Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi klrd takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
Novel Representation for Driver Emotion Recognition in Motor Vehicle Videos
.png) A novel feature representation of human facial expressions for emotion recognition is developed. The representation leveraged the background texture removal ability of Anisotropic Inhibited Gabor Filtering (AIGF) with the compact representation of spatiotemporal local binary patterns. The emotion recognition system incorporated face detection and registration followed by the proposed feature representation: Local Anisotropic Inhibited Binary Patterns in Three Orthogonal Planes (LAIBP-TOP) and classification. The system is evaluated on videos from Motor Trend Magazine’s Best Driver Car of the Year 2014-2016. The results showed improved performance compared to other state-of-the-art feature representations.
A novel feature representation of human facial expressions for emotion recognition is developed. The representation leveraged the background texture removal ability of Anisotropic Inhibited Gabor Filtering (AIGF) with the compact representation of spatiotemporal local binary patterns. The emotion recognition system incorporated face detection and registration followed by the proposed feature representation: Local Anisotropic Inhibited Binary Patterns in Three Orthogonal Planes (LAIBP-TOP) and classification. The system is evaluated on videos from Motor Trend Magazine’s Best Driver Car of the Year 2014-2016. The results showed improved performance compared to other state-of-the-art feature representations.
EDeN: Ensemble of deep networks for vehicle classification
.png) Traffic surveillance has always been a challenging task to automate. The main difficulties arise from the high variation of the vehicles appertaining to the same category, low resolution, changes in illumination and occlusions. Due to the lack of large labeled datasets, deep learning techniques still have not shown their full potential. In this paper, thanks to the MIOvision Traffic Camera Dataset (MIO-TCD), an Ensemble of Deep Networks (EDeN) is used to successfully classify surveillance images into eleven different classes of vehicles. The ensemble of deep networks consists of 2 individual networks that are trained independently. Experimental results show that the ensemble of networks gives better performance compared to individual networks and it is robust to noise. The ensemble of networks achieves an accuracy of 97.80%, mean precision of 94.39%, mean recall of 91.90% and Cohen kappa of 96.58.
Traffic surveillance has always been a challenging task to automate. The main difficulties arise from the high variation of the vehicles appertaining to the same category, low resolution, changes in illumination and occlusions. Due to the lack of large labeled datasets, deep learning techniques still have not shown their full potential. In this paper, thanks to the MIOvision Traffic Camera Dataset (MIO-TCD), an Ensemble of Deep Networks (EDeN) is used to successfully classify surveillance images into eleven different classes of vehicles. The ensemble of deep networks consists of 2 individual networks that are trained independently. Experimental results show that the ensemble of networks gives better performance compared to individual networks and it is robust to noise. The ensemble of networks achieves an accuracy of 97.80%, mean precision of 94.39%, mean recall of 91.90% and Cohen kappa of 96.58.
Robust visual rear ground clearance estimation and classification of a passenger vehicle
 Computation of Visual Rear Ground Clearance of vehicles was an important computer vision application. This problem was challenging as the road and vehicle rear bumper may have subtle appearance differences, vehicle motion was on uneven surfaces and there were real-time considerations. A method is presented to compute the Visual Rear Ground Clearance of a vehicle from its rear view video and classify it into two classes; namely Low Visual Rear Ground Clearance Vehicles and High Visual Rear Ground Clearance Vehicles. A multi-frame matching technique in conjunction with geometry based constraints was developed. It detected Regions-of-Interest ROIs of moving vehicles and moving shadows, and used shape constraints associated with vehicle geometry as viewed from its rear. It tracked stable features on a vehicle to compute the Visual Rear Ground Clearance.
Computation of Visual Rear Ground Clearance of vehicles was an important computer vision application. This problem was challenging as the road and vehicle rear bumper may have subtle appearance differences, vehicle motion was on uneven surfaces and there were real-time considerations. A method is presented to compute the Visual Rear Ground Clearance of a vehicle from its rear view video and classify it into two classes; namely Low Visual Rear Ground Clearance Vehicles and High Visual Rear Ground Clearance Vehicles. A multi-frame matching technique in conjunction with geometry based constraints was developed. It detected Regions-of-Interest ROIs of moving vehicles and moving shadows, and used shape constraints associated with vehicle geometry as viewed from its rear. It tracked stable features on a vehicle to compute the Visual Rear Ground Clearance.
Efficient alignment for vehicle make and model recognition
.png) This paper presents a make and model recognition system for passenger vehicles. We propose a two-step efficient alignment mechanism to account for view point changes. The 2D alignment problem is solved as two separate one dimensional shortest path problems. To avoid the alignment of the query with the entire database, reference views are used. These views are generated iteratively from the database. To improve the alignment performance further, use of two references is proposed: a universal view and type specific showcase views. The query is aligned with universal view first and compared with the database to find the type of the query. Then the query is aligned with type specific showcase view and compared with the database to achieve the final make and model recognition. We report results on database of 1500 vehicles with more than 250 makes and models.
This paper presents a make and model recognition system for passenger vehicles. We propose a two-step efficient alignment mechanism to account for view point changes. The 2D alignment problem is solved as two separate one dimensional shortest path problems. To avoid the alignment of the query with the entire database, reference views are used. These views are generated iteratively from the database. To improve the alignment performance further, use of two references is proposed: a universal view and type specific showcase views. The query is aligned with universal view first and compared with the database to find the type of the query. Then the query is aligned with type specific showcase view and compared with the database to achieve the final make and model recognition. We report results on database of 1500 vehicles with more than 250 makes and models.
Three-Dimensional Vehicle Model Building From Video
 Traffic videos often capture slowly changing views of moving vehicles.
We instead focus on 3-D model building vehicles with different shapes from a
generic 3-D vehicle model by accumulating evidences in streaming traffic videos collected
from a single camera. We propose a novel Bayesian graphical model (BGM), which is called
structure-modifiable adaptive reason-building temporal Bayesian graph (SmartBG), that models
uncertainty propagation in 3-D vehicle model building. Uncertainties are used as relative weights
to fuse evidences and to compute the overall reliability of the generated models.
Results from several traffic videos and two different view points demonstrate the performance of the method.
Traffic videos often capture slowly changing views of moving vehicles.
We instead focus on 3-D model building vehicles with different shapes from a
generic 3-D vehicle model by accumulating evidences in streaming traffic videos collected
from a single camera. We propose a novel Bayesian graphical model (BGM), which is called
structure-modifiable adaptive reason-building temporal Bayesian graph (SmartBG), that models
uncertainty propagation in 3-D vehicle model building. Uncertainties are used as relative weights
to fuse evidences and to compute the overall reliability of the generated models.
Results from several traffic videos and two different view points demonstrate the performance of the method.
Structural Signatures for Passenger Vehicle Classification in Video
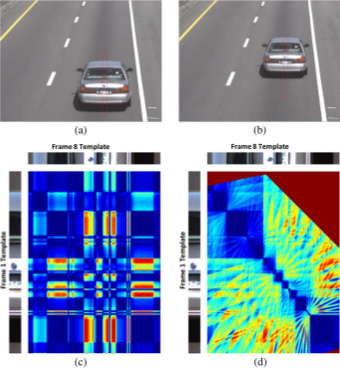 This research focuses on a challenging pattern recognition problem of significant industrial impact,
i.e., classifying vehicles from their rear videos as observed by a camera mounted on top of a highway
with vehicles travelling at high speed. To solve this problem, we present a novel feature called
structural signature. From a rear-view video, a structural signature recovers the vehicle side
profile information, which is crucial in its classification. We present a complete system
that computes structural
signatures and uses them for classification of passenger vehicles into sedans, pickups,
and minivans/sport utility vehicles in highway videos.
This research focuses on a challenging pattern recognition problem of significant industrial impact,
i.e., classifying vehicles from their rear videos as observed by a camera mounted on top of a highway
with vehicles travelling at high speed. To solve this problem, we present a novel feature called
structural signature. From a rear-view video, a structural signature recovers the vehicle side
profile information, which is crucial in its classification. We present a complete system
that computes structural
signatures and uses them for classification of passenger vehicles into sedans, pickups,
and minivans/sport utility vehicles in highway videos.
Vehicle Logo Super-Resolution by Canonical Correlation Analysis
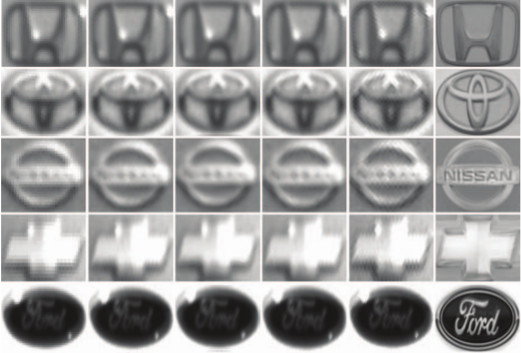 Recognition of a vehicle make is of interest in the fields of
law enforcement and surveillance. We have develop
a canonical correlation analysis (CCA) based method for
vehicle logo super-resolution to facilitate the recognition of
the vehicle make. From a limited number of high-resolution
logos, we populate the training dataset for each make using
gamma transformations. Given a vehicle logo from a low resolution
source (i.e., surveillance or traffic camera recordings),
the learned models yield super-resolved results. By
matching the low-resolution image and the generated high resolution
images, we select the final output that is closest to
the low-resolution image in the histogram of oriented gradients
(HOG) feature space. Experimental results show that our
approach outperforms the state-of-the-art super-resolution
methods in qualitative and quantitative measures. Furthermore,
the super-resolved logos help to improve the accuracy
in the subsequent recognition tasks significantly.
Recognition of a vehicle make is of interest in the fields of
law enforcement and surveillance. We have develop
a canonical correlation analysis (CCA) based method for
vehicle logo super-resolution to facilitate the recognition of
the vehicle make. From a limited number of high-resolution
logos, we populate the training dataset for each make using
gamma transformations. Given a vehicle logo from a low resolution
source (i.e., surveillance or traffic camera recordings),
the learned models yield super-resolved results. By
matching the low-resolution image and the generated high resolution
images, we select the final output that is closest to
the low-resolution image in the histogram of oriented gradients
(HOG) feature space. Experimental results show that our
approach outperforms the state-of-the-art super-resolution
methods in qualitative and quantitative measures. Furthermore,
the super-resolved logos help to improve the accuracy
in the subsequent recognition tasks significantly.
Dynamic Bayesian Networks for Vehicle Classification in Video
 Vehicle classification has evolved into a significant subject of study due to its importance in autonomous
navigation, traffic analysis, surveillance and security systems, and transportation management.
We present a
system which classifies a vehicle (given its direct rear-side view) into one of
four classes Sedan, Pickup truck, SUV/Minivan, and unknown. A feature set of tail light and vehicle
dimensions is extracted which feeds a feature selection algorithm.
A feature vector is then processed by a Hybrid Dynamic Bayesian Network (HDBN) to
classify each vehicle.
Vehicle classification has evolved into a significant subject of study due to its importance in autonomous
navigation, traffic analysis, surveillance and security systems, and transportation management.
We present a
system which classifies a vehicle (given its direct rear-side view) into one of
four classes Sedan, Pickup truck, SUV/Minivan, and unknown. A feature set of tail light and vehicle
dimensions is extracted which feeds a feature selection algorithm.
A feature vector is then processed by a Hybrid Dynamic Bayesian Network (HDBN) to
classify each vehicle.
Incremental Unsupervised Three-Dimensional Vehicle Model Learning From Video
 We introduce a new generic model-based approach for building 3-D models of vehicles
from color video from a single uncalibrated traffic-surveillance camera. We propose a novel directional
template method that uses trigonometric relations of the 2-D features and geometric relations of a single
3-D generic vehicle model to map 2-D features to 3-D in the face of projection and foreshortening effects.
Results are shown for several simulated and real traffic videos in an uncontrolled setup.
The performance of the proposed method for several types of
vehicles in two considerably different traffic spots is very promising to encourage its applicability in
3-D reconstruction of other rigid objects in video.
We introduce a new generic model-based approach for building 3-D models of vehicles
from color video from a single uncalibrated traffic-surveillance camera. We propose a novel directional
template method that uses trigonometric relations of the 2-D features and geometric relations of a single
3-D generic vehicle model to map 2-D features to 3-D in the face of projection and foreshortening effects.
Results are shown for several simulated and real traffic videos in an uncontrolled setup.
The performance of the proposed method for several types of
vehicles in two considerably different traffic spots is very promising to encourage its applicability in
3-D reconstruction of other rigid objects in video.
Bayesian Based 3D Shape Reconstruction from Video
 In a video sequence with a 3D rigid object moving,
changing shapes of the 2D projections provide interrelated
spatio-temporal cues for incremental 3D shape
reconstruction. This research describes a probabilistic
approach for intelligent view-integration to build 3D model
of vehicles from traffic videos collected from an
uncalibrated static camera. The proposed Bayesian net
framework allows the handling of uncertainties in a
systematic manner. The performance is verified with several
types of vehicles in different videos.
In a video sequence with a 3D rigid object moving,
changing shapes of the 2D projections provide interrelated
spatio-temporal cues for incremental 3D shape
reconstruction. This research describes a probabilistic
approach for intelligent view-integration to build 3D model
of vehicles from traffic videos collected from an
uncalibrated static camera. The proposed Bayesian net
framework allows the handling of uncertainties in a
systematic manner. The performance is verified with several
types of vehicles in different videos.
Incremental Vehicle 3-D Modeling from Video
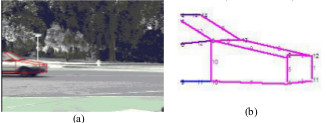 We present a new model-based approach
for building 3-D models of vehicles from color video
provided by a traffic surveillance camera. We
incrementally build 3D models using a clustering
technique. Geometrical relations based on 3D generic
vehicle model map 2D features to 3D. The 3D features are
then adaptively clustered over the frame sequence to
incrementally generate the 3D model of the vehicle.
Results are shown for both simulated and real traffic video.
They are evaluated by a new structural performance
measure underscoring usefulness of incremental learning.
We present a new model-based approach
for building 3-D models of vehicles from color video
provided by a traffic surveillance camera. We
incrementally build 3D models using a clustering
technique. Geometrical relations based on 3D generic
vehicle model map 2D features to 3D. The 3D features are
then adaptively clustered over the frame sequence to
incrementally generate the 3D model of the vehicle.
Results are shown for both simulated and real traffic video.
They are evaluated by a new structural performance
measure underscoring usefulness of incremental learning.
Unsupervised Learning for Incremental 3-D Modeling
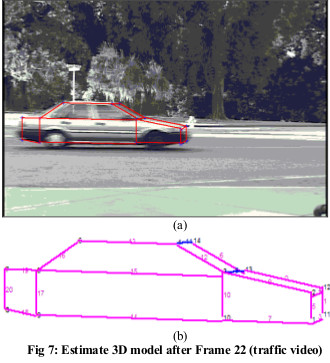 Learning based incremental 3D modeling of traffic
vehicles from uncalibrated video data stream has enormous
application potential in traffic monitoring and intelligent
transportation systems. In this research, video data from a
traffic surveillance camera is used to incrementally
develop the 3D model of vehicles using a clustering based
unsupervised learning. Geometrical relations based on 3D
generic vehicle model map 2D features to 3D. The 3D
features are then adaptively clustered over the frames to
incrementally generate the 3D model of the vehicle.
Results are shown for both simulated and real traffic video.
They are evaluated by a structural performance measure.
Learning based incremental 3D modeling of traffic
vehicles from uncalibrated video data stream has enormous
application potential in traffic monitoring and intelligent
transportation systems. In this research, video data from a
traffic surveillance camera is used to incrementally
develop the 3D model of vehicles using a clustering based
unsupervised learning. Geometrical relations based on 3D
generic vehicle model map 2D features to 3D. The 3D
features are then adaptively clustered over the frames to
incrementally generate the 3D model of the vehicle.
Results are shown for both simulated and real traffic video.
They are evaluated by a structural performance measure.
Multiple look angle SAR recognition
.png) The focus of this paper is optimizing the recognition of vehicles in Synthetic Aperture radar (SAR) imagery by exploiting the azimuthal variance of scatterers using multiple SAR recognizers at different look angles. The variance of SAR scattering center locations with target azimuth leads to recognition system results at different azimuths that are independent, even for small azimuth deltas. Extensive experimental recognition results are presented in terms of receiver operating characteristic (ROC) curves to show the effects of multiple look angles on recognition performance for MSTAR vehicle targets with configuration variants, articulation, and occlusion.
The focus of this paper is optimizing the recognition of vehicles in Synthetic Aperture radar (SAR) imagery by exploiting the azimuthal variance of scatterers using multiple SAR recognizers at different look angles. The variance of SAR scattering center locations with target azimuth leads to recognition system results at different azimuths that are independent, even for small azimuth deltas. Extensive experimental recognition results are presented in terms of receiver operating characteristic (ROC) curves to show the effects of multiple look angles on recognition performance for MSTAR vehicle targets with configuration variants, articulation, and occlusion.
Recognizing target variants and articulations in synthetic aperture radar images
.png) The focus of this paper is recognizing articulated vehicles and actual vehicle configuration variants in real synthetic aperture radar (SAR) images. Using SAR scattering-center locations and magnitudes as features, the invariance of these features is shown with articulation (e.g., rotation of a tank turret), with configuration variants, and with a small change in depression angle. This scatterer-location and magnitude quasiinvariance is used as a basis for development of a SAR recognition system that successfully identifies real articulated and nonstandard- configuration vehicles based on nonarticulated, standard recognition models. Identification performance results are presented as vote-space scatterplots and receiver operating characteristic curves for configuration variants, for articulated objects, and for a small change in depression angle with the MSTAR public data.
The focus of this paper is recognizing articulated vehicles and actual vehicle configuration variants in real synthetic aperture radar (SAR) images. Using SAR scattering-center locations and magnitudes as features, the invariance of these features is shown with articulation (e.g., rotation of a tank turret), with configuration variants, and with a small change in depression angle. This scatterer-location and magnitude quasiinvariance is used as a basis for development of a SAR recognition system that successfully identifies real articulated and nonstandard- configuration vehicles based on nonarticulated, standard recognition models. Identification performance results are presented as vote-space scatterplots and receiver operating characteristic curves for configuration variants, for articulated objects, and for a small change in depression angle with the MSTAR public data.
|


