
|

|
Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi klrd takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
Super-resolution for astronomical observations
.png) In order to obtain detailed information from multiple telescope observations a general blind super-resolution (SR) reconstruction approach for astronomical images is proposed in this paper. A pixel-reliability-based SR reconstruction algorithm is described and implemented, where the developed process incorporates flat field correction, automatic star searching and centering, iterative star matching, and sub-pixel image registration. Images captured by the 1-m telescope at Yunnan Observatory are used to test the proposed technique. The results of these experiments indicate that, following SR reconstruction, faint stars are more distinct, bright stars have sharper profiles, and the backgrounds have higher details; thus these results benefit from the high-precision star centering and image registration provided by the developed method.
In order to obtain detailed information from multiple telescope observations a general blind super-resolution (SR) reconstruction approach for astronomical images is proposed in this paper. A pixel-reliability-based SR reconstruction algorithm is described and implemented, where the developed process incorporates flat field correction, automatic star searching and centering, iterative star matching, and sub-pixel image registration. Images captured by the 1-m telescope at Yunnan Observatory are used to test the proposed technique. The results of these experiments indicate that, following SR reconstruction, faint stars are more distinct, bright stars have sharper profiles, and the backgrounds have higher details; thus these results benefit from the high-precision star centering and image registration provided by the developed method.
Face Image Super-Resolution using 2D CCA
 We have decveloped a face super-resolution method using two-dimensional canonical correlation analysis
(2D CCA) is presented. A detail compensation step is followed to add high-frequency components to the
reconstructed high-resolution face. In our approach the relationship between the
high-resolution and the low-resolution face image are maintained in their original 2D representation.
Different parts of a face image are super-resolved separately to better preserve the local structure.
The proposed method is compared with various state-of-the-art super-resolution algorithms.
The method is very efficient in both the training and testing phases compared to the other approaches.
We have decveloped a face super-resolution method using two-dimensional canonical correlation analysis
(2D CCA) is presented. A detail compensation step is followed to add high-frequency components to the
reconstructed high-resolution face. In our approach the relationship between the
high-resolution and the low-resolution face image are maintained in their original 2D representation.
Different parts of a face image are super-resolved separately to better preserve the local structure.
The proposed method is compared with various state-of-the-art super-resolution algorithms.
The method is very efficient in both the training and testing phases compared to the other approaches.
Image Super-resolution by Extreme Learning Machine
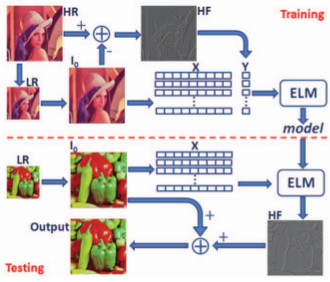 Image super-resolution is the process to generate high resolution
images from low-resolution inputs. We present
an efficient image super-resolution approach based on
the recent development of extreme learning machine (ELM).
We aim at reconstructing the high-frequency
components containing details and fine structures that are
missing from the low-resolution images. In the training step,
high-frequency components from the original high-resolution
images as the target values and image features from low resolution
images are fed to ELM to learn a model. Given
a low-resolution image, the high-frequency components are
generated via the learned model and added to the initially
interpolated low-resolution image. Experiments show that
with simple image features our algorithm performs better in
terms of accuracy and efficiency with different magnification
factors compared to the state-of-the-art methods.
Image super-resolution is the process to generate high resolution
images from low-resolution inputs. We present
an efficient image super-resolution approach based on
the recent development of extreme learning machine (ELM).
We aim at reconstructing the high-frequency
components containing details and fine structures that are
missing from the low-resolution images. In the training step,
high-frequency components from the original high-resolution
images as the target values and image features from low resolution
images are fed to ELM to learn a model. Given
a low-resolution image, the high-frequency components are
generated via the learned model and added to the initially
interpolated low-resolution image. Experiments show that
with simple image features our algorithm performs better in
terms of accuracy and efficiency with different magnification
factors compared to the state-of-the-art methods.
Improved Image Super-Resolution by Support Vector Regression
 Support Vector Machine (SVM) can construct a
hyperplane in a high or infinite dimensional space which can be
used for classification. Its regression version, Support Vector
Regression (SVR) has been used in various image processing
tasks. We have developed an image super-resolution
algorithm based on SVR. Experiments demonstrated that our
proposed method with limited training samples outperforms
some of the state-of-the-art approaches and during the super-resolution
process the model learned by SVR is robust to
reconstruct edges and fine details in various testing images.
Support Vector Machine (SVM) can construct a
hyperplane in a high or infinite dimensional space which can be
used for classification. Its regression version, Support Vector
Regression (SVR) has been used in various image processing
tasks. We have developed an image super-resolution
algorithm based on SVR. Experiments demonstrated that our
proposed method with limited training samples outperforms
some of the state-of-the-art approaches and during the super-resolution
process the model learned by SVR is robust to
reconstruct edges and fine details in various testing images.
Super-Resolution of Deformed Facial Images in Video
 Super-resolution (SR) of facial images from video suffers
from facial expression changes. Most of the existing SR algorithms
for facial images make an unrealistic assumption
that the “perfect” registration has been done prior to the SR
process. However, the registration is a challenging task for
SR with expression changes. Our research proposes a new
method for enhancing the resolution of low-resolution (LR)
facial image by handling the facial image in a non-rigid manner.
It consists of global tracking, local alignment for precise
registration and SR algorithms. A B-spline based Resolution
Aware Incremental Free Form Deformation (RAIFFD) model
is used to recover a dense local non-rigid flow field. In this
scheme, low-resolution image model is explicitly embedded
in the optimization function formulation to simulate the formation
of low resolution image. The results achieved by the
proposed approach are significantly better as compared to
the SR approaches applied on the whole face image without
considering local deformations.
Super-resolution (SR) of facial images from video suffers
from facial expression changes. Most of the existing SR algorithms
for facial images make an unrealistic assumption
that the “perfect” registration has been done prior to the SR
process. However, the registration is a challenging task for
SR with expression changes. Our research proposes a new
method for enhancing the resolution of low-resolution (LR)
facial image by handling the facial image in a non-rigid manner.
It consists of global tracking, local alignment for precise
registration and SR algorithms. A B-spline based Resolution
Aware Incremental Free Form Deformation (RAIFFD) model
is used to recover a dense local non-rigid flow field. In this
scheme, low-resolution image model is explicitly embedded
in the optimization function formulation to simulate the formation
of low resolution image. The results achieved by the
proposed approach are significantly better as compared to
the SR approaches applied on the whole face image without
considering local deformations.
Super-resolution of Facial Images in Video with Expression Changes
 Super-resolution (SR) of facial images from video suffers
from facial expression changes. Most of the existing SR
algorithms for facial images make an unrealistic assumption
that the “perfect” registration has been done prior to
the SR process. However, the registration is a challenging
task for SR with expression changes. We propose a
new method for enhancing the resolution of low-resolution
(LR) facial image by handling the facial image in a nonrigid
manner. It consists of global tracking, local alignment
for precise registration and SR algorithms. A B-spline
based Resolution Aware Incremental Free Form Deformation
(RAIFFD) model is used to recover a dense local nonrigid
flow field. In this scheme, low-resolution image model
is explicitly embedded in the optimization function formulation
to simulate the formation of low resolution image.
The results achieved by the proposed approach are significantly
better as compared to the SR approaches applied
on the whole face image without considering local deformations.
The results are also compared with two state-ofthe-
art SR algorithms to show the effectiveness of the approach
in super-resolving facial images with local expression
changes.
Super-resolution (SR) of facial images from video suffers
from facial expression changes. Most of the existing SR
algorithms for facial images make an unrealistic assumption
that the “perfect” registration has been done prior to
the SR process. However, the registration is a challenging
task for SR with expression changes. We propose a
new method for enhancing the resolution of low-resolution
(LR) facial image by handling the facial image in a nonrigid
manner. It consists of global tracking, local alignment
for precise registration and SR algorithms. A B-spline
based Resolution Aware Incremental Free Form Deformation
(RAIFFD) model is used to recover a dense local nonrigid
flow field. In this scheme, low-resolution image model
is explicitly embedded in the optimization function formulation
to simulate the formation of low resolution image.
The results achieved by the proposed approach are significantly
better as compared to the SR approaches applied
on the whole face image without considering local deformations.
The results are also compared with two state-ofthe-
art SR algorithms to show the effectiveness of the approach
in super-resolving facial images with local expression
changes.
Super-resolution Restoration of Facial Images in Video
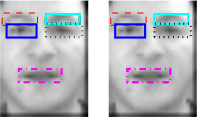 Reconstruction-based super-resolution has been widely
treated in computer vision. However, super-resolution of
facial images has received very little attention. Since different
parts of a face may have different motions in normal
videos, we propose a new method for enhancing
the resolution of low-resolution facial image by handling
the facial image non-uniformly. We divide low-resolution
face image into different regions based on facial features
and estimate motions of each of these regions using different
motion models. Our experimental results show we can
achieve better results than applying super-resolution on the
whole face image uniformly.
Reconstruction-based super-resolution has been widely
treated in computer vision. However, super-resolution of
facial images has received very little attention. Since different
parts of a face may have different motions in normal
videos, we propose a new method for enhancing
the resolution of low-resolution facial image by handling
the facial image non-uniformly. We divide low-resolution
face image into different regions based on facial features
and estimate motions of each of these regions using different
motion models. Our experimental results show we can
achieve better results than applying super-resolution on the
whole face image uniformly.
|
|
Top Slot Gacor Online Populer Paling Banyak di Mainkan 2025-2026 di Indonesia
Slot Toto Togel Gacor
Join toto togel Paling Banyak Di mainkan.
Situs Toto
With situs toto, mainkan game kesukaanmu di sini.
best online gambling rupiahtoto
rupiahtotorupiahtoto deposit sekali wd berkali-kali.
platform terbaik toto slot online
rupiahtoto raih kemenanganmu di rupiahtoto.
rupiahtoto : pusatnya slot togel online populer
ingat hanya di rupiahtoto rupiahtoto deposit 10rb WD sultan.
slot dengan pembayaran lengkap
slot ovoslot ovo, plat and win.
rupiahtoto best slot togel in Indonesia
Sign up at rupiahtoto situs resmi sejuta umat, menang dengan mudah di sini!.
toto slot terupdate dengan RTP tinggi
toto slot toto slot terbanyak di mainkan sepanjang masa.
slot dana deposit murah
Find success at slot dana agen slot dana dengan metode-metode depo gampang
sweet bonanza terbaik
Enjoy live betting like never before at sweet bonanzagame slot sweet bonanza tergacor saat ini.
link situs terbaik di Indonesia dalam permainan judi online resmi
amazing slot togel onlinerupiahtoto pasang angka impian mu di sini.
slot gacor: nomor #1 di Indonesia
slot gacorslot gacorbest slot gacor Indonesia.
https://amps303.org/
https://amps303.org/ https://amps303.org/https://amps303.org/


