Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi klrd takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
Words alignment based on association rules for cross-domain sentiment classification
.png) In this paper, we propose a novel approach called words alignment based on association rules (WAAR) for cross-domain sentiment classification, which can establish an indirect mapping relationship between domain-specific words in different domains by learning the strong association rules between domain-shared words and domain-specific words in the same domain. In this way, the differences between the source domain and target domain can be reduced to some extent, and a more accurate cross-domain classifier can be trained. Experimental results on Amazon datasets show the effectiveness of our approach on improving the performance of cross-domain sentiment classification.
In this paper, we propose a novel approach called words alignment based on association rules (WAAR) for cross-domain sentiment classification, which can establish an indirect mapping relationship between domain-specific words in different domains by learning the strong association rules between domain-shared words and domain-specific words in the same domain. In this way, the differences between the source domain and target domain can be reduced to some extent, and a more accurate cross-domain classifier can be trained. Experimental results on Amazon datasets show the effectiveness of our approach on improving the performance of cross-domain sentiment classification.
Deep analysis of mitochondria and cell health using machine learning
.png) Mitochondrial image analysis is typically done on still images using slow manual methods or automated methods of limited types of features. MitoMo integrated software overcomes these bottlenecks by automating rapid unbiased quantitative analysis of mitochondrial morphology, texture, motion, and morphogenesis and advances machine-learning classification to predict cell health by combining features. Our pixel-based approach for motion analysis evaluates the magnitude and direction of motion of: (1) molecules within mitochondria, (2) individual mitochondria, and (3) distinct morphological classes of mitochondria.
Mitochondrial image analysis is typically done on still images using slow manual methods or automated methods of limited types of features. MitoMo integrated software overcomes these bottlenecks by automating rapid unbiased quantitative analysis of mitochondrial morphology, texture, motion, and morphogenesis and advances machine-learning classification to predict cell health by combining features. Our pixel-based approach for motion analysis evaluates the magnitude and direction of motion of: (1) molecules within mitochondria, (2) individual mitochondria, and (3) distinct morphological classes of mitochondria.
Semantic concept co-occurrence patterns for image annotation and retrieval
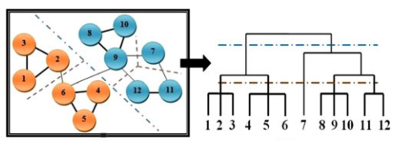 Presented is a novel approach to automatically generate intermediate image descriptors by exploiting concept co-occurrence patterns in the pre-labeled training set that renders it possible to depict complex scene images semantically. This work is motivated by the fact that multiple concepts that frequently co-occur across images form patterns which could provide contextual cues for individual concept inference. The co-occurrence patterns were discovered as hierarchical communities by graph modularity maximization in a network with nodes and edges representing concepts and co-occurrence relationships separately. A random walk process working on the inferred concept probabilities with the discovered co-occurrence patterns was applied to acquire the refined concept signature representation. Through experiments in automatic image annotation and semantic image retrieval on several challenging datasets, the effectiveness of the proposed concept co-occurrence patterns as well as the concept signature representation in comparison with state-of-the-art approaches was demonstrated.
Presented is a novel approach to automatically generate intermediate image descriptors by exploiting concept co-occurrence patterns in the pre-labeled training set that renders it possible to depict complex scene images semantically. This work is motivated by the fact that multiple concepts that frequently co-occur across images form patterns which could provide contextual cues for individual concept inference. The co-occurrence patterns were discovered as hierarchical communities by graph modularity maximization in a network with nodes and edges representing concepts and co-occurrence relationships separately. A random walk process working on the inferred concept probabilities with the discovered co-occurrence patterns was applied to acquire the refined concept signature representation. Through experiments in automatic image annotation and semantic image retrieval on several challenging datasets, the effectiveness of the proposed concept co-occurrence patterns as well as the concept signature representation in comparison with state-of-the-art approaches was demonstrated.
Improving person re-identification by soft biometrics based re-ranking
.png) The problem of person re-identification is to recognize a target subject across non-overlapping distributed cameras at different times and locations. In a real-world scenario, person re-identification is challenging due to the dramatic changes in a subject’s appearance in terms of pose, illumination, background, and occlusion. Existing approaches either try to design robust features to identify a subject across different views or learn distance metrics to maximize the similarity between different views of the same person and minimize the similarity between different views of different persons. In this paper, we aim at improving the reidentification performance by reranking the returned results based on soft biometric attributes, such as gender, which can describe probe and gallery subjects at a higher level. During reranking, the soft biometric attributes are detected and attribute-based distance scores are calculated between pairs of images by using a regression model. These distance scores are used for reranking the initially returned matches. Experiments on a benchmark database with different baseline re-identification methods show that reranking improves the recognition accuracy by moving upwards the returned matches from gallery that share the same soft biometric attributes as the probe subject.
The problem of person re-identification is to recognize a target subject across non-overlapping distributed cameras at different times and locations. In a real-world scenario, person re-identification is challenging due to the dramatic changes in a subject’s appearance in terms of pose, illumination, background, and occlusion. Existing approaches either try to design robust features to identify a subject across different views or learn distance metrics to maximize the similarity between different views of the same person and minimize the similarity between different views of different persons. In this paper, we aim at improving the reidentification performance by reranking the returned results based on soft biometric attributes, such as gender, which can describe probe and gallery subjects at a higher level. During reranking, the soft biometric attributes are detected and attribute-based distance scores are calculated between pairs of images by using a regression model. These distance scores are used for reranking the initially returned matches. Experiments on a benchmark database with different baseline re-identification methods show that reranking improves the recognition accuracy by moving upwards the returned matches from gallery that share the same soft biometric attributes as the probe subject.
Optimizing Crowd Simulation Based on Real Video Data
.png) Tracking of individuals and groups in video is an active topic of research in image processing and analyzing. This paper proposes an approach for the purpose of guiding a crowd simulation algorithm to mimic the trajectories of individuals in crowds as observed in real videos, which can be further used in image processing and computer vision research extensively. This is achieved by tuning the parameters used in the simulation automatically. In our experiment, the simulation trajectories are generated by the RVO2 library and the real trajectories are extracted from the UCSD crowd video dataset. The Edit Distance on Real sequence (EDR) between the simulated and real trajectories are calculated. A genetic algorithm is applied to find the parameters that minimize the distances. The experimental results demonstrate that the trajectory distances between simulation and reality are significantly reduced after tuning the parameters of the simulator.
Tracking of individuals and groups in video is an active topic of research in image processing and analyzing. This paper proposes an approach for the purpose of guiding a crowd simulation algorithm to mimic the trajectories of individuals in crowds as observed in real videos, which can be further used in image processing and computer vision research extensively. This is achieved by tuning the parameters used in the simulation automatically. In our experiment, the simulation trajectories are generated by the RVO2 library and the real trajectories are extracted from the UCSD crowd video dataset. The Edit Distance on Real sequence (EDR) between the simulated and real trajectories are calculated. A genetic algorithm is applied to find the parameters that minimize the distances. The experimental results demonstrate that the trajectory distances between simulation and reality are significantly reduced after tuning the parameters of the simulator.
Latent fingerprint image segmentation using fractal dimension features and weighted extreme learning machine ensemble
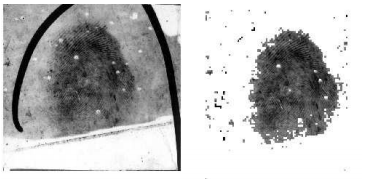 Latent fingerprints are fingerprints unintentionally left at a crime scene. Due to the poor quality and often complex image background and overlapping patterns characteristic of latent fingerprint images, separating the fingerprint region-of-interest from complex image background and overlapping patterns was a very challenging problem. Proposed is a latent fingerprint segmentation algorithm based on fractal dimension features and weighted extreme learning machine. Feature vectors were built from the local fractal dimension features and used as input to a weighted extreme learning machine ensemble classifier. The patches were classified into fingerprint and non- fingerprint classes. The experimental results of the proposed approach showed significant improvement in both the false detection rate (FDR) and overall segmentation accuracy compared to existing approaches.
Latent fingerprints are fingerprints unintentionally left at a crime scene. Due to the poor quality and often complex image background and overlapping patterns characteristic of latent fingerprint images, separating the fingerprint region-of-interest from complex image background and overlapping patterns was a very challenging problem. Proposed is a latent fingerprint segmentation algorithm based on fractal dimension features and weighted extreme learning machine. Feature vectors were built from the local fractal dimension features and used as input to a weighted extreme learning machine ensemble classifier. The patches were classified into fingerprint and non- fingerprint classes. The experimental results of the proposed approach showed significant improvement in both the false detection rate (FDR) and overall segmentation accuracy compared to existing approaches.
Image Super-resolution by Extreme Learning Machine
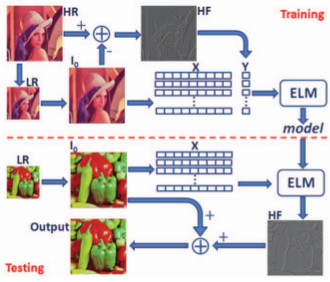 Image super-resolution is the process to generate high resolution
images from low-resolution inputs.
An efficient image super-resolution approach based on
the recent development of extreme learning machine (ELM)
is proposed in our research. We aim at reconstructing the high-frequency
components containing details and fine structures that are
missing from the low-resolution images. In the training step,
high-frequency components from the original high-resolution
images as the target values and image features from low resolution
images are fed to ELM to learn a model. Given
a low-resolution image, the high-frequency components are
generated via the learned model and added to the initially
interpolated low-resolution image. Experiments show that
with simple image features our algorithm performs better in
terms of accuracy and efficiency with different magnification
factors compared to the state-of-the-art methods.
Image super-resolution is the process to generate high resolution
images from low-resolution inputs.
An efficient image super-resolution approach based on
the recent development of extreme learning machine (ELM)
is proposed in our research. We aim at reconstructing the high-frequency
components containing details and fine structures that are
missing from the low-resolution images. In the training step,
high-frequency components from the original high-resolution
images as the target values and image features from low resolution
images are fed to ELM to learn a model. Given
a low-resolution image, the high-frequency components are
generated via the learned model and added to the initially
interpolated low-resolution image. Experiments show that
with simple image features our algorithm performs better in
terms of accuracy and efficiency with different magnification
factors compared to the state-of-the-art methods.
Single camera multi-person tracking based on crowd simulation
.png) Tracking individuals in video sequences, especially in crowded scenes, is still a challenging research topic in the area of pattern recognition and computer vision. However, current single camera tracking approaches are mostly based on visual features only. The novelty of the approach proposed in this paper is the integration of evidences from a crowd simulation algorithm into a pure vision based method. Based on a stateof-the-art tracking-by-detection method, the integration is achieved by evaluating particle weights with additional prediction of individual positions, which is obtained from the crowd simulation algorithm. Our experimental results indicate that, by integrating simulation, the multi-person tracking performance such as MOTP and MOTA can be increased by an average about 2% and 5%, which provides significant evidence for the effectiveness of our approach.
Tracking individuals in video sequences, especially in crowded scenes, is still a challenging research topic in the area of pattern recognition and computer vision. However, current single camera tracking approaches are mostly based on visual features only. The novelty of the approach proposed in this paper is the integration of evidences from a crowd simulation algorithm into a pure vision based method. Based on a stateof-the-art tracking-by-detection method, the integration is achieved by evaluating particle weights with additional prediction of individual positions, which is obtained from the crowd simulation algorithm. Our experimental results indicate that, by integrating simulation, the multi-person tracking performance such as MOTP and MOTA can be increased by an average about 2% and 5%, which provides significant evidence for the effectiveness of our approach.
Integrating crowd simulation for pedestrian tracking in a multi-camera system
.png) Multi-camera multi-target tracking is one of the most active research topics in computer vision. However, many challenges remain to achieve robust performance in real-world video networks. In this paper we extend the state-of-the-art single camera tracking method, with both detection and crowd simulation, to a multiple camera tracking approach that exploits crowd simulation and uses principal axis-based integration. The experiments are conducted on PETS 2009 data set and the performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) based on the position of each pedestrian on the ground plane. It is demonstrated that the information from crowd simulation can provide significant advantage for tracking multiple pedestrians through multiple cameras.
Multi-camera multi-target tracking is one of the most active research topics in computer vision. However, many challenges remain to achieve robust performance in real-world video networks. In this paper we extend the state-of-the-art single camera tracking method, with both detection and crowd simulation, to a multiple camera tracking approach that exploits crowd simulation and uses principal axis-based integration. The experiments are conducted on PETS 2009 data set and the performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) based on the position of each pedestrian on the ground plane. It is demonstrated that the information from crowd simulation can provide significant advantage for tracking multiple pedestrians through multiple cameras.
Utility-Based Dynamic Camera Assignment and Hand-Off in a Video Network
.png) In this paper we propose an approach for multi-camera multi-person seamless tracking that allows camera assignment and hand-off based on a set of user-supplied criteria. The approach is based on the application of game theory to camera assignment problem. Bargaining mechanisms are considered for collaborations as well as for resolving conflicts among the available cameras. Camera utilities and person utilities are computed based on a set of criteria. They are used in the process of developing the bargaining mechanisms. Experiments for multi-camera multi-person tracking are provided. Several different criteria and their combination of them are carried out and compared with each other to corroborate the proposed approach.
In this paper we propose an approach for multi-camera multi-person seamless tracking that allows camera assignment and hand-off based on a set of user-supplied criteria. The approach is based on the application of game theory to camera assignment problem. Bargaining mechanisms are considered for collaborations as well as for resolving conflicts among the available cameras. Camera utilities and person utilities are computed based on a set of criteria. They are used in the process of developing the bargaining mechanisms. Experiments for multi-camera multi-person tracking are provided. Several different criteria and their combination of them are carried out and compared with each other to corroborate the proposed approach.
Tracking humans using multimodal fusion
.png) Human motion detection plays an important role in automated surveillance systems. However, it is challenging to detect non-rigid moving objects (e.g. human) robustly in a cluttered environment. In this paper, we compare two approaches for detecting walking humans using multi-modal measurementsvideo and audio sequences. The first approach is based on the Time-Delay Neural Network (TDNN), which fuses the audio and visual data at the feature level to detect the walking human. The second approach employs the Bayesian Network (BN) for jointly modeling the video and audio signals. Parameter estimation of the graphical models is executed using the Expectation-Maximization (EM) algorithm. And the location of the target is tracked by the Bayes inference. Experiments are performed in several indoor and outdoor scenarios: in the lab, more than one person walking, occlusion by bushes etc. The comparison of performance and efficiency of the two approaches are also presented.
Human motion detection plays an important role in automated surveillance systems. However, it is challenging to detect non-rigid moving objects (e.g. human) robustly in a cluttered environment. In this paper, we compare two approaches for detecting walking humans using multi-modal measurementsvideo and audio sequences. The first approach is based on the Time-Delay Neural Network (TDNN), which fuses the audio and visual data at the feature level to detect the walking human. The second approach employs the Bayesian Network (BN) for jointly modeling the video and audio signals. Parameter estimation of the graphical models is executed using the Expectation-Maximization (EM) algorithm. And the location of the target is tracked by the Bayes inference. Experiments are performed in several indoor and outdoor scenarios: in the lab, more than one person walking, occlusion by bushes etc. The comparison of performance and efficiency of the two approaches are also presented.
Adaptive Object Detection Based on Modified Hebbian Learning
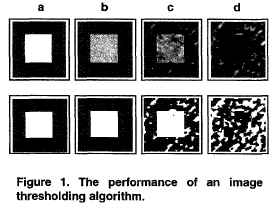 The focus of this study was the issue of developing self-adapting automatic object detection systems for improving their performance. Two general methodologies for performance improvement were first introduced. They were based on parameter optimizing and input adapting. Different modified Hebbian learning rules were developed to build adaptive feature extractors which transformed the input data into a desired form for a given algorithm. To show its feasibility, an input adaptor for object detection was designed as an example and tested using multisensor data (optical, SAR, and FLIR).
The focus of this study was the issue of developing self-adapting automatic object detection systems for improving their performance. Two general methodologies for performance improvement were first introduced. They were based on parameter optimizing and input adapting. Different modified Hebbian learning rules were developed to build adaptive feature extractors which transformed the input data into a desired form for a given algorithm. To show its feasibility, an input adaptor for object detection was designed as an example and tested using multisensor data (optical, SAR, and FLIR).
Enhancing a Self-Organizing Map through Near-Miss Injection
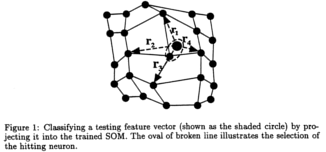 Kohonen’s self-organizing map (SOM) was viewed from the aspect of distinguishing different classes of feature vectors. Although a well trained SOM could convert the most important similarity relationships among the input feature vectors of the same class into the spatial relationships among the responding neurons, it lacked the power to exclude the near-miss feature vectors that belonged to another class. In order to use SOM as a classifier, we developed an algorithm called near-miss injection which, when used in conjunction with Kohonen’s SOM algorithm, could build a more “faithful” map for a given class that covered less feature vectors from another class. A 2-class classifier was built upon the trained SOM, and experimental results are shown on synthetic data.
Kohonen’s self-organizing map (SOM) was viewed from the aspect of distinguishing different classes of feature vectors. Although a well trained SOM could convert the most important similarity relationships among the input feature vectors of the same class into the spatial relationships among the responding neurons, it lacked the power to exclude the near-miss feature vectors that belonged to another class. In order to use SOM as a classifier, we developed an algorithm called near-miss injection which, when used in conjunction with Kohonen’s SOM algorithm, could build a more “faithful” map for a given class that covered less feature vectors from another class. A 2-class classifier was built upon the trained SOM, and experimental results are shown on synthetic data.
|


