Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
DEEPAGENT: An algorithm integration approach for person re-identification
.png) Person re-identification(RE-ID) has played a significant role in the fields of image processing and computer vision because of its potential value in practical applications. Researchers are striving to design new algorithms to improve the performance of RE-ID but ignore the advantages of existing approaches. In this paper, motivated by deep reinforcement learning, we propose a Deep Agent, which can integrate existing algorithms and enable them to complement each other. Two Deep Agents are designed to integrate algorithms for data augmentation and feature extraction parts separately for RE-ID. Experiment results demonstrate that the integrated algorithms can achieve a better accuracy than using each one of them alone.
Person re-identification(RE-ID) has played a significant role in the fields of image processing and computer vision because of its potential value in practical applications. Researchers are striving to design new algorithms to improve the performance of RE-ID but ignore the advantages of existing approaches. In this paper, motivated by deep reinforcement learning, we propose a Deep Agent, which can integrate existing algorithms and enable them to complement each other. Two Deep Agents are designed to integrate algorithms for data augmentation and feature extraction parts separately for RE-ID. Experiment results demonstrate that the integrated algorithms can achieve a better accuracy than using each one of them alone.
An unbiased temporal representation for video-based person re-identification
.png) In the re-id task, the long-term dependency is quite common since the key information (identity of the pedestrian) exists most of the time along the given sequence. Thus, the importance of a frame should not be determined by its position in a sequence, which is usually biased in state-of-the-art models with RNNs. In this paper, we argue that long-term dependency can be very important and propose an unbiased siamese recurrent convolutional neural network architecture to model and associate pedestrians in a video. Experimental results on two public datasets demonstrate the effectiveness of the proposed method.
In the re-id task, the long-term dependency is quite common since the key information (identity of the pedestrian) exists most of the time along the given sequence. Thus, the importance of a frame should not be determined by its position in a sequence, which is usually biased in state-of-the-art models with RNNs. In this paper, we argue that long-term dependency can be very important and propose an unbiased siamese recurrent convolutional neural network architecture to model and associate pedestrians in a video. Experimental results on two public datasets demonstrate the effectiveness of the proposed method.
Soccer: Who has the ball? Generating visual analytics and player statistics
.png) In this paper, we propose an approach that automatically generates visual analytics from videos specifically for soccer to help coaches and recruiters identify the most promising talents. We use (a) Convolutional Neural Networks (CNNs) to localize soccer players in a video and identify players controlling the ball, (b) Deep Convolutional Generative Adversarial Networks (DCGAN) for data augmentation, (c) a histogram based matching to identify teams and (d) frame-by-frame prediction and verification analyses to generate visual analytics.
In this paper, we propose an approach that automatically generates visual analytics from videos specifically for soccer to help coaches and recruiters identify the most promising talents. We use (a) Convolutional Neural Networks (CNNs) to localize soccer players in a video and identify players controlling the ball, (b) Deep Convolutional Generative Adversarial Networks (DCGAN) for data augmentation, (c) a histogram based matching to identify teams and (d) frame-by-frame prediction and verification analyses to generate visual analytics.
Attributes Co-occurrence Pattern Mining for Video-Based Person Re-identification
.png) In this paper, a new way to take advantage of image processing, computer vision and pattern recognition is proposed. First, convolutional neural networks are adopted to detect the attributes. Second, the dependencies among attributes are obtained by mining association rules, and they are used to refine the attributes classification results. Third, metric learning technique is used to transfer the attribute learning task to person re-identification. Finally, the approach is integrated into an appearance-based method for video-based person re-identification. Experimental results on two benchmark datasets indicate that attributes can provide improvements both in accuracy and generalization capabilities.
In this paper, a new way to take advantage of image processing, computer vision and pattern recognition is proposed. First, convolutional neural networks are adopted to detect the attributes. Second, the dependencies among attributes are obtained by mining association rules, and they are used to refine the attributes classification results. Third, metric learning technique is used to transfer the attribute learning task to person re-identification. Finally, the approach is integrated into an appearance-based method for video-based person re-identification. Experimental results on two benchmark datasets indicate that attributes can provide improvements both in accuracy and generalization capabilities.
A dense flow-based framework for real-time object registration under compound motion
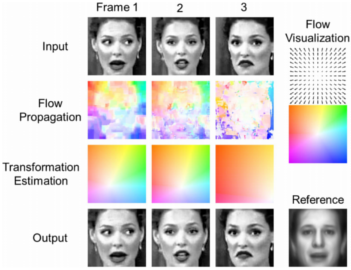 Tracking and measuring surface deformation while the object itself is also moving was a challenging, yet important problem in many video analysis tasks. For example, video-based facial expression recognition required tracking non-rigid motions of facial features without being affected by any rigid motions of the head. Presented is a generic video alignment framework to extract and characterize surface deformations accompanied by rigid-body motions with respect to a fixed reference (a canonical form). Also proposed is a generic model for object alignment in a Bayesian framework, and rigorously showed that a special case of the model results in a SIFT flow and optical flow based least-square problem. The proposed algorithm was evaluated on three applications, including the analysis of subtle facial muscle dynamics in spontaneous expressions, face image super-resolution, and generic object registration.
Tracking and measuring surface deformation while the object itself is also moving was a challenging, yet important problem in many video analysis tasks. For example, video-based facial expression recognition required tracking non-rigid motions of facial features without being affected by any rigid motions of the head. Presented is a generic video alignment framework to extract and characterize surface deformations accompanied by rigid-body motions with respect to a fixed reference (a canonical form). Also proposed is a generic model for object alignment in a Bayesian framework, and rigorously showed that a special case of the model results in a SIFT flow and optical flow based least-square problem. The proposed algorithm was evaluated on three applications, including the analysis of subtle facial muscle dynamics in spontaneous expressions, face image super-resolution, and generic object registration.
Integrating Social Grouping for Multi-target Tracking Across Cameras in a CRF Model
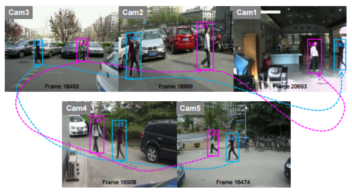 Tracking multiple targets across non-overlapping cameras aims at estimating the trajectories of all targets and maintaining their identity labels consistent while they move from one camera to another. Matching targets from different cameras can be very challenging, as there might be significant appearance variation and the blind area between cameras makes target’s motion less predictable. Unlike most of the existing methods that only focus on modeling appearance and spatio-temporal cues for inter-camera tracking, presented is a novel online learning approach that considers integrating high-level contextual information into the tracking system. The tracking problem was formulated using an online learned Conditional Random Field (CRF) model that minimized a global energy cost.
Tracking multiple targets across non-overlapping cameras aims at estimating the trajectories of all targets and maintaining their identity labels consistent while they move from one camera to another. Matching targets from different cameras can be very challenging, as there might be significant appearance variation and the blind area between cameras makes target’s motion less predictable. Unlike most of the existing methods that only focus on modeling appearance and spatio-temporal cues for inter-camera tracking, presented is a novel online learning approach that considers integrating high-level contextual information into the tracking system. The tracking problem was formulated using an online learned Conditional Random Field (CRF) model that minimized a global energy cost.
Selective experience replay in reinforcement learning for re-identification
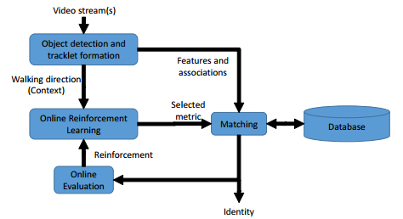 Person reidentification has the problem of recognizing a person across non-overlapping camera views. Pose variations, illumination conditions, low resolution images, and occlusion were the main challenges encountered in reidentification. Due to the uncontrolled environment in which the videos were captured, people could appear in different poses and the appearance of a person could vary significantly. The walking direction of a person provided a good estimation of their pose. Therefore, proposed is a reidentification system which adaptively selected an appropriate distance metric based on context of walking direction using reinforcement learning. Though experiments, it was showed that such a dynamic strategy outperformed static strategy learned or designed offline
Person reidentification has the problem of recognizing a person across non-overlapping camera views. Pose variations, illumination conditions, low resolution images, and occlusion were the main challenges encountered in reidentification. Due to the uncontrolled environment in which the videos were captured, people could appear in different poses and the appearance of a person could vary significantly. The walking direction of a person provided a good estimation of their pose. Therefore, proposed is a reidentification system which adaptively selected an appropriate distance metric based on context of walking direction using reinforcement learning. Though experiments, it was showed that such a dynamic strategy outperformed static strategy learned or designed offline
Group structure preserving pedestrian tracking in a multi-camera Video network
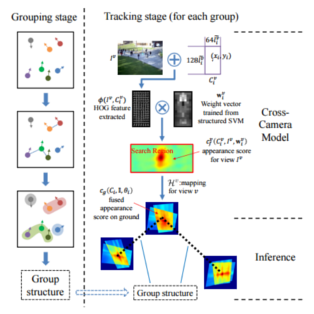 Pedestrian tracking in video has been a popular research topic with many practical applications. In order to improve tracking performance, many ideas have been proposed, among which the use of geometric information is one of the most popular directions in recent research. Proposed is a novel multi-camera pedestrian tracking framework which incorporates the structural information of pedestrian groups in the crowd. In this framework, firstly, a new cross-camera model is proposed which enables the fusion of the confidence information from all camera views. Secondly, the group structures on the ground plane provide extra constraints between pedestrians. Thirdly, the structured SVM is adopted to update the cross camera model for each pedestrian according to the most recent tracked location.
Pedestrian tracking in video has been a popular research topic with many practical applications. In order to improve tracking performance, many ideas have been proposed, among which the use of geometric information is one of the most popular directions in recent research. Proposed is a novel multi-camera pedestrian tracking framework which incorporates the structural information of pedestrian groups in the crowd. In this framework, firstly, a new cross-camera model is proposed which enables the fusion of the confidence information from all camera views. Secondly, the group structures on the ground plane provide extra constraints between pedestrians. Thirdly, the structured SVM is adopted to update the cross camera model for each pedestrian according to the most recent tracked location.
Multi-person tracking by online learned grouping model with non-linear motion context
.png) Associating tracks in different camera views directly based on their appearance similarity is difficult and prone to error. In most previous methods, the appearance similarity is computed either using color histograms or based on pretrained brightness transfer function that maps color between cameras. In this paper, a novel reference set based appearance model is proposed to improve multitarget tracking in a network of nonoverlapping cameras. Contrary to previous work, a reference set is constructed for a pair of cameras, containing subjects appearing in both camera views. The effectiveness of the proposed method over the state of the art on two challenging real-world multicamera video data sets is demonstrated by thorough experiments.
Associating tracks in different camera views directly based on their appearance similarity is difficult and prone to error. In most previous methods, the appearance similarity is computed either using color histograms or based on pretrained brightness transfer function that maps color between cameras. In this paper, a novel reference set based appearance model is proposed to improve multitarget tracking in a network of nonoverlapping cameras. Contrary to previous work, a reference set is constructed for a pair of cameras, containing subjects appearing in both camera views. The effectiveness of the proposed method over the state of the art on two challenging real-world multicamera video data sets is demonstrated by thorough experiments.
Sparse representation matching for person re-identification
 Person re-identification aims at matching people in non-overlapping cameras at different time and locations. To address this multi-view matching problem, we first learn a subspace using canonical correlation analysis (CCA) in which the goal is to maximize the correlation between data from different cameras but corresponding to the same people. Given a probe from one camera view, we represented it using a sparse representation from a jointly learned coupled dictionary in the CCA subspace. The 1 induced sparse representation were regularized by a 2 regularization term. The introduction of 2 regularization allowed learning a sparse representation while maintaining the stability of the sparse coefficients. To compute the matching scores between probe and gallery, their 2 regularized sparse representations were matched using a modified cosine similarity measure.
Person re-identification aims at matching people in non-overlapping cameras at different time and locations. To address this multi-view matching problem, we first learn a subspace using canonical correlation analysis (CCA) in which the goal is to maximize the correlation between data from different cameras but corresponding to the same people. Given a probe from one camera view, we represented it using a sparse representation from a jointly learned coupled dictionary in the CCA subspace. The 1 induced sparse representation were regularized by a 2 regularization term. The introduction of 2 regularization allowed learning a sparse representation while maintaining the stability of the sparse coefficients. To compute the matching scores between probe and gallery, their 2 regularized sparse representations were matched using a modified cosine similarity measure.
Grouping model for people tracking in surveillance camera
 Person tracking and analysis from images or videos captured by closed-circuit television (CCTV) played an important role in forensics applications. Described is a tracking model by group analysis. This framework improved over state-of-the-art tracking algorithms by leveraging an online learned social grouping behavior model. This group model was practical in real-world applications where group changes (e.g., merge and split) were natural among pedestrians.
Person tracking and analysis from images or videos captured by closed-circuit television (CCTV) played an important role in forensics applications. Described is a tracking model by group analysis. This framework improved over state-of-the-art tracking algorithms by leveraging an online learned social grouping behavior model. This group model was practical in real-world applications where group changes (e.g., merge and split) were natural among pedestrians.
People tracking in camera networks: Three open questions
.png) The Boston incident underlines the need for more in-depth research on how to keep tabs on the location and identity of dynamic objects in a scene, which is foundational to automatic video analysis for applications such as surveillance, monitoring, and behavioral analysis. Research into tracking people in a single-camera view has matured enough to produce reliable solutions, and smart camera networks are sparking interest in tracking across multiple-camera views. However, tracking in this context has many more challenges than in a single view. When networked cameras have partially overlapping views, spatiotemporal constraints enable tracking, but in larger camera networks, overlap is often impractical, and appearance is the key tracking enabler.
The Boston incident underlines the need for more in-depth research on how to keep tabs on the location and identity of dynamic objects in a scene, which is foundational to automatic video analysis for applications such as surveillance, monitoring, and behavioral analysis. Research into tracking people in a single-camera view has matured enough to produce reliable solutions, and smart camera networks are sparking interest in tracking across multiple-camera views. However, tracking in this context has many more challenges than in a single view. When networked cameras have partially overlapping views, spatiotemporal constraints enable tracking, but in larger camera networks, overlap is often impractical, and appearance is the key tracking enabler.
Tracking People by Evolving Social Groups: An Approach with Social Network Perspective
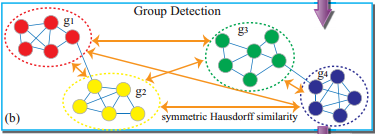 We address the problem of multi-people tracking in unconstrained and semi-crowded scenes. Instead of seeking more robust appearance or motion models to track each person as an isolated moving entity, we pose the multi-people tracking problem as a group-based tracklets association problem using the discovered social groups of tracklets as the contextual cues. We formulate tracking the evolution of social groups of tracklets as detecting closely connected communities in a “tracklet interaction network” (TIN) with nodes standing for the tracklets and edges denoting the spatio-temporal co-occurrence correlations measured by the edge weights. We incorporate the detected social groups in the tracklet interaction network to improve multi-people tracking performance.
We address the problem of multi-people tracking in unconstrained and semi-crowded scenes. Instead of seeking more robust appearance or motion models to track each person as an isolated moving entity, we pose the multi-people tracking problem as a group-based tracklets association problem using the discovered social groups of tracklets as the contextual cues. We formulate tracking the evolution of social groups of tracklets as detecting closely connected communities in a “tracklet interaction network” (TIN) with nodes standing for the tracklets and edges denoting the spatio-temporal co-occurrence correlations measured by the edge weights. We incorporate the detected social groups in the tracklet interaction network to improve multi-people tracking performance.
Multi-camera Pedestrian Tracking using Group Structure
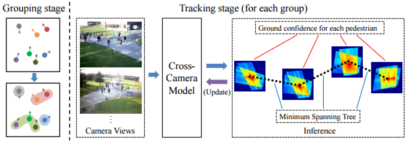 Proposed is a novel multi-camera pedestrian tracking system which incorporates a pedestrian grouping strategy and an online cross-camera model. The new cross-camera model is able to take the advantage of the information from all camera views as well as the group structure in the inference stage, and can be updated based on the learning approach from structured SVM. The experimental results demonstrate the improvement in tracking performance when grouping stage is integrated.
Proposed is a novel multi-camera pedestrian tracking system which incorporates a pedestrian grouping strategy and an online cross-camera model. The new cross-camera model is able to take the advantage of the information from all camera views as well as the group structure in the inference stage, and can be updated based on the learning approach from structured SVM. The experimental results demonstrate the improvement in tracking performance when grouping stage is integrated.
Person Re-Identification with Reference Descriptor
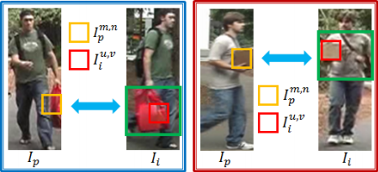 A reference-based method is proposed for person re-identification across different cameras. The matching is conducted in reference space where the descriptor for a person is translated from the original color or texture descriptors to similarity measures between this person and the exemplars in the reference set. A subspace is learned in which the correlations of the reference data from different cameras are maximized using Regularized Canonical Correlation Analysis (RCCA). For re-identification, the gallery data and the probe data are projected into this RCCA subspace and the reference descriptors (RDs) of the gallery and probe are generated by computing the similarity between them and the reference data.
A reference-based method is proposed for person re-identification across different cameras. The matching is conducted in reference space where the descriptor for a person is translated from the original color or texture descriptors to similarity measures between this person and the exemplars in the reference set. A subspace is learned in which the correlations of the reference data from different cameras are maximized using Regularized Canonical Correlation Analysis (RCCA). For re-identification, the gallery data and the probe data are projected into this RCCA subspace and the reference descriptors (RDs) of the gallery and probe are generated by computing the similarity between them and the reference data.
Person Re-Identification by Robust Canonical Correlation Analysis
 Due to significant view and pose change across non-overlapping cameras, directly matching data from different views is a challenging issue to solve. Proposed is a robust canonical correlation analysis (ROCCA) to match people from different views in a coherent subspace. Given a small training set, direct application of canonical correlation analysis (CCA) may lead to poor performance due to the inaccuracy in estimating the data covariance matrices. The proposed ROCCA with shrinkage estimation and smoothing technique is simple to implement and can robustly estimate the data covariance matrices with limited training samples.
Due to significant view and pose change across non-overlapping cameras, directly matching data from different views is a challenging issue to solve. Proposed is a robust canonical correlation analysis (ROCCA) to match people from different views in a coherent subspace. Given a small training set, direct application of canonical correlation analysis (CCA) may lead to poor performance due to the inaccuracy in estimating the data covariance matrices. The proposed ROCCA with shrinkage estimation and smoothing technique is simple to implement and can robustly estimate the data covariance matrices with limited training samples.
Multitarget Tracking in Nonoverlapping Cameras Using a Reference Set
 Tracking multiple targets in nonoverlapping cameras is challenging since the observations of the same targets are often separated by time and space. There might be significant appearance change of a target across camera views caused by variations in illumination conditions, poses, and camera imaging characteristics. Consequently, the same target may appear very different in two cameras, therefore, associating tracks in different camera views directly based on their appearance similarity is difficult and prone to error. In this paper, a novel reference set based appearance model is proposed to improve multitarget tracking in a network of nonoverlapping cameras.
Tracking multiple targets in nonoverlapping cameras is challenging since the observations of the same targets are often separated by time and space. There might be significant appearance change of a target across camera views caused by variations in illumination conditions, poses, and camera imaging characteristics. Consequently, the same target may appear very different in two cameras, therefore, associating tracks in different camera views directly based on their appearance similarity is difficult and prone to error. In this paper, a novel reference set based appearance model is proposed to improve multitarget tracking in a network of nonoverlapping cameras.
Understanding Dynamic Social Grouping Behaviors of Pedestrians
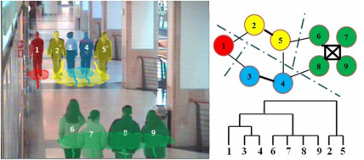 Inspired by sociological models of human collective behavior, presented is a framework for characterizing hierarchical social groups based on evolving tracklet interaction network (ETIN) where the tracklets of pedestrians are represented as nodes and the their grouping behaviors are captured by the edges with associated weights. We use non-overlapping snapshots of the interaction network and develop the framework for a unified dynamic group identification and tracklet association. The approach is evaluated quantitatively and qualitatively on videos of pedestrian scenes where manually labeled ground-truth is given.
Inspired by sociological models of human collective behavior, presented is a framework for characterizing hierarchical social groups based on evolving tracklet interaction network (ETIN) where the tracklets of pedestrians are represented as nodes and the their grouping behaviors are captured by the edges with associated weights. We use non-overlapping snapshots of the interaction network and develop the framework for a unified dynamic group identification and tracklet association. The approach is evaluated quantitatively and qualitatively on videos of pedestrian scenes where manually labeled ground-truth is given.
Soft biometrics integrated multi-target tracking
.png) In this paper, we present a soft biometrics based appearance model for multi-target tracking in a single camera. Tracklets, the short-term tracking results, are generated by linking detections in consecutive frames based on conservative constraints. Our goal is to “re-stitching” the adjacent tracklets that contain the same target so that robust long-term tracking results can be achieved. As the appearance of the same target may change greatly due to heavy occlusion, pose variations and changing lighting conditions, a discriminative appearance model is crucial for association-based tracking. Unlike most previous methods which simply use the similarity of color histograms or other low level features to construct the appearance model, we propose to use the fusion of soft biometrics generated from sub-tracklets to learn a discriminative appearance model in an online manner. Compared to low level features, soft biometrics are robust against appearance variation. The experimental results demonstrate that our method is robust and greatly improves the tracking performance over the state-of-the-art method.
In this paper, we present a soft biometrics based appearance model for multi-target tracking in a single camera. Tracklets, the short-term tracking results, are generated by linking detections in consecutive frames based on conservative constraints. Our goal is to “re-stitching” the adjacent tracklets that contain the same target so that robust long-term tracking results can be achieved. As the appearance of the same target may change greatly due to heavy occlusion, pose variations and changing lighting conditions, a discriminative appearance model is crucial for association-based tracking. Unlike most previous methods which simply use the similarity of color histograms or other low level features to construct the appearance model, we propose to use the fusion of soft biometrics generated from sub-tracklets to learn a discriminative appearance model in an online manner. Compared to low level features, soft biometrics are robust against appearance variation. The experimental results demonstrate that our method is robust and greatly improves the tracking performance over the state-of-the-art method.
An online learned elementary grouping model for multi-target tracking
.png) We introduce an online approach to learn possible elementary for inferring high level context that can be used to improve multi-target tracking in a data-association based framework. Unlike most existing association-based tracking approaches that use only low level information to build the affinity model and consider each target as an independent agent, we online learn social grouping behavior to provide additional information for producing more robust tracklets affinities. Social grouping behavior of pairwise targets is first learned from confident tracklets and encoded in a disjoint grouping graph. The grouping graph is further completed with the help of group tracking. The proposed method is efficient, handles group merge and split, and can be easily integrated into any basic affinity model. We evaluate our approach on two public datasets, and show significant improvements compared with state-of-the-art methods.
We introduce an online approach to learn possible elementary for inferring high level context that can be used to improve multi-target tracking in a data-association based framework. Unlike most existing association-based tracking approaches that use only low level information to build the affinity model and consider each target as an independent agent, we online learn social grouping behavior to provide additional information for producing more robust tracklets affinities. Social grouping behavior of pairwise targets is first learned from confident tracklets and encoded in a disjoint grouping graph. The grouping graph is further completed with the help of group tracking. The proposed method is efficient, handles group merge and split, and can be easily integrated into any basic affinity model. We evaluate our approach on two public datasets, and show significant improvements compared with state-of-the-art methods.
Context-aware reinforcement learning for re-identification in a video network
.png) Re-identification of people in a large camera network has gained popularity in recent years. The problem still remains challenging due to variations across cameras. A variety of techniques which concentrate on either features or matching have been proposed. Similar to majority of computer vision approaches, these techniques use fixed features and/or parameters. As the operating conditions of a vision system change, its performance deteriorates as fixed features and/or parameters are no longer suited for the new conditions. We propose to use context-aware reinforcement learning to handle this challenge. We capture the changing operating conditions through context and learn mapping between context and feature weights to improve the re-identification accuracy. The results are shown using videos from a camera network that consists of eight cameras.
Re-identification of people in a large camera network has gained popularity in recent years. The problem still remains challenging due to variations across cameras. A variety of techniques which concentrate on either features or matching have been proposed. Similar to majority of computer vision approaches, these techniques use fixed features and/or parameters. As the operating conditions of a vision system change, its performance deteriorates as fixed features and/or parameters are no longer suited for the new conditions. We propose to use context-aware reinforcement learning to handle this challenge. We capture the changing operating conditions through context and learn mapping between context and feature weights to improve the re-identification accuracy. The results are shown using videos from a camera network that consists of eight cameras.
Improving person re-identification by soft biometrics based re-ranking
.png) The problem of person re-identification is to recognize a target subject across non-overlapping distributed cameras at different times and locations. In a real-world scenario, person re-identification is challenging due to the dramatic changes in a subject’s appearance in terms of pose, illumination, background, and occlusion. Existing approaches either try to design robust features to identify a subject across different views or learn distance metrics to maximize the similarity between different views of the same person and minimize the similarity between different views of different persons. In this paper, we aim at improving the reidentification performance by reranking the returned results based on soft biometric attributes, such as gender, which can describe probe and gallery subjects at a higher level. During reranking, the soft biometric attributes are detected and attribute-based distance scores are calculated between pairs of images by using a regression model. These distance scores are used for reranking the initially returned matches. Experiments on a benchmark database with different baseline re-identification methods show that reranking improves the recognition accuracy by moving upwards the returned matches from gallery that share the same soft biometric attributes as the probe subject.
The problem of person re-identification is to recognize a target subject across non-overlapping distributed cameras at different times and locations. In a real-world scenario, person re-identification is challenging due to the dramatic changes in a subject’s appearance in terms of pose, illumination, background, and occlusion. Existing approaches either try to design robust features to identify a subject across different views or learn distance metrics to maximize the similarity between different views of the same person and minimize the similarity between different views of different persons. In this paper, we aim at improving the reidentification performance by reranking the returned results based on soft biometric attributes, such as gender, which can describe probe and gallery subjects at a higher level. During reranking, the soft biometric attributes are detected and attribute-based distance scores are calculated between pairs of images by using a regression model. These distance scores are used for reranking the initially returned matches. Experiments on a benchmark database with different baseline re-identification methods show that reranking improves the recognition accuracy by moving upwards the returned matches from gallery that share the same soft biometric attributes as the probe subject.
Reference set based appearance model for tracking across non-overlapping cameras
.png) Multi-target tracking in non-overlapping cameras is challenging due to the vast appearance change of the targets across camera views caused by variations in illumination conditions, poses, and camera imaging characteristics. Therefore, direct track association is difficult and prone to error. In this paper, we propose a novel reference set based appearance model to improve multi-target tracking in a network of nonoverlapping video cameras. Unlike previous work, a reference set is constructed for a pair of cameras, containing targets appearing in both camera views. For track association, instead of comparing the appearance of two targets in different camera views directly, they are compared to the reference set. The reference set acts as a basis to represent a target by measuring the similarity between the target and each of the individuals in the reference set. The effectiveness of the proposed method over the baseline models on challenging realworld multi-camera video data is validated by the experiments.
Multi-target tracking in non-overlapping cameras is challenging due to the vast appearance change of the targets across camera views caused by variations in illumination conditions, poses, and camera imaging characteristics. Therefore, direct track association is difficult and prone to error. In this paper, we propose a novel reference set based appearance model to improve multi-target tracking in a network of nonoverlapping video cameras. Unlike previous work, a reference set is constructed for a pair of cameras, containing targets appearing in both camera views. For track association, instead of comparing the appearance of two targets in different camera views directly, they are compared to the reference set. The reference set acts as a basis to represent a target by measuring the similarity between the target and each of the individuals in the reference set. The effectiveness of the proposed method over the baseline models on challenging realworld multi-camera video data is validated by the experiments.
Optimizing Crowd Simulation Based on Real Video Data
.png) Tracking of individuals and groups in video is an active topic of research in image processing and analyzing. This paper proposes an approach for the purpose of guiding a crowd simulation algorithm to mimic the trajectories of individuals in crowds as observed in real videos, which can be further used in image processing and computer vision research extensively. This is achieved by tuning the parameters used in the simulation automatically. In our experiment, the simulation trajectories are generated by the RVO2 library and the real trajectories are extracted from the UCSD crowd video dataset. The Edit Distance on Real sequence (EDR) between the simulated and real trajectories are calculated. A genetic algorithm is applied to find the parameters that minimize the distances. The experimental results demonstrate that the trajectory distances between simulation and reality are significantly reduced after tuning the parameters of the simulator.
Tracking of individuals and groups in video is an active topic of research in image processing and analyzing. This paper proposes an approach for the purpose of guiding a crowd simulation algorithm to mimic the trajectories of individuals in crowds as observed in real videos, which can be further used in image processing and computer vision research extensively. This is achieved by tuning the parameters used in the simulation automatically. In our experiment, the simulation trajectories are generated by the RVO2 library and the real trajectories are extracted from the UCSD crowd video dataset. The Edit Distance on Real sequence (EDR) between the simulated and real trajectories are calculated. A genetic algorithm is applied to find the parameters that minimize the distances. The experimental results demonstrate that the trajectory distances between simulation and reality are significantly reduced after tuning the parameters of the simulator.
Analysis-by-synthesis: Pedestrian tracking with crowd simulation models in a multi-camera video network
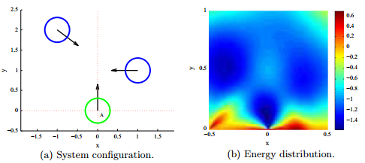 A multi-camera tracking system with integrated crowd simulation is proposed in order to explore the possibility to make homography information more helpful. Two crowd simulators with different simulation strategies are used to investigate the influence of the simulation strategy on the final tracking performance. The performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) metrics, for all the camera views and the results obtained under real-world coordinates.
A multi-camera tracking system with integrated crowd simulation is proposed in order to explore the possibility to make homography information more helpful. Two crowd simulators with different simulation strategies are used to investigate the influence of the simulation strategy on the final tracking performance. The performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) metrics, for all the camera views and the results obtained under real-world coordinates.
Reference-Based Person Re-Identification
 Person re-identification refers to recognizing people
across non-overlapping cameras at different times and locations.
Due to the variations in pose, illumination condition,
background, and occlusion, person re-identification
is inherently difficult. We propose a reference based
method for across camera person re-identification. In
the training, we learn a subspace in which the correlations
of the reference data from different cameras are maximized
using Regularized Canonical Correlation Analysis (RCCA).
For re-identification, the gallery data and the probe data
are projected into the RCCA subspace and the reference descriptors
(RDs) of the gallery and probe are constructed by
measuring the similarity between them and the reference
data. The identity of the probe is determined by comparing
the RD of the probe and the RDs of the gallery. Experiments
on benchmark dataset show that the proposed method outperforms
the state-of-the-art approaches.
Person re-identification refers to recognizing people
across non-overlapping cameras at different times and locations.
Due to the variations in pose, illumination condition,
background, and occlusion, person re-identification
is inherently difficult. We propose a reference based
method for across camera person re-identification. In
the training, we learn a subspace in which the correlations
of the reference data from different cameras are maximized
using Regularized Canonical Correlation Analysis (RCCA).
For re-identification, the gallery data and the probe data
are projected into the RCCA subspace and the reference descriptors
(RDs) of the gallery and probe are constructed by
measuring the similarity between them and the reference
data. The identity of the probe is determined by comparing
the RD of the probe and the RDs of the gallery. Experiments
on benchmark dataset show that the proposed method outperforms
the state-of-the-art approaches.
Reference-based scheme combined with K-SVD for scene image categorization
.png) A reference-based algorithm for scene image categorization is presented in this letter. In addition to using a reference-set for images representation, we also associate the reference-set with training data in sparse codes during the dictionary learning process. The reference-set is combined with the reconstruction error to form a unified objective function. The optimal solution is efficiently obtained using the K-SVD algorithm. After dictionaries are constructed, Locality-constrained Linear Coding (LLC) features of images are extracted. Then, we represent each image feature vector using the similarities between the image and the reference-set, leading to a significant reduction of the dimensionality in the feature space. Experimental results demonstrate that our method achieves outstanding performance.
A reference-based algorithm for scene image categorization is presented in this letter. In addition to using a reference-set for images representation, we also associate the reference-set with training data in sparse codes during the dictionary learning process. The reference-set is combined with the reconstruction error to form a unified objective function. The optimal solution is efficiently obtained using the K-SVD algorithm. After dictionaries are constructed, Locality-constrained Linear Coding (LLC) features of images are extracted. Then, we represent each image feature vector using the similarities between the image and the reference-set, leading to a significant reduction of the dimensionality in the feature space. Experimental results demonstrate that our method achieves outstanding performance.
Single camera multi-person tracking based on crowd simulation
.png) Tracking individuals in video sequences, especially in crowded scenes, is still a challenging research topic in the area of pattern recognition and computer vision. However, current single camera tracking approaches are mostly based on visual features only. The novelty of the approach proposed in this paper is the integration of evidences from a crowd simulation algorithm into a pure vision based method. Based on a stateof-the-art tracking-by-detection method, the integration is achieved by evaluating particle weights with additional prediction of individual positions, which is obtained from the crowd simulation algorithm. Our experimental results indicate that, by integrating simulation, the multi-person tracking performance such as MOTP and MOTA can be increased by an average about 2% and 5%, which provides significant evidence for the effectiveness of our approach.
Tracking individuals in video sequences, especially in crowded scenes, is still a challenging research topic in the area of pattern recognition and computer vision. However, current single camera tracking approaches are mostly based on visual features only. The novelty of the approach proposed in this paper is the integration of evidences from a crowd simulation algorithm into a pure vision based method. Based on a stateof-the-art tracking-by-detection method, the integration is achieved by evaluating particle weights with additional prediction of individual positions, which is obtained from the crowd simulation algorithm. Our experimental results indicate that, by integrating simulation, the multi-person tracking performance such as MOTP and MOTA can be increased by an average about 2% and 5%, which provides significant evidence for the effectiveness of our approach.
Integrating crowd simulation for pedestrian tracking in a multi-camera system
.png) Multi-camera multi-target tracking is one of the most active research topics in computer vision. However, many challenges remain to achieve robust performance in real-world video networks. In this paper we extend the state-of-the-art single camera tracking method, with both detection and crowd simulation, to a multiple camera tracking approach that exploits crowd simulation and uses principal axis-based integration. The experiments are conducted on PETS 2009 data set and the performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) based on the position of each pedestrian on the ground plane. It is demonstrated that the information from crowd simulation can provide significant advantage for tracking multiple pedestrians through multiple cameras.
Multi-camera multi-target tracking is one of the most active research topics in computer vision. However, many challenges remain to achieve robust performance in real-world video networks. In this paper we extend the state-of-the-art single camera tracking method, with both detection and crowd simulation, to a multiple camera tracking approach that exploits crowd simulation and uses principal axis-based integration. The experiments are conducted on PETS 2009 data set and the performance is evaluated by multiple object tracking precision and accuracy (MOTP and MOTA) based on the position of each pedestrian on the ground plane. It is demonstrated that the information from crowd simulation can provide significant advantage for tracking multiple pedestrians through multiple cameras.
Utility-based camera assignment in a video network: A game theoretic framework
.png) In this paper, an approach for camera assignment and handoff in a video network based on a set of user-supplied criteria is proposed. The approach is based on game theory, where bargaining mechanisms are considered for collaborations as well as for resolving conflicts among the available cameras. Camera utilities and person utilities are computed based on a set of user-supplied criteria, which are used in the process of developing the bargaining mechanisms. Different criteria and their combination are compared with each other to understand their effect on camera assignment. Experiments for multicamera multiperson cases are provided to corroborate the proposed approach. Intuitive evaluation measures are used to evaluate the performance of the system in real-world scenarios. The proposed approach is also compared with two recent approaches based on different principles. The experimental results show that the proposed approach is computationally more efficient, more robust and more flexible in dealing with the user-supplied criteria.
In this paper, an approach for camera assignment and handoff in a video network based on a set of user-supplied criteria is proposed. The approach is based on game theory, where bargaining mechanisms are considered for collaborations as well as for resolving conflicts among the available cameras. Camera utilities and person utilities are computed based on a set of user-supplied criteria, which are used in the process of developing the bargaining mechanisms. Different criteria and their combination are compared with each other to understand their effect on camera assignment. Experiments for multicamera multiperson cases are provided to corroborate the proposed approach. Intuitive evaluation measures are used to evaluate the performance of the system in real-world scenarios. The proposed approach is also compared with two recent approaches based on different principles. The experimental results show that the proposed approach is computationally more efficient, more robust and more flexible in dealing with the user-supplied criteria.
Continuous learning of a multi-layered network topology in a video camera network
.png) A multilayered camera network architecture with nodes as entry/exit points, cameras, and clusters of cameras at different layers is proposed. This paper integrates face recognition that provides robustness to appearance changes and better models the time-varying traffic patterns in the network. The statistical dependence between the nodes, indicating the connectivity and traffic patterns of the camera network, is represented by a weighted directed graph and transition times that may have multimodal distributions. The traffic patterns and the network topology may be changing in the dynamic environment. We propose a Monte Carlo Expectation-Maximization algorithm-based continuous learning mechanism to capture the latent dynamically changing characteristics of the network topology. In the experiments, a nine-camera network with twenty-five nodes (at the lowest level) is analyzed both in simulation and in real-life experiments and compared with previous approaches.
A multilayered camera network architecture with nodes as entry/exit points, cameras, and clusters of cameras at different layers is proposed. This paper integrates face recognition that provides robustness to appearance changes and better models the time-varying traffic patterns in the network. The statistical dependence between the nodes, indicating the connectivity and traffic patterns of the camera network, is represented by a weighted directed graph and transition times that may have multimodal distributions. The traffic patterns and the network topology may be changing in the dynamic environment. We propose a Monte Carlo Expectation-Maximization algorithm-based continuous learning mechanism to capture the latent dynamically changing characteristics of the network topology. In the experiments, a nine-camera network with twenty-five nodes (at the lowest level) is analyzed both in simulation and in real-life experiments and compared with previous approaches.
Utility-Based Dynamic Camera Assignment and Hand-Off in a Video Network
.png) In this paper we propose an approach for multi-camera multi-person seamless tracking that allows camera assignment and hand-off based on a set of user-supplied criteria. The approach is based on the application of game theory to camera assignment problem. Bargaining mechanisms are considered for collaborations as well as for resolving conflicts among the available cameras. Camera utilities and person utilities are computed based on a set of criteria. They are used in the process of developing the bargaining mechanisms. Experiments for multi-camera multi-person tracking are provided. Several different criteria and their combination of them are carried out and compared with each other to corroborate the proposed approach.
In this paper we propose an approach for multi-camera multi-person seamless tracking that allows camera assignment and hand-off based on a set of user-supplied criteria. The approach is based on the application of game theory to camera assignment problem. Bargaining mechanisms are considered for collaborations as well as for resolving conflicts among the available cameras. Camera utilities and person utilities are computed based on a set of criteria. They are used in the process of developing the bargaining mechanisms. Experiments for multi-camera multi-person tracking are provided. Several different criteria and their combination of them are carried out and compared with each other to corroborate the proposed approach.
Tracking humans using multimodal fusion
.png) Human motion detection plays an important role in automated surveillance systems. However, it is challenging to detect non-rigid moving objects (e.g. human) robustly in a cluttered environment. In this paper, we compare two approaches for detecting walking humans using multi-modal measurementsvideo and audio sequences. The first approach is based on the Time-Delay Neural Network (TDNN), which fuses the audio and visual data at the feature level to detect the walking human. The second approach employs the Bayesian Network (BN) for jointly modeling the video and audio signals. Parameter estimation of the graphical models is executed using the Expectation-Maximization (EM) algorithm. And the location of the target is tracked by the Bayes inference. Experiments are performed in several indoor and outdoor scenarios: in the lab, more than one person walking, occlusion by bushes etc. The comparison of performance and efficiency of the two approaches are also presented.
Human motion detection plays an important role in automated surveillance systems. However, it is challenging to detect non-rigid moving objects (e.g. human) robustly in a cluttered environment. In this paper, we compare two approaches for detecting walking humans using multi-modal measurementsvideo and audio sequences. The first approach is based on the Time-Delay Neural Network (TDNN), which fuses the audio and visual data at the feature level to detect the walking human. The second approach employs the Bayesian Network (BN) for jointly modeling the video and audio signals. Parameter estimation of the graphical models is executed using the Expectation-Maximization (EM) algorithm. And the location of the target is tracked by the Bayes inference. Experiments are performed in several indoor and outdoor scenarios: in the lab, more than one person walking, occlusion by bushes etc. The comparison of performance and efficiency of the two approaches are also presented.
Multistrategy fusion using mixture model for moving object detection
.png) In a video surveillance domain, mixture models are used in conjunction with a variety of features and filters to detect and track moving objects. However, these systems do not provide clear performance results at the pixel detection level. In this paper, we apply the mixture model to provide several fusion strategies based on the competitive and cooperative principles of integration which we call OR, and AND strategies. In addition, we apply the Dempster-Shafer method to mixture models for object detection. Using two video databases, we show the performance of each fusion strategy using receiver operating characteristic (ROC) curves.
In a video surveillance domain, mixture models are used in conjunction with a variety of features and filters to detect and track moving objects. However, these systems do not provide clear performance results at the pixel detection level. In this paper, we apply the mixture model to provide several fusion strategies based on the competitive and cooperative principles of integration which we call OR, and AND strategies. In addition, we apply the Dempster-Shafer method to mixture models for object detection. Using two video databases, we show the performance of each fusion strategy using receiver operating characteristic (ROC) curves.
CAOS: A Hierarchical Robot Control System
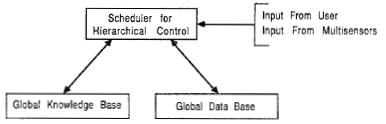 Control systems which enabled robots to behave intelligently was a major issue in the process for automating factories. A hierarchical robot control system, termed CAOS for Control using Action Oriented Schemas with ideas taken from the neurosciences is presented. We used action oriented schemas (called neuroschemas) as the basic building blocks in a hierarchical control structure which was being implemented on a BBN Butterfly Parallel Processor. Serial versions in C and LISP are presented with examples showing how CAOS achieved the goals of recognizing three dimensional polyhedral objects.
Control systems which enabled robots to behave intelligently was a major issue in the process for automating factories. A hierarchical robot control system, termed CAOS for Control using Action Oriented Schemas with ideas taken from the neurosciences is presented. We used action oriented schemas (called neuroschemas) as the basic building blocks in a hierarchical control structure which was being implemented on a BBN Butterfly Parallel Processor. Serial versions in C and LISP are presented with examples showing how CAOS achieved the goals of recognizing three dimensional polyhedral objects.
Knowledge Based Robot Control on a Multiprocessor in a Multisensor Environment
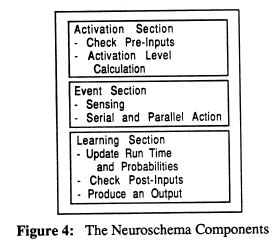 Knowledge based robot control for automatic inspection, manipulation, and assembly of objects was projected to be a common denominator in highly automated factories. These tasks were to be handled routinely by intelligent, computer-controlled robots with multiprocessing and multi-sensor features which contribute to flexibility and adaptability. Discussed is the work with CAOS which was a knowledge based robot control system. The structure and components of CAOS were modeled after the human brain using neuroschemata at the basic building blocks which incorporated parallel processing, hierarchical, and heterarchical control.
Knowledge based robot control for automatic inspection, manipulation, and assembly of objects was projected to be a common denominator in highly automated factories. These tasks were to be handled routinely by intelligent, computer-controlled robots with multiprocessing and multi-sensor features which contribute to flexibility and adaptability. Discussed is the work with CAOS which was a knowledge based robot control system. The structure and components of CAOS were modeled after the human brain using neuroschemata at the basic building blocks which incorporated parallel processing, hierarchical, and heterarchical control.
Hierarchical Robot Control in a Multi-Sensor Environment
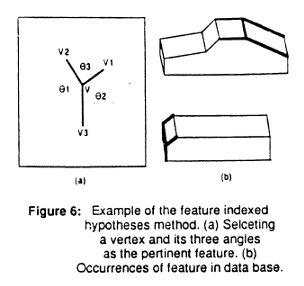 Automatic recognition, inspection, manipulation, and assembly of objects was projected to be a common denominator in highly automated factories. These tasks were to be handled routinely by intelligent, computer-controlled robots with multiprocessing and multi-sensor features which contribute to flexibility and adaptability.The control of a robot in such a multisensor environment became of crucial importance as the complexity of the problem grew exponentially with the number of sensors, tasks, commands, and objects. An approach which uses CAD (Computer Aided Design) based geometric and functional models of objects together with action oriented neuroschemas to recognize and manipulate objects by a robot in a multisensor environment is presented.
Automatic recognition, inspection, manipulation, and assembly of objects was projected to be a common denominator in highly automated factories. These tasks were to be handled routinely by intelligent, computer-controlled robots with multiprocessing and multi-sensor features which contribute to flexibility and adaptability.The control of a robot in such a multisensor environment became of crucial importance as the complexity of the problem grew exponentially with the number of sensors, tasks, commands, and objects. An approach which uses CAD (Computer Aided Design) based geometric and functional models of objects together with action oriented neuroschemas to recognize and manipulate objects by a robot in a multisensor environment is presented.
A Framework for Distributed Sensing and Control
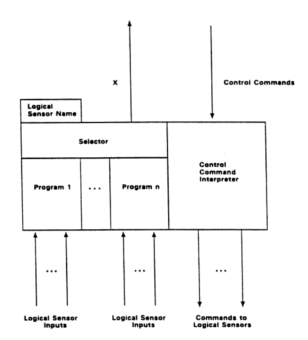 Logical Sensor Specification (LSS) was introduced as a convenient means for specifying multi-sensor systems and their implementations. We demonstrated how control issues could be handled in the context of LSS. In particular the Logical Sensor Specification was extended to include a control mechanism which permitted control information to flow from more centralized processing to more peripheral processes, and be generated locally in the logical sensor by means of a micro-expert system specific to the interface represented by the given logical sensor.
Logical Sensor Specification (LSS) was introduced as a convenient means for specifying multi-sensor systems and their implementations. We demonstrated how control issues could be handled in the context of LSS. In particular the Logical Sensor Specification was extended to include a control mechanism which permitted control information to flow from more centralized processing to more peripheral processes, and be generated locally in the logical sensor by means of a micro-expert system specific to the interface represented by the given logical sensor.
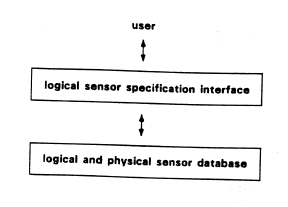
The Synthesis of Logical Sensor Specifications
 A coherent automated manufacturing system needed to include CAD/CAM, computer vision, and object manipulation but most systems which supported CAD/CAM did not provide for vision or manipulation and similarly, vision and manipulation systems incorporated no explicit relation to CAD/CAM models. CAD/CAM systems emerged which allowed the designer to conceive and model an object and automatically manufacture the object to the prescribed specifications. If recognition or manipulation was to be performed, existing vision systems relied on models generated in an ad hoc manner for the vision or recognition process. Although both Vision and CAD/CAM systems relied on models of the objects involved, different modeling schemes were used in each case. A more unified system allowed vision models to be generated from the CAD database. The model generation was guided by the class of objects being constructed, the constraints imposed by the robotic workcell environment (fixtures, sensors, manipulators, and effectors). We proposed a framework in which objects were designed using an existing CAGD system and logical sensor specifications were automatically synthesized and used for visual recognition and manipulation.
A coherent automated manufacturing system needed to include CAD/CAM, computer vision, and object manipulation but most systems which supported CAD/CAM did not provide for vision or manipulation and similarly, vision and manipulation systems incorporated no explicit relation to CAD/CAM models. CAD/CAM systems emerged which allowed the designer to conceive and model an object and automatically manufacture the object to the prescribed specifications. If recognition or manipulation was to be performed, existing vision systems relied on models generated in an ad hoc manner for the vision or recognition process. Although both Vision and CAD/CAM systems relied on models of the objects involved, different modeling schemes were used in each case. A more unified system allowed vision models to be generated from the CAD database. The model generation was guided by the class of objects being constructed, the constraints imposed by the robotic workcell environment (fixtures, sensors, manipulators, and effectors). We proposed a framework in which objects were designed using an existing CAGD system and logical sensor specifications were automatically synthesized and used for visual recognition and manipulation.
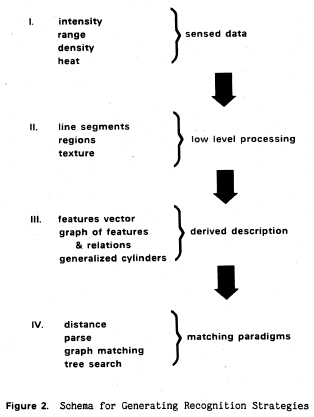
ASP: An Algorithm and Sensor Performance Evaluation System
 Described is a methodology which permitted the precise characterization of sensors, the specification of algorithms which transformed the sensor data, and the quantitative analysis of combinations of algorithms and sensors. Such analysis made it possible to determine appropriate sensor/algorithm combinations subject to a wide variety of criteria including: performance, computational complexity (both space and time), possibility for concurrency, modularization, and the use of multi-sensor systems for greater fault tolerance and reliability.
Described is a methodology which permitted the precise characterization of sensors, the specification of algorithms which transformed the sensor data, and the quantitative analysis of combinations of algorithms and sensors. Such analysis made it possible to determine appropriate sensor/algorithm combinations subject to a wide variety of criteria including: performance, computational complexity (both space and time), possibility for concurrency, modularization, and the use of multi-sensor systems for greater fault tolerance and reliability.
Distributed Control in the Multi-Sensor Kernel System
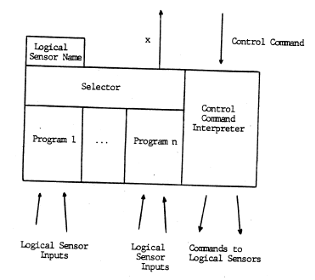 The Multi-Sensor Kernel System (MKS) has been introduced as a convenient mechanism for specifying multi-sensor systems and their implementations. We demonstrated how control issues could be handled in the context of MKS. In particular, the Logical Sensor Specification was extended to include a control mechanism which permitted control information to flow from more centralized processing to more peripheral processes and be generated locally in the logical sensor by means of a micro-expert system specific to the interface represented by the given logical sensor.
The Multi-Sensor Kernel System (MKS) has been introduced as a convenient mechanism for specifying multi-sensor systems and their implementations. We demonstrated how control issues could be handled in the context of MKS. In particular, the Logical Sensor Specification was extended to include a control mechanism which permitted control information to flow from more centralized processing to more peripheral processes and be generated locally in the logical sensor by means of a micro-expert system specific to the interface represented by the given logical sensor.
|


