
|

|
Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi klrd takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
Performance Prediction
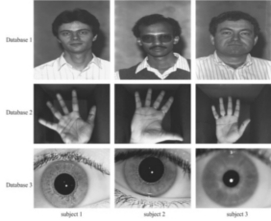 This research project builds novel statistical models for multi-biometric systems using geometric and multinomial distributions. These models are generic as they are only based on the
similarity scores produced by a recognition system. They predict the bounds on the range of indices within which a test subject is likely to
be present in a sorted set of similarity scores. These bounds are then used in the multibiometric recognition system to predict a smaller subset of subjects from the
database as probable candidates for a given test subject. Experimental results show that the proposed models enhance the recognition rate beyond the underlying
matching algorithms for multiple face views, fingerprints, palm prints, irises and their combinations.
This research project builds novel statistical models for multi-biometric systems using geometric and multinomial distributions. These models are generic as they are only based on the
similarity scores produced by a recognition system. They predict the bounds on the range of indices within which a test subject is likely to
be present in a sorted set of similarity scores. These bounds are then used in the multibiometric recognition system to predict a smaller subset of subjects from the
database as probable candidates for a given test subject. Experimental results show that the proposed models enhance the recognition rate beyond the underlying
matching algorithms for multiple face views, fingerprints, palm prints, irises and their combinations.
Prediction of Recognition Performance on Large Populations
 We have addressed the estimation of a small gallery size that can generate the optimal error
estimate and its confidence on a large population (relative to the size of the gallery). It uses a
generalized two-dimensional prediction model that combines a hypergeometric probability distribution
model with a binomial model and also considers the data distortion problem in large populations.
Learning is incorporated in the prediction process in order to find the optimal small gallery size and
to improve the prediction. The Chernoff and Chebychev inequalities are used as a guide to obtain the
small gallery size. Results for the prediction are presented for the NIST-4 fingerprint
database.
We have addressed the estimation of a small gallery size that can generate the optimal error
estimate and its confidence on a large population (relative to the size of the gallery). It uses a
generalized two-dimensional prediction model that combines a hypergeometric probability distribution
model with a binomial model and also considers the data distortion problem in large populations.
Learning is incorporated in the prediction process in order to find the optimal small gallery size and
to improve the prediction. The Chernoff and Chebychev inequalities are used as a guide to obtain the
small gallery size. Results for the prediction are presented for the NIST-4 fingerprint
database.
Prediction and Validation of Indexing Performance for Biometrics
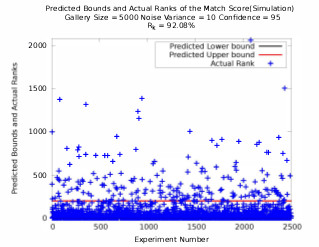 The performance of a recognition system is usually experimentally
determined. Therefore, one cannot predict the
peiformance of a recognition system a priori for a new
dataset. In this research, a statistical model to predict the
value of k in the rank-k identification rate for a given biometric
system is presented. Thus, one needs to search only
the topmost k match scores to locate the true match object.
A geometrical probability distribution is used to model the
number of non match scores present in the set of similarity
scores. The model is tested in simulation and by using
a public dataset. The model is also indirectly validated
against the previously published results. The actual results
obtained using publicly available databases are very close
to the predicted results which validates the proposed model.
The performance of a recognition system is usually experimentally
determined. Therefore, one cannot predict the
peiformance of a recognition system a priori for a new
dataset. In this research, a statistical model to predict the
value of k in the rank-k identification rate for a given biometric
system is presented. Thus, one needs to search only
the topmost k match scores to locate the true match object.
A geometrical probability distribution is used to model the
number of non match scores present in the set of similarity
scores. The model is tested in simulation and by using
a public dataset. The model is also indirectly validated
against the previously published results. The actual results
obtained using publicly available databases are very close
to the predicted results which validates the proposed model.
Human Recognition at a Distance
.png) This paper consider face, side face, gait and ear and their possible fusion for human recognition. It presents an overview of some of the techniques that we have developed for (a) super-resoulution-based face recognition in video, (b) gait-based recognition in video, (c) fusion of super-resolved side face and gait in video, (d) ear recognition in color/range images, and (e) fusion performance prediction and validation. It presents various real-world examples to illustrate the ideas and points out the relative merits of the approaches that are discussed.
This paper consider face, side face, gait and ear and their possible fusion for human recognition. It presents an overview of some of the techniques that we have developed for (a) super-resoulution-based face recognition in video, (b) gait-based recognition in video, (c) fusion of super-resolved side face and gait in video, (d) ear recognition in color/range images, and (e) fusion performance prediction and validation. It presents various real-world examples to illustrate the ideas and points out the relative merits of the approaches that are discussed.
Predicting Fingerprint Biometrics Performance from a Small Gallery
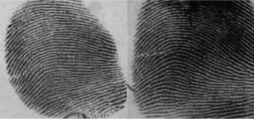 We present a binomial model to predict both fingerprint verification and identification performance.
The match and non-match scores are computed, using the number of corresponding triangles as the match
metric, between the query and gallery fingerprints.
The match score and non-match score in a binomial prediction model are used to predict the performance on
large (relative to the size of the gallery) populations from a small gallery.
We present a binomial model to predict both fingerprint verification and identification performance.
The match and non-match scores are computed, using the number of corresponding triangles as the match
metric, between the query and gallery fingerprints.
The match score and non-match score in a binomial prediction model are used to predict the performance on
large (relative to the size of the gallery) populations from a small gallery.
On the Performance Prediction and Validation for Multisensor Fusion
.png) Multiple sensors are commonly fused to improve the detection and recognition performance of computer vision and pattern recognition systems. The traditional approach to determine the optimal sensor combination is to try all possible sensor combinations by performing exhaustive experiments. In this paper, we present a theoretical approach that predicts the performance of sensor fusion that allows us to select the optimal combination. We start with the characteristics of each sensor by computing the match score and non-match score distributions of objects to be recognized. These distributions are modeled as a mixture of Gaussians. Then, we use an explicit Φ transformation that maps a receiver operating characteristic (ROC) curve to a straight line in 2-D space whose axes are related to the false alarm rate (F AR) and the Hit rate (Hit). Finally, using this representation, we derive a set of metrics to evaluate the sensor fusion performance and find the optimal sensor combination. We verify our prediction approach on the publicly available XM2VTS database as well as other databases.
Multiple sensors are commonly fused to improve the detection and recognition performance of computer vision and pattern recognition systems. The traditional approach to determine the optimal sensor combination is to try all possible sensor combinations by performing exhaustive experiments. In this paper, we present a theoretical approach that predicts the performance of sensor fusion that allows us to select the optimal combination. We start with the characteristics of each sensor by computing the match score and non-match score distributions of objects to be recognized. These distributions are modeled as a mixture of Gaussians. Then, we use an explicit Φ transformation that maps a receiver operating characteristic (ROC) curve to a straight line in 2-D space whose axes are related to the false alarm rate (F AR) and the Hit rate (Hit). Finally, using this representation, we derive a set of metrics to evaluate the sensor fusion performance and find the optimal sensor combination. We verify our prediction approach on the publicly available XM2VTS database as well as other databases.
Learning models for predicting recognition performance
.png) This paper addresses one of the fundamental problems encountered in performance prediction for object recognition. In particular we address the problems related to estimation of small gallery size that can give good error estimates and their confidences on large probe sets and populations. We use a generalized two-dimensional prediction model that integrates a hypergeometric probability distribution model with a binomial model explicitly and considers the distortion problem in large populations. We incorporate learning in the prediction process in order to find the optimal small gallery size and to improve its performance. The Chernoff and Chebychev inequalities are used as a guide to obtain the small gallery size. During the prediction we use the expectation-maximum (EM) algorithm to learn the match score and the non-match score distributions (the number of components, their weights, means and covariances) that are represented as Gaussian mixtures. By learning we find the optimal size of small gallery and at the same time provide the upper bound and the lower bound for the prediction on large populations. Results are shown using real-world databases.
This paper addresses one of the fundamental problems encountered in performance prediction for object recognition. In particular we address the problems related to estimation of small gallery size that can give good error estimates and their confidences on large probe sets and populations. We use a generalized two-dimensional prediction model that integrates a hypergeometric probability distribution model with a binomial model explicitly and considers the distortion problem in large populations. We incorporate learning in the prediction process in order to find the optimal small gallery size and to improve its performance. The Chernoff and Chebychev inequalities are used as a guide to obtain the small gallery size. During the prediction we use the expectation-maximum (EM) algorithm to learn the match score and the non-match score distributions (the number of components, their weights, means and covariances) that are represented as Gaussian mixtures. By learning we find the optimal size of small gallery and at the same time provide the upper bound and the lower bound for the prediction on large populations. Results are shown using real-world databases.
An integrated prediction model for biometrics
.png) This paper addresses the problem of predicting recognition performance on a large population from a small gallery. Unlike the current approaches based on a binomial model that use match and non-match scores, this paper presents a generalized two-dimensional model that integrates a hypergeometric probability distribution model explicitly with a binomial model. The distortion caused by sensor noise, feature uncertainty, feature occlusion and feature clutter in the gallery data is modeled. The prediction model provides performance measures as a function of rank, population size and the number of distorted images. Results are shown on NIST-4 fingerprint database and 3D ear database for various sizes of gallery and the population.
This paper addresses the problem of predicting recognition performance on a large population from a small gallery. Unlike the current approaches based on a binomial model that use match and non-match scores, this paper presents a generalized two-dimensional model that integrates a hypergeometric probability distribution model explicitly with a binomial model. The distortion caused by sensor noise, feature uncertainty, feature occlusion and feature clutter in the gallery data is modeled. The prediction model provides performance measures as a function of rank, population size and the number of distorted images. Results are shown on NIST-4 fingerprint database and 3D ear database for various sizes of gallery and the population.
Performance evaluation and prediction for 3-D ear recognition
.png) Existing ear recognition approaches do not give theoretical or experimental performance prediction. Therefore, the discriminating power of ear biometric for human identification cannot be evaluated. This paper addresses two interrelated problems: (a) proposes an integrated local descriptor for representation to recognize human ears in 3D. Comparing local surface descriptors between a test and a model image, an initial correspondence of local surface patches is established and then filtered using simple geometric constraints. The performance of the proposed ear recognition system is evaluated on a real range image database of 52 subjects. (b) A binomial model is also presented to predict the ear recognition performance. Match and non-matched distances obtained from the database of 52 subjects are used to estimate the distributions. By modeling cumulative match characteristic (CMC) curve as a binomial distribution, the ear recognition performance can be predicted on a larger gallery.
Existing ear recognition approaches do not give theoretical or experimental performance prediction. Therefore, the discriminating power of ear biometric for human identification cannot be evaluated. This paper addresses two interrelated problems: (a) proposes an integrated local descriptor for representation to recognize human ears in 3D. Comparing local surface descriptors between a test and a model image, an initial correspondence of local surface patches is established and then filtered using simple geometric constraints. The performance of the proposed ear recognition system is evaluated on a real range image database of 52 subjects. (b) A binomial model is also presented to predict the ear recognition performance. Match and non-matched distances obtained from the database of 52 subjects are used to estimate the distributions. By modeling cumulative match characteristic (CMC) curve as a binomial distribution, the ear recognition performance can be predicted on a larger gallery.
Performance Prediction for Individual Recognition by Gait
 Existing gait recognition approaches do not give their theoretical or experimental performance predictions.
Therefore, the discriminating power of gait as a feature for human recognition cannot be evaluated. In this
paper, we first propose a kinematic-based approach to recognize human by gait. The proposed approach
estimates 3D human walking parameters by performing a least squares fit of the 3D kinematic model to the
2D silhouette extracted from a monocular image sequence.
Existing gait recognition approaches do not give their theoretical or experimental performance predictions.
Therefore, the discriminating power of gait as a feature for human recognition cannot be evaluated. In this
paper, we first propose a kinematic-based approach to recognize human by gait. The proposed approach
estimates 3D human walking parameters by performing a least squares fit of the 3D kinematic model to the
2D silhouette extracted from a monocular image sequence.
Performance modeling of vote-based object recognition
.png) The focus of this paper is predicting the bounds on performance of a vote-based object recognition system, when the test data features are distorted by uncertainty in both feature locations and magnitudes, by occlusion and by clutter. An improved method is presented to calculate lower and upper bound predictions of the probability that objects with various levels of distorted features will be recognized correctly. The prediction method takes model similarity into account, so that when models of objects are more similar to each other, then the probability of correct recognition is lower. The effectiveness of the prediction method is validated in a synthetic aperture radar (SAR) automatic target recognition (ATR) application using MSTAR public SAR data, which are obtained under different depression angles, object configurations and object articulations. Experiments show the performance improvement that can obtained by considering the feature magnitudes, compared to a previous performance prediction method that only considered the locations of features. In addition, the predicted performance is compared with actual performance of a vote-based SAR recognition system using the same SAR scatterer location and magnitude features.
The focus of this paper is predicting the bounds on performance of a vote-based object recognition system, when the test data features are distorted by uncertainty in both feature locations and magnitudes, by occlusion and by clutter. An improved method is presented to calculate lower and upper bound predictions of the probability that objects with various levels of distorted features will be recognized correctly. The prediction method takes model similarity into account, so that when models of objects are more similar to each other, then the probability of correct recognition is lower. The effectiveness of the prediction method is validated in a synthetic aperture radar (SAR) automatic target recognition (ATR) application using MSTAR public SAR data, which are obtained under different depression angles, object configurations and object articulations. Experiments show the performance improvement that can obtained by considering the feature magnitudes, compared to a previous performance prediction method that only considered the locations of features. In addition, the predicted performance is compared with actual performance of a vote-based SAR recognition system using the same SAR scatterer location and magnitude features.
Bayesian-based performance prediction for gait recognition
.png) Existing gait recognition approaches do not give their theoretical or experiential performance predictions. Therefore, the discriminating power of gait as a feature for human recognition cannot be evaluated. We first propose a kinematic-based approach to recognize humans by gait. The proposed. approach estimates 3D human walking parameters by performing a least squares fit of the 3D kinematic model to the 2D silhouette extracted from a monocular image sequence. Next, a Bayesian based statistical analysis is performed to evaluate the discriminating power of the extracted features. Through probabilistic simulation, we not only predict the probability of correct recognition (PCR) with regard to different within-class feature variance, but also obtain the upper bound on PCR with regard to different human silhouette resolutions. In addition, the maximum number of people in a database is obtained given the allowable error rate. This is extremely important for gait recognition in large databases.
Existing gait recognition approaches do not give their theoretical or experiential performance predictions. Therefore, the discriminating power of gait as a feature for human recognition cannot be evaluated. We first propose a kinematic-based approach to recognize humans by gait. The proposed. approach estimates 3D human walking parameters by performing a least squares fit of the 3D kinematic model to the 2D silhouette extracted from a monocular image sequence. Next, a Bayesian based statistical analysis is performed to evaluate the discriminating power of the extracted features. Through probabilistic simulation, we not only predict the probability of correct recognition (PCR) with regard to different within-class feature variance, but also obtain the upper bound on PCR with regard to different human silhouette resolutions. In addition, the maximum number of people in a database is obtained given the allowable error rate. This is extremely important for gait recognition in large databases.
Validation of SAR ATR performance predictions using learned distortion models
.png) Performance prediction of SAR ATR has been a challenging problem. In our previous work, we developed a statistical framework for predicting bounds on fundamental performance of vote-based SAR ATR using scattering centers. This framework considered data distortion factors such as uncertainty, occlusion and clutter, in addition to model similarity. In this paper, we present an initial study on learning the statistical distributions of these factors. We focus on the development of a method for learning the distribution of a parameter that encodes the combined eect of the occlusion and similarity factors on performance. The impact of incorporating such a distribution on the accuracy of the predicted bounds is demonstrated by comparing bounds obtained using it with those obtained assuming simplied distributions. The data used in the experiments are obtained from the MSTAR public domain under dierent congurations and depression angles. Keywords: Model-based SAR ATR, performance prediction and validation, learned distortion models, MSTAR data 1.
Performance prediction of SAR ATR has been a challenging problem. In our previous work, we developed a statistical framework for predicting bounds on fundamental performance of vote-based SAR ATR using scattering centers. This framework considered data distortion factors such as uncertainty, occlusion and clutter, in addition to model similarity. In this paper, we present an initial study on learning the statistical distributions of these factors. We focus on the development of a method for learning the distribution of a parameter that encodes the combined eect of the occlusion and similarity factors on performance. The impact of incorporating such a distribution on the accuracy of the predicted bounds is demonstrated by comparing bounds obtained using it with those obtained assuming simplied distributions. The data used in the experiments are obtained from the MSTAR public domain under dierent congurations and depression angles. Keywords: Model-based SAR ATR, performance prediction and validation, learned distortion models, MSTAR data 1.
Predicting an Upper Bound on SAR ATR Performance
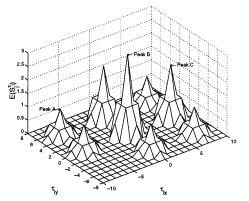 We present a method for predicting a tight upper bound on performance of a vote-based approach for
automatic target recognition (ATR) in synthetic aperture radar (SAR) images. The proposed method
considers data distortion factors such as uncertainty, occlusion,
and clutter, as well as model factors such as structural similarity. The proposed method is validated using
MSTAR public SAR data, which are obtained
under different depression angles, configurations, and articulations
We present a method for predicting a tight upper bound on performance of a vote-based approach for
automatic target recognition (ATR) in synthetic aperture radar (SAR) images. The proposed method
considers data distortion factors such as uncertainty, occlusion,
and clutter, as well as model factors such as structural similarity. The proposed method is validated using
MSTAR public SAR data, which are obtained
under different depression angles, configurations, and articulations
Predicting Performance of Object Recognition
 We present a method for predicting fundamental performance of object recognition.
The proposed method considers data distortion factors such as uncertainty,
occlusion, and clutter, in addition to model similarity. This is unlike previous approaches, which consider
only a subset of these factors. Performance is predicted in two stages. In the first stage, the similarity between
every pair of model objects is captured. In the second stage, the similarity information is used along with statistical
models of the data-distortion factors to determine an upper bound on the probability of recognition error.
This bound is directly used to determine a lower bound on the probability of correct recognition.
We present a method for predicting fundamental performance of object recognition.
The proposed method considers data distortion factors such as uncertainty,
occlusion, and clutter, in addition to model similarity. This is unlike previous approaches, which consider
only a subset of these factors. Performance is predicted in two stages. In the first stage, the similarity between
every pair of model objects is captured. In the second stage, the similarity information is used along with statistical
models of the data-distortion factors to determine an upper bound on the probability of recognition error.
This bound is directly used to determine a lower bound on the probability of correct recognition.
Performance prediction and validation for object recognition
.png) This paper addresses the problem of predicting fundamental performance of vote-based object recognition using 2-0 point features. It presents Q method for predicting Q tight lower bound on performance. Unlike previous approaches, the proposed method considers data-distortion factors, namely uncertainty, occlusion, and clutter, in addition to model similarity, simultaneously. The similarity between every pair of model objects is captured by comparing their structures as a function of the relative transformation between them. This information is used along with statistical models of the data-distortion factors to determine an upper bound on the probability of recognition error. This bound is directly used to determine a lower bound on the probability of correct recognition. The validity of the method is experimentally demonstrated using synthetic aperture radar (SAR) data obtained under different depression angles and target configurations.
This paper addresses the problem of predicting fundamental performance of vote-based object recognition using 2-0 point features. It presents Q method for predicting Q tight lower bound on performance. Unlike previous approaches, the proposed method considers data-distortion factors, namely uncertainty, occlusion, and clutter, in addition to model similarity, simultaneously. The similarity between every pair of model objects is captured by comparing their structures as a function of the relative transformation between them. This information is used along with statistical models of the data-distortion factors to determine an upper bound on the probability of recognition error. This bound is directly used to determine a lower bound on the probability of correct recognition. The validity of the method is experimentally demonstrated using synthetic aperture radar (SAR) data obtained under different depression angles and target configurations.
Bounding SAR ATR performance based on model similarity
.png) We analyze the effect of model similarity on the performance of a vote- based approach for target recognition from SAR images. In such an approach, each model target is represented by a set of SAR views sampled at a variety of azimuth angles and a specific depression angle. The model hypothesis corresponding to a given data view is chosen to be the one with the highest number of data-supported model features (votes). We address three issues in this paper. Firstly, we present a quantitative measure of the similarity between a pair of model views. Such a measure depends on the degree of structural overlap between the two views, and the amount of uncertainty. Secondly, we describe a similarity- based framework for predicting an upper bound on recognition performance in the presence of uncertainty, occlusion and clutter. Thirdly, we validate the proposed framework using MSTAR public data, which are obtained under different depression angles, configurations and articulations.
We analyze the effect of model similarity on the performance of a vote- based approach for target recognition from SAR images. In such an approach, each model target is represented by a set of SAR views sampled at a variety of azimuth angles and a specific depression angle. The model hypothesis corresponding to a given data view is chosen to be the one with the highest number of data-supported model features (votes). We address three issues in this paper. Firstly, we present a quantitative measure of the similarity between a pair of model views. Such a measure depends on the degree of structural overlap between the two views, and the amount of uncertainty. Secondly, we describe a similarity- based framework for predicting an upper bound on recognition performance in the presence of uncertainty, occlusion and clutter. Thirdly, we validate the proposed framework using MSTAR public data, which are obtained under different depression angles, configurations and articulations.
Predicting Object Recognition Performance Under Data Uncertainty, Occlusion and Clutter
 We present a novel method for predicting the performance
of an object recognition approach in the presence
of data uncertainty, occlusion and clutter. The
recognition approach uses a vote-based decision criterion,
which selects the object/pose hypothesis that has
the maximum number of consistent features (votes)
with the scene data. The prediction method determines
a fundamental, optimistic, limit on achievable
performance by any vote-based recognition system. It
captures the structural similarity between model objects,
which is a fundamental factor in determining
the recognition performance. Given a bound on data
uncertainty, we determine the structural similarity between
every pair of model objects. This is done by
computing the number of consistent features between
the two objects as a function of the relative transformation
between them. Similarity information is
then used, along with statistical models for data distortion,
to estimate the probability of correct recognition
(PCR) as a function of occlusion and clutter rates.
The method is validated by comparing predicted PCR
plots with ones that are obtained experimentally.
We present a novel method for predicting the performance
of an object recognition approach in the presence
of data uncertainty, occlusion and clutter. The
recognition approach uses a vote-based decision criterion,
which selects the object/pose hypothesis that has
the maximum number of consistent features (votes)
with the scene data. The prediction method determines
a fundamental, optimistic, limit on achievable
performance by any vote-based recognition system. It
captures the structural similarity between model objects,
which is a fundamental factor in determining
the recognition performance. Given a bound on data
uncertainty, we determine the structural similarity between
every pair of model objects. This is done by
computing the number of consistent features between
the two objects as a function of the relative transformation
between them. Similarity information is
then used, along with statistical models for data distortion,
to estimate the probability of correct recognition
(PCR) as a function of occlusion and clutter rates.
The method is validated by comparing predicted PCR
plots with ones that are obtained experimentally.
|
|


