Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
Reinforcement learning for combining relevance feedback techniques in image retrieval
.jpg) Relevance feedback (RF) is an interactive process which refines the retrievals by utilizing user’s feedback history. Most researchers strive to develop new RF techniques and ignore the advantages of existing ones. In this paper, we propose an image relevance reinforcement learning (IRRL) model for integrating existing RF techniques. Various integration schemes are presented and a long-term shared memory is used to exploit the retrieval experience from multiple users. Also, a concept digesting method is proposed to reduce the complexity of storage demand. The experimental results manifest that the integration of multiple RF approaches gives better retrieval performance than using one RF technique alone, and that the sharing of relevance knowledge between multiple query sessions also provides significant contributions for improvement. Further, the storage demand is significantly reduced by the concept digesting technique. This shows the scalability of the proposed model against a growing-size database.
Relevance feedback (RF) is an interactive process which refines the retrievals by utilizing user’s feedback history. Most researchers strive to develop new RF techniques and ignore the advantages of existing ones. In this paper, we propose an image relevance reinforcement learning (IRRL) model for integrating existing RF techniques. Various integration schemes are presented and a long-term shared memory is used to exploit the retrieval experience from multiple users. Also, a concept digesting method is proposed to reduce the complexity of storage demand. The experimental results manifest that the integration of multiple RF approaches gives better retrieval performance than using one RF technique alone, and that the sharing of relevance knowledge between multiple query sessions also provides significant contributions for improvement. Further, the storage demand is significantly reduced by the concept digesting technique. This shows the scalability of the proposed model against a growing-size database.
Adaptive target recognition
.png) Target recognition is a multilevel process requiring a sequence of algorithms at low, intermediate and high levels. Generally, such systems are open loop with no feedback between levels and assuring their performance at the given probability of correct identification (PCI) and probability of false alarm (P f) is a key challenge in computer vision and pattern recognition research. In this paper, a robust closed-loop system for recognition of SAR images based on reinforcement learning is presented. The parameters in model-based SAR target recognition are learned. It has been experimentally validated by learning the parameters of the recognition system for SAR imagery, successfully recognizing articulated targets, targets of different configuration and targets at different depression angles.
Target recognition is a multilevel process requiring a sequence of algorithms at low, intermediate and high levels. Generally, such systems are open loop with no feedback between levels and assuring their performance at the given probability of correct identification (PCI) and probability of false alarm (P f) is a key challenge in computer vision and pattern recognition research. In this paper, a robust closed-loop system for recognition of SAR images based on reinforcement learning is presented. The parameters in model-based SAR target recognition are learned. It has been experimentally validated by learning the parameters of the recognition system for SAR imagery, successfully recognizing articulated targets, targets of different configuration and targets at different depression angles.
Learning to Perceive Objects for Autonomous Recognition
 Machine perception techniques that typically used segmentation followed by object recognition lacked the required robustness to cope with the large variety of situations encountered in real-world navigation. Many existing techniques were brittle in the sense that even minor changes in the expected task environment (e.g., different lighting conditions, geometrical distortion, etc.) could severely degrade the performance of the system or even make it fail completely. Presented is a system that achieved robust performance by using local reinforcement learning to induce a highly adaptive mapping from input images to segmentation strategies for successful recognition which was verified through experiments on a large set of real images of traffic signs.This was accomplished by using the confidence level of model matching as reinforcement to drive learning. Local reinforcement learning gave rise to better improvement in recognition performance.
Machine perception techniques that typically used segmentation followed by object recognition lacked the required robustness to cope with the large variety of situations encountered in real-world navigation. Many existing techniques were brittle in the sense that even minor changes in the expected task environment (e.g., different lighting conditions, geometrical distortion, etc.) could severely degrade the performance of the system or even make it fail completely. Presented is a system that achieved robust performance by using local reinforcement learning to induce a highly adaptive mapping from input images to segmentation strategies for successful recognition which was verified through experiments on a large set of real images of traffic signs.This was accomplished by using the confidence level of model matching as reinforcement to drive learning. Local reinforcement learning gave rise to better improvement in recognition performance.
Closed-Loop Object Recognition Using Reinforcement Learning
 Current computer vision systems are not robust enough
for most real-world
applications. In contrast, the system presented here achieves robust performance by using reinforcement
learning to induce a mapping from input images to corresponding segmentation parameters. This is
accomplished by using the confidence level of model matching as a reinforcement signal for a team of
learning automata to search for segmentation parameters during training.
Current computer vision systems are not robust enough
for most real-world
applications. In contrast, the system presented here achieves robust performance by using reinforcement
learning to induce a mapping from input images to corresponding segmentation parameters. This is
accomplished by using the confidence level of model matching as a reinforcement signal for a team of
learning automata to search for segmentation parameters during training.
Delayed Reinforcement Learning for Adaptive Image Segmentation and Feature Extraction
 Object recognition was a multilevel process requiring a sequence of algorithms at low, intermediate, and high levels. Generally, such systems were open loop with no feedback between levels and ensuring their robustness was a key challenge in computer vision and pattern recognition research. A robust closed-loop system based on “delayed” reinforcement learning was introduced and the parameters of a multilevel system employed for model-based object recognition were learned. The method improved recognition results over time by using the output at the highest level as feedback for the learning system. It was experimentally validated by learning the parameters of image segmentation and feature extraction and thereby recognizing 2-D objects. The approach systematically controlled feedback in a multi-level vision system and showed promise in approaching a long-standing problem in the field of computer vision and pattern recognition.
Object recognition was a multilevel process requiring a sequence of algorithms at low, intermediate, and high levels. Generally, such systems were open loop with no feedback between levels and ensuring their robustness was a key challenge in computer vision and pattern recognition research. A robust closed-loop system based on “delayed” reinforcement learning was introduced and the parameters of a multilevel system employed for model-based object recognition were learned. The method improved recognition results over time by using the output at the highest level as feedback for the learning system. It was experimentally validated by learning the parameters of image segmentation and feature extraction and thereby recognizing 2-D objects. The approach systematically controlled feedback in a multi-level vision system and showed promise in approaching a long-standing problem in the field of computer vision and pattern recognition.
Adaptive Target Recognition Using Reinforcement Learning
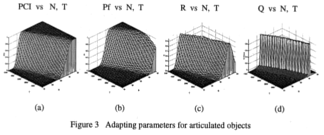 Research focused on using reinforcement learning to improve the performance of a SAR recognition engine is presented. We developed a learning algorithm which can direct the SAR recognition engine to perform at or close to a particular user prespecified performance point on the ROC curve of the engine.
Research focused on using reinforcement learning to improve the performance of a SAR recognition engine is presented. We developed a learning algorithm which can direct the SAR recognition engine to perform at or close to a particular user prespecified performance point on the ROC curve of the engine.
Local Reinforcement Learning for Object Recognition
 Computer vision systems whose basic methodology was open-loop or filter type typically used image segmentation followed by object recognition algorithms. These systems were not robust for most real-world applications. In contrast, the system presented here achieved robust performance by using local reinforcement learning to induce a highly adaptive mapping from input images to segmentation strategies. This was accomplished by using the confidence level of model matching as reinforcement to drive learning. The system was verified through experiments on a large set of real images.
Computer vision systems whose basic methodology was open-loop or filter type typically used image segmentation followed by object recognition algorithms. These systems were not robust for most real-world applications. In contrast, the system presented here achieved robust performance by using local reinforcement learning to induce a highly adaptive mapping from input images to segmentation strategies. This was accomplished by using the confidence level of model matching as reinforcement to drive learning. The system was verified through experiments on a large set of real images.
Closed-Loop Object Recognition Using Reinforcement Learning
.png) Computer vision systems whose basic methodology was open-loop or filter type typically used image segmentation followed by object recognition algorithms, but these systems were not robust for most real world applications. In contrast, the system presented here achieved robust performance by using reinforcement learning to induce a mapping from input images to corresponding segmentation parameters. This was accomplished by using the confidence level of model matching as a reinforcement signal for a team of learning automata to search for segmentation parameters during training. The use of the recognition algorithm was part of the evaluation function for image segmentation and gave rise to significant improvement of the system performance by automatic generation of recognition strategies. The system was verified through experiments on sequences of color images with varying external conditions.
Computer vision systems whose basic methodology was open-loop or filter type typically used image segmentation followed by object recognition algorithms, but these systems were not robust for most real world applications. In contrast, the system presented here achieved robust performance by using reinforcement learning to induce a mapping from input images to corresponding segmentation parameters. This was accomplished by using the confidence level of model matching as a reinforcement signal for a team of learning automata to search for segmentation parameters during training. The use of the recognition algorithm was part of the evaluation function for image segmentation and gave rise to significant improvement of the system performance by automatic generation of recognition strategies. The system was verified through experiments on sequences of color images with varying external conditions.
Delayed Reinforcement Learning for Closed-Loop Object Recognition
 Object recognition was a multi-level process requiring a sequence of algorithms at low, intermediate and high levels. Generally, such systems were open loop with no feedback between levels and ensuring their robustness was a key challenge in computer vision research. A robust closed-loop system based on “delayed” reinforcement learning is introduced and the parameters of a multi-level system employed for model-based object recognition are learned. The method improved recognition results over time by using the output at the highest level as feedback for the learning system. It had been experimentally validated by learning the parameters of image segmentation and feature extraction and thereby recognized 2-D objects. The approach systematically controlled feedback in a multi-level vision system and provided a potential solution to a long-standing problem in the field of computer vision.
Object recognition was a multi-level process requiring a sequence of algorithms at low, intermediate and high levels. Generally, such systems were open loop with no feedback between levels and ensuring their robustness was a key challenge in computer vision research. A robust closed-loop system based on “delayed” reinforcement learning is introduced and the parameters of a multi-level system employed for model-based object recognition are learned. The method improved recognition results over time by using the output at the highest level as feedback for the learning system. It had been experimentally validated by learning the parameters of image segmentation and feature extraction and thereby recognized 2-D objects. The approach systematically controlled feedback in a multi-level vision system and provided a potential solution to a long-standing problem in the field of computer vision.
|


