with the derivation
of hierarchical CAD models having multiple representations - concave/convex edges and straight
homogeneous generalized cylinder - and their use for generic object recognition in outdoor visible imagery.
Real-world image understanding tasks often involve complex object models which are not adequately
represented by a single representational scheme for the various recognition scenarios encountered in
practice. Multiple representations, on the other hand, allow different matching strategies to be applied for
the same object, or even for different parts of the same object. This paper is concerned with the derivation
of hierarchical CAD models having multiple representations - concave/convex edges and straight
homogeneous generalized cylinder - and their use for generic object recognition in outdoor visible imagery.
Building Hierarchical Vision Model of Objects with Multiple Representations
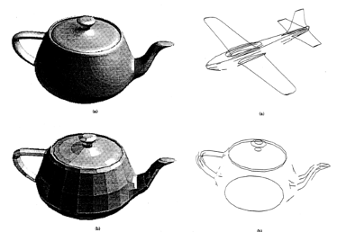 Building a hierarchical vision model of an object with multiple representations required two steps: decomposing the object into parts/subparts and obtaining appropriate representations, and constructing relational links between decomposed parts/subparts obtained in the first step. We described volume-based decomposition and surface-based decomposition of 3D objects into parts, where the objects were designed by a B-spline based geometric modeler called Alpha_1. Multiple-representation descriptions could be derived for each of these subparts using various techniques such as polygonal approximation , concave/convex, edge direction, curvature extrema and surface normals. For example, subparts of a hammer could be described by two generalized cylinders or one generalized cylinder and one polyhedron.
Building a hierarchical vision model of an object with multiple representations required two steps: decomposing the object into parts/subparts and obtaining appropriate representations, and constructing relational links between decomposed parts/subparts obtained in the first step. We described volume-based decomposition and surface-based decomposition of 3D objects into parts, where the objects were designed by a B-spline based geometric modeler called Alpha_1. Multiple-representation descriptions could be derived for each of these subparts using various techniques such as polygonal approximation , concave/convex, edge direction, curvature extrema and surface normals. For example, subparts of a hammer could be described by two generalized cylinders or one generalized cylinder and one polyhedron.
Recognition of 3-D Objects in Range Images using a Butterfly Multiprocessor
 The advent of Multiple Instruction Multiple Data (MIMD) architectures together with the potentially attractive application of range images for object recognition, motivated the development of a successful goal-directed 3-D object recognition system on a 18 node Butterfly multiprocessor. This system, which combined the use of range images, multiprocessing, and rule-based control in a unique manner, provided several new insights and data points into these research areas. First a new method of surface characterization that used a curvature graph was proposed, tested and found that by jointly using information provided by the principal curvatures, the potential existed for uniquely identifying a larger variety of surfaces than had previously been accomplished. Then, a 3-D surface-type data representation, coupled with the depth information available in range images, was used to correctly recognize and interpret occluded scenes. Finally, it was determined that both multiprocessing and a rule-guided/goal-directed search could be successfully combined in an object recognition system. Multiprocessing was employed both at the object level and within objects. This enabled the achievement of near linear speedups for scenes containing fewer objects than the number of available processors.
The advent of Multiple Instruction Multiple Data (MIMD) architectures together with the potentially attractive application of range images for object recognition, motivated the development of a successful goal-directed 3-D object recognition system on a 18 node Butterfly multiprocessor. This system, which combined the use of range images, multiprocessing, and rule-based control in a unique manner, provided several new insights and data points into these research areas. First a new method of surface characterization that used a curvature graph was proposed, tested and found that by jointly using information provided by the principal curvatures, the potential existed for uniquely identifying a larger variety of surfaces than had previously been accomplished. Then, a 3-D surface-type data representation, coupled with the depth information available in range images, was used to correctly recognize and interpret occluded scenes. Finally, it was determined that both multiprocessing and a rule-guided/goal-directed search could be successfully combined in an object recognition system. Multiprocessing was employed both at the object level and within objects. This enabled the achievement of near linear speedups for scenes containing fewer objects than the number of available processors.
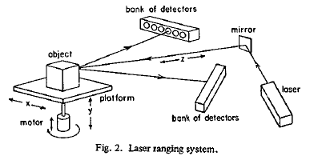
CAD-Based 3D Object Representation for Robot Vision
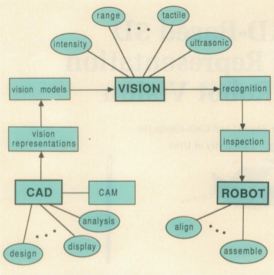 There are three key components in the automated manufacturing system shown in the figure : the CAD/CAM (computer-aided design/computer-aided manufacturing) system, the vision system, and the intelligent robot system. The CAD/CAM system supported the design, analysis, and manufacturing of each part of a product. The vision system integrated information from sensors such as TV cameras, laser range finders, tactile and ultrasonic sensors. It provided the robot with information about the working environment and the location, identity, and quality of the designed parts. The intelligent robot aligned the inspected parts and performed assembly operations using tactile and force-torque sensors.
There are three key components in the automated manufacturing system shown in the figure : the CAD/CAM (computer-aided design/computer-aided manufacturing) system, the vision system, and the intelligent robot system. The CAD/CAM system supported the design, analysis, and manufacturing of each part of a product. The vision system integrated information from sensors such as TV cameras, laser range finders, tactile and ultrasonic sensors. It provided the robot with information about the working environment and the location, identity, and quality of the designed parts. The intelligent robot aligned the inspected parts and performed assembly operations using tactile and force-torque sensors.
CAD-Based Robotics
 Described is an approach which facilitated and made explicit the organization of the knowledge necessary to map robotic system requirements onto an appropriate assembly of algorithms, processors, sensors, and actuators. We describe a system under development which exploited the Computer Aided Design (CAD) database in order to synthesize: recognition code for vision systems (both 2D and 3D), grasping sites for simple parallel grippers, and manipulation strategies for dextrous manipulation. We used an object based approach and give an example application of the system to CAD-based 2-D vision.
Described is an approach which facilitated and made explicit the organization of the knowledge necessary to map robotic system requirements onto an appropriate assembly of algorithms, processors, sensors, and actuators. We describe a system under development which exploited the Computer Aided Design (CAD) database in order to synthesize: recognition code for vision systems (both 2D and 3D), grasping sites for simple parallel grippers, and manipulation strategies for dextrous manipulation. We used an object based approach and give an example application of the system to CAD-based 2-D vision.
CAD Based 3D Models for Computer Vision
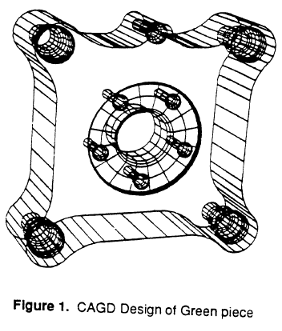
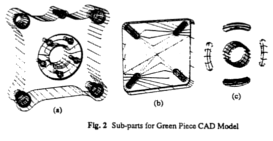 Model based recognition was one of the key paradigms in computer vision and pattern recognition, however, there was an absence of systematic approach for building geometrical and functional model for a large class of 3D objects used in industrial environments. A Computer-Aided Design (CAD) based approach for building 3D models which was be used for the recognition and manipulation of 3D objects for computer vision applications is presented. We present the details of the design on a relatively simple object named “Green Piece” and the complex automobile part, “Renault Piece” used in computer vision and pattern recognition research. We also present examples on the derivation of four different representations (surface points, surface curvatures, edges, arcs and local features, and volumes and sweeps) from the CAD designs so as to build computer vision systems capable of handling multi-class objects and employing multiple representations.
Model based recognition was one of the key paradigms in computer vision and pattern recognition, however, there was an absence of systematic approach for building geometrical and functional model for a large class of 3D objects used in industrial environments. A Computer-Aided Design (CAD) based approach for building 3D models which was be used for the recognition and manipulation of 3D objects for computer vision applications is presented. We present the details of the design on a relatively simple object named “Green Piece” and the complex automobile part, “Renault Piece” used in computer vision and pattern recognition research. We also present examples on the derivation of four different representations (surface points, surface curvatures, edges, arcs and local features, and volumes and sweeps) from the CAD designs so as to build computer vision systems capable of handling multi-class objects and employing multiple representations.
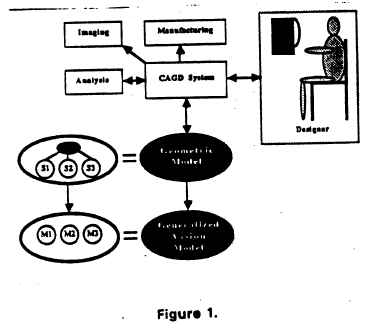
CAGD-Based 3D Visual Recognition
 A coherent automated manufacturing system needed to include CAD/CAM, computer vision, and object manipulation. Most systems which supported CAD/CAM did not provide for vision or manipulation and similarly, vision and manipulation systems incorporated no explicit relation to CAD/CAM models. CAD/CAM systems emerged which allowed the designer to conceive and model an object and automatically manufacture the object to prescribed specifications but if recognition or manipulation was to be performed, existing vision systems relied on models generated in an ad hoc manner for the vision or recognition process. Although both Vision and CAD/CAM systems relied on models of the objects involved, different modeling schemes were used in each case. A more unified system allowed vision models to be generated from the CAD database. We implemented a framework where objects were designed using an existing CAGD system and recognition strategies based on these design models were used for visual recognition and manipulation.
A coherent automated manufacturing system needed to include CAD/CAM, computer vision, and object manipulation. Most systems which supported CAD/CAM did not provide for vision or manipulation and similarly, vision and manipulation systems incorporated no explicit relation to CAD/CAM models. CAD/CAM systems emerged which allowed the designer to conceive and model an object and automatically manufacture the object to prescribed specifications but if recognition or manipulation was to be performed, existing vision systems relied on models generated in an ad hoc manner for the vision or recognition process. Although both Vision and CAD/CAM systems relied on models of the objects involved, different modeling schemes were used in each case. A more unified system allowed vision models to be generated from the CAD database. We implemented a framework where objects were designed using an existing CAGD system and recognition strategies based on these design models were used for visual recognition and manipulation.
Computer Aided Geometric Design Based 3D Models for Machine Vision
 Model based recognition was one of the key paradigms in computer vision and pattern recognition, however, there was an absence of a systematic approach for building geometrical and functional models for a large class of 3D objects used in industrial environments. Presented is a Computer Aided Geometric Design (CAGD) based approach for building 3D models which could be used for the recognition and manipulation of 3D objects for industrial machine vision applications. We present the details of the design on a relatively simple object named “Green Piece”, and the complex automobile “Renault Piece” used in the computer vision and pattern recognition community. An algorithm which used the above geometric design and allowed the points on the surface of the object to be sampled at the desired resolution, thus allowing the construction of multiresolution 3D models, is presented. The resulting data structure of points included coordinates of the points in 3D space, surface normals and information about the neighboring points.
Model based recognition was one of the key paradigms in computer vision and pattern recognition, however, there was an absence of a systematic approach for building geometrical and functional models for a large class of 3D objects used in industrial environments. Presented is a Computer Aided Geometric Design (CAGD) based approach for building 3D models which could be used for the recognition and manipulation of 3D objects for industrial machine vision applications. We present the details of the design on a relatively simple object named “Green Piece”, and the complex automobile “Renault Piece” used in the computer vision and pattern recognition community. An algorithm which used the above geometric design and allowed the points on the surface of the object to be sampled at the desired resolution, thus allowing the construction of multiresolution 3D models, is presented. The resulting data structure of points included coordinates of the points in 3D space, surface normals and information about the neighboring points.
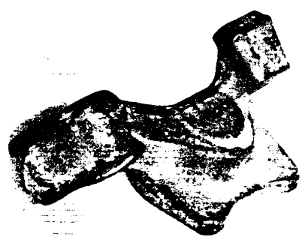
Intrinsic Characteristics as the Interface Between CAD and Machine Vision Systems
 Computer Aided Design systems were being used to drive machine vision analysis making it possible to produce recognition and analysis procedures without having to scan a physical example of the object. Typically, these proposed techniques either directly used whatever the CAD model produced or derived information (e.g. points sampled on the surface of the object) to drive a particular recognition scheme and in this regard, there had been some discussion as to an appropriate set of interface data (e.g. points, surface patches, features, etc.). We proposed that a coherent general solution to this problem was to characterize a CAD system by the set of intrinsic 3D shape characteristics (e.g. surface normals, texture, reflectance properties, curvature, etc.) that the CAD system was able to provide. Such a characterization made it possible to compare CAD systems irrespective of recognition paradigms, and actually made it possible to determine which recognition strategies could be used with a given CAD-based machine vision system. Given a set of intrinsic characteristics, techniques, and algorithms could be developed which allowed the generation of computer representations and geometric models of complicated realizable 3D objects in a systematic manner. Utilizing the shape information characterized by these intrinsic features and knowledge of existing recognition paradigms, scene analysis strategies (and executable code) could be directly generated.
Computer Aided Design systems were being used to drive machine vision analysis making it possible to produce recognition and analysis procedures without having to scan a physical example of the object. Typically, these proposed techniques either directly used whatever the CAD model produced or derived information (e.g. points sampled on the surface of the object) to drive a particular recognition scheme and in this regard, there had been some discussion as to an appropriate set of interface data (e.g. points, surface patches, features, etc.). We proposed that a coherent general solution to this problem was to characterize a CAD system by the set of intrinsic 3D shape characteristics (e.g. surface normals, texture, reflectance properties, curvature, etc.) that the CAD system was able to provide. Such a characterization made it possible to compare CAD systems irrespective of recognition paradigms, and actually made it possible to determine which recognition strategies could be used with a given CAD-based machine vision system. Given a set of intrinsic characteristics, techniques, and algorithms could be developed which allowed the generation of computer representations and geometric models of complicated realizable 3D objects in a systematic manner. Utilizing the shape information characterized by these intrinsic features and knowledge of existing recognition paradigms, scene analysis strategies (and executable code) could be directly generated.
Range Data Processing: Representation of Surface by Edges
 Representation of surfaces by edges was an important and integral part of a robust 3D model based recognition scheme because edges in a range image described the intrinsic characteristics about the shape of objects. Presented are three approaches for detecting edges in 3D range data based on computing the gradient, fitting 3D lines to a set of points, and detecting changes in the direction of unit normal vectors on the surface. These approaches were applied locally in a small neighborhood of the point. The neighbors of a 3D point were found by using the k-d tree algorithm. As compared to previous work on range image processing, the approaches presented here were applicable not only to sense range data corresponding to any one view of the scene, but also to 3D model data obtained by using the Computer-Aided Geometric Design (CAGD) techniques or the 3D model data obtained by combining several views of the sense object. A comparison of the techniques is presented and their performance is evaluated with respect to signal-to-noise ratio.
Representation of surfaces by edges was an important and integral part of a robust 3D model based recognition scheme because edges in a range image described the intrinsic characteristics about the shape of objects. Presented are three approaches for detecting edges in 3D range data based on computing the gradient, fitting 3D lines to a set of points, and detecting changes in the direction of unit normal vectors on the surface. These approaches were applied locally in a small neighborhood of the point. The neighbors of a 3D point were found by using the k-d tree algorithm. As compared to previous work on range image processing, the approaches presented here were applicable not only to sense range data corresponding to any one view of the scene, but also to 3D model data obtained by using the Computer-Aided Geometric Design (CAGD) techniques or the 3D model data obtained by combining several views of the sense object. A comparison of the techniques is presented and their performance is evaluated with respect to signal-to-noise ratio.
3D Model Building Using CAGD Techniques
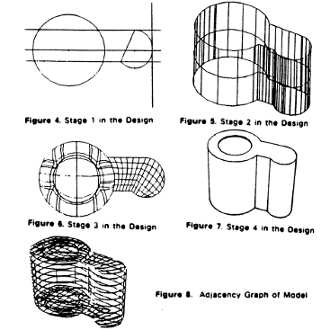 Work using Computer Aided Geometric Design (CAGD) representations and models as a basis for the visual recognition of 3D objects for robotic applications is presented. We describe some techniques and algorithms which allowed the generation of computer representations and geometric models of complicated realizable 3D objects in a systematic manner. These representations and models were obtained using available CAGD techniques and data acquired from various range finding techniques. As compared to previous work in machine vision, multiple hierarchical representations of an object obtained from geometric models could be used for finding orientation and position information.
Work using Computer Aided Geometric Design (CAGD) representations and models as a basis for the visual recognition of 3D objects for robotic applications is presented. We describe some techniques and algorithms which allowed the generation of computer representations and geometric models of complicated realizable 3D objects in a systematic manner. These representations and models were obtained using available CAGD techniques and data acquired from various range finding techniques. As compared to previous work in machine vision, multiple hierarchical representations of an object obtained from geometric models could be used for finding orientation and position information.
CAGD Based 3D Vision
 The initial results of our work using Computer Aided Geometric Design (CAGD) representations and models as a basis for the visual recognition of 3D objects for robotic applications are presented. We describe some techniques and algorithms which allowed the generation of computer representations and geometric models of complicated realizable 3D objects in a systematic manner. These representations and models were obtained using available CAGD techniques, and data acquired from various range finding techniques. As compared to previous work in machine vision, multiple hierarchical representations of an object obtained from geometric models could be used for finding orientation and position information.
The initial results of our work using Computer Aided Geometric Design (CAGD) representations and models as a basis for the visual recognition of 3D objects for robotic applications are presented. We describe some techniques and algorithms which allowed the generation of computer representations and geometric models of complicated realizable 3D objects in a systematic manner. These representations and models were obtained using available CAGD techniques, and data acquired from various range finding techniques. As compared to previous work in machine vision, multiple hierarchical representations of an object obtained from geometric models could be used for finding orientation and position information.
Vision Analysis Using Computer Aided Geometric Models
 The use of CAD/CAM models in the visual recognition of objects for robotic application is presented. As compared to previous work in machine vision, multiple hierarchical representations of an object obtained from geometric models were used for finding orientation and position information. Thus, design models were used to drive the vision analysis.
The use of CAD/CAM models in the visual recognition of objects for robotic application is presented. As compared to previous work in machine vision, multiple hierarchical representations of an object obtained from geometric models were used for finding orientation and position information. Thus, design models were used to drive the vision analysis.
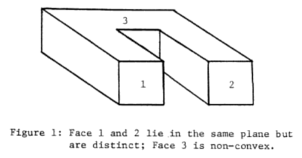
Representation and Shape Matching of 3D Objects
 A three-dimensional scene analysis system for the shape matching of real world 3D objects is presented. Various issues related to representation and modeling of 3D objects is addressed and a method for the approximation of 3D objects by a set of planar faces is discussed. The major advantage of this method is that it was applicable to a complete object and was not restricted to a single range view which was the limitation of the previous work in 3D scene analysis. The method was a sequential region growing algorithm and was not applied to range images, but rather to a set of 3D points. The 3D model of an object was obtained by combining the object points from a sequence of range data images corresponding to various views of the object, applying the necessary transformations and then approximating the surface by polygons. A stochastic labeling technique was used to do the shape matching of 3D objects by matching the faces of an unknown view against the faces of the model. It explicitly maximized a criterion function based on the ambiguity and inconsistency of classification, which was hierarchical and used results obtained at low levels to speed up and improve the accuracy of results at higher levels.
A three-dimensional scene analysis system for the shape matching of real world 3D objects is presented. Various issues related to representation and modeling of 3D objects is addressed and a method for the approximation of 3D objects by a set of planar faces is discussed. The major advantage of this method is that it was applicable to a complete object and was not restricted to a single range view which was the limitation of the previous work in 3D scene analysis. The method was a sequential region growing algorithm and was not applied to range images, but rather to a set of 3D points. The 3D model of an object was obtained by combining the object points from a sequence of range data images corresponding to various views of the object, applying the necessary transformations and then approximating the surface by polygons. A stochastic labeling technique was used to do the shape matching of 3D objects by matching the faces of an unknown view against the faces of the model. It explicitly maximized a criterion function based on the ambiguity and inconsistency of classification, which was hierarchical and used results obtained at low levels to speed up and improve the accuracy of results at higher levels.
Surface Representation and Shape Matching of 3D Objects
 A 3D scene analysis system for the shape matching of real world 3D objects is presented. A 3 point seed algorithm was used to approximate a 3D object by a set of planar faces. The 3D model of an object was obtained by combining the object points from a sequence of range data images corresponding to various views of the object, applying the transformations, and then approximating the surface by polygons. A hierarchical stochastic labeling technique was used to match the individual views of the object taken from any vantage point. The results of partial shape recognition were used to determine the orientation of the object in 3D space.
A 3D scene analysis system for the shape matching of real world 3D objects is presented. A 3 point seed algorithm was used to approximate a 3D object by a set of planar faces. The 3D model of an object was obtained by combining the object points from a sequence of range data images corresponding to various views of the object, applying the transformations, and then approximating the surface by polygons. A hierarchical stochastic labeling technique was used to match the individual views of the object taken from any vantage point. The results of partial shape recognition were used to determine the orientation of the object in 3D space.
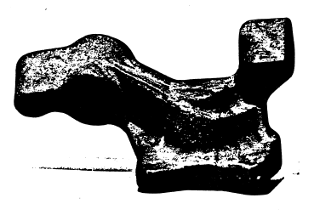
Three-Point Seed Method for the Extraction of Planar Faces from Range Data
 A method is given for representing a three-dimensional (3D) object as a set of planar face. The points representing the complete surface of the 3D object were obtained by combining the object points from a sequence of range data images corresponding to various views of the object. The planar faces were then determined by sequentially choosing three very close non-collinear points (the 3-point seed) and investigating the set of points. Two simple tests, one for convexity and the other for narrowness, ensured that the set of points is an object face.
A method is given for representing a three-dimensional (3D) object as a set of planar face. The points representing the complete surface of the 3D object were obtained by combining the object points from a sequence of range data images corresponding to various views of the object. The planar faces were then determined by sequentially choosing three very close non-collinear points (the 3-point seed) and investigating the set of points. Two simple tests, one for convexity and the other for narrowness, ensured that the set of points is an object face.
|
|



 Ce papier presente l’usage des modeles CAO pour la reconnaissance visuelle d’objets dans une application robotique. Une modelisation hierarchique d’un objet est obtenu a partir d’un modele geometrique et on utilise cette representation pour trouver l’orientation et la position de l‘objet.
Ce papier presente l’usage des modeles CAO pour la reconnaissance visuelle d’objets dans une application robotique. Une modelisation hierarchique d’un objet est obtenu a partir d’un modele geometrique et on utilise cette representation pour trouver l’orientation et la position de l‘objet.
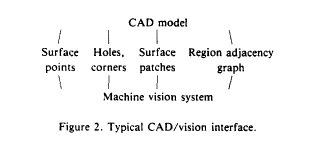 Computer Aided Design systems were being used to drive machine vision analysis. We proposed that the set of intrinsic 3-D shape characteristics provided by the CAD system be used to compare representational power of different CAD systems so far as the requirements for machine vision were concerned.
Computer Aided Design systems were being used to drive machine vision analysis. We proposed that the set of intrinsic 3-D shape characteristics provided by the CAD system be used to compare representational power of different CAD systems so far as the requirements for machine vision were concerned.