
|

|
Ev ve Ofis taşıma sektöründe lider olmak.Teknolojiyi takip ederek bunu müşteri menuniyeti amacı için kullanmak.Sektörde marka olmak.
İstanbul evden eve nakliyat
Misyonumuz sayesinde edindiğimiz müşteri memnuniyeti ve güven ile müşterilerimizin bizi tavsiye etmelerini sağlamak.
A dense flow-based framework for real-time object registration under compound motion
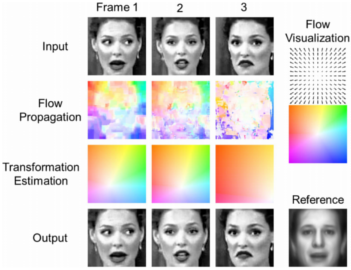 Tracking and measuring surface deformation while the object itself is also moving was a challenging, yet important problem in many video analysis tasks. For example, video-based facial expression recognition required tracking non-rigid motions of facial features without being affected by any rigid motions of the head. Presented is a generic video alignment framework to extract and characterize surface deformations accompanied by rigid-body motions with respect to a fixed reference (a canonical form). Also proposed is a generic model for object alignment in a Bayesian framework, and rigorously showed that a special case of the model results in a SIFT flow and optical flow based least-square problem. The proposed algorithm was evaluated on three applications, including the analysis of subtle facial muscle dynamics in spontaneous expressions, face image super-resolution, and generic object registration.
Tracking and measuring surface deformation while the object itself is also moving was a challenging, yet important problem in many video analysis tasks. For example, video-based facial expression recognition required tracking non-rigid motions of facial features without being affected by any rigid motions of the head. Presented is a generic video alignment framework to extract and characterize surface deformations accompanied by rigid-body motions with respect to a fixed reference (a canonical form). Also proposed is a generic model for object alignment in a Bayesian framework, and rigorously showed that a special case of the model results in a SIFT flow and optical flow based least-square problem. The proposed algorithm was evaluated on three applications, including the analysis of subtle facial muscle dynamics in spontaneous expressions, face image super-resolution, and generic object registration.
Temporal dynamics of tip fluorescence predict cell growth behavior in pollen tubes
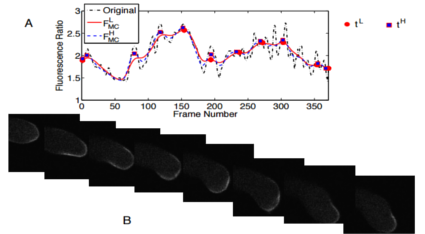 Proposed is a method of extracting features from the tip fluorescence signal which were used to distinguishing between straight vs. turning growth behavior. The tip signal was obtained as a ratio of the average membrane-to-cytoplasm fluorescence values over time. A two-stage scheme was used to automatically detect individual growth intervals/cycles from the tip signal and split the experimental video into growth segments. In each growth segment, relevant features were extracted. An initial classification used structure-based features to distinguish between straight vs. turning growth cycles. The signal-based features were then used to train a Naive Bayes classifier to refine the misclassifications of the initial classification.
Proposed is a method of extracting features from the tip fluorescence signal which were used to distinguishing between straight vs. turning growth behavior. The tip signal was obtained as a ratio of the average membrane-to-cytoplasm fluorescence values over time. A two-stage scheme was used to automatically detect individual growth intervals/cycles from the tip signal and split the experimental video into growth segments. In each growth segment, relevant features were extracted. An initial classification used structure-based features to distinguish between straight vs. turning growth cycles. The signal-based features were then used to train a Naive Bayes classifier to refine the misclassifications of the initial classification.
Modeling and classifying tip dynamics of growing cells in video
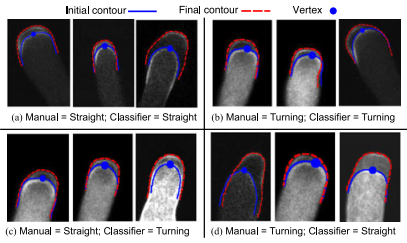 Plant biologists study pollen tubes to discover the functions of many proteins/ions and map the complex network of pathways that lead to an observable growth behavior. Many growth models have been proposed that addressed parts of the growth process: internal dynamics and cell wall dynamics, but they did not distinguish between the two types of growth segments: straight versus turning behavior. We proposed a method of classifying segments of experimental videos by extracting features from the growth process during each interval. We used a stress–strain relationship to measure the extensibility in the tip region. A biologically relevant three-component Gaussian was used to model spatial distribution of tip extensibility and a second-order damping system was used to explain the temporal dynamics. Feature-based classification showed that the location of maximum tip extensibility was the most distinguishing feature between straight versus turning behavior
Plant biologists study pollen tubes to discover the functions of many proteins/ions and map the complex network of pathways that lead to an observable growth behavior. Many growth models have been proposed that addressed parts of the growth process: internal dynamics and cell wall dynamics, but they did not distinguish between the two types of growth segments: straight versus turning behavior. We proposed a method of classifying segments of experimental videos by extracting features from the growth process during each interval. We used a stress–strain relationship to measure the extensibility in the tip region. A biologically relevant three-component Gaussian was used to model spatial distribution of tip extensibility and a second-order damping system was used to explain the temporal dynamics. Feature-based classification showed that the location of maximum tip extensibility was the most distinguishing feature between straight versus turning behavior
Spatio-temporal pattern recognition of dendritic spines and protein dynamics using live multichannel fluorescence microscopy
 Actin-regulating proteins, such as cofilin, are
essential in regulating the shape of dendritic spines, and
synaptic plasticity in both neuronal functionality as well as in
neurodegeneration related to aging. Presented is a novel automated pattern recognition system to
analyze protein trafficking in neurons. Using spatio-temporal
information present in multichannel fluorescence videos, the
system generates a temporal maximum intensity projection that
enhances the signal-to-noise ratio of important biological
structures, segments and tracks dendritic spines, and quantifies
the flux and density of proteins in spines. The temporal
dynamics of spines is used to generate spine energy images
which are used to automatically classify the shape of dendritic
spines as stubby, mushroom, or thin. By tracking these spines
over time and using their intensity profiles, the system is able to
analyze the flux patterns of cofilin and other fluorescently
stained proteins.
Actin-regulating proteins, such as cofilin, are
essential in regulating the shape of dendritic spines, and
synaptic plasticity in both neuronal functionality as well as in
neurodegeneration related to aging. Presented is a novel automated pattern recognition system to
analyze protein trafficking in neurons. Using spatio-temporal
information present in multichannel fluorescence videos, the
system generates a temporal maximum intensity projection that
enhances the signal-to-noise ratio of important biological
structures, segments and tracks dendritic spines, and quantifies
the flux and density of proteins in spines. The temporal
dynamics of spines is used to generate spine energy images
which are used to automatically classify the shape of dendritic
spines as stubby, mushroom, or thin. By tracking these spines
over time and using their intensity profiles, the system is able to
analyze the flux patterns of cofilin and other fluorescently
stained proteins.
Dynamic Bi-modal fusion of images for segmentation of pollen tubes in video
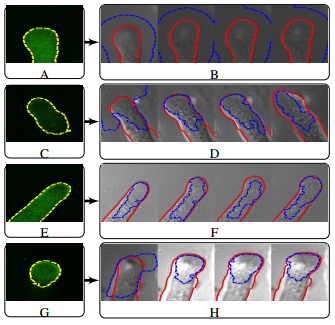 Biologists studied pollen tube growth to understand how internal cell dynamics affected observable structural characteristics like cell diameter, length, and growth rate. Fluorescence microscopy was used to study the dynamics of internal proteins and ions, but this often produced images with missing parts of the pollen tube. Brightfield microscopy provided a low-cost way of obtaining structural information about the pollen tube, but the images were crowded with false edges. We proposed a dynamic segmentation fusion scheme that used both Bright-Field and Fluorescence images of growing pollen tubes to get a unified segmentation. Knowledge of the image formation process was used to create an initial estimate of the location of the cell boundary. Fusing this estimate with an edge indicator function amplified desired edges and attenuated undesired edges. The cell boundary was obtained using Level Set evolution on the fused edge indicator function.
Biologists studied pollen tube growth to understand how internal cell dynamics affected observable structural characteristics like cell diameter, length, and growth rate. Fluorescence microscopy was used to study the dynamics of internal proteins and ions, but this often produced images with missing parts of the pollen tube. Brightfield microscopy provided a low-cost way of obtaining structural information about the pollen tube, but the images were crowded with false edges. We proposed a dynamic segmentation fusion scheme that used both Bright-Field and Fluorescence images of growing pollen tubes to get a unified segmentation. Knowledge of the image formation process was used to create an initial estimate of the location of the cell boundary. Fusing this estimate with an edge indicator function amplified desired edges and attenuated undesired edges. The cell boundary was obtained using Level Set evolution on the fused edge indicator function.
Distributed multi-robot search in the real-world using modified particle swarm optimization
.png) A challenging issue in multi-robot system is to design effective algorithms which enable robots to collaborate with one another in order to search and find objects of interest. Unlike most of the research on PSO (particle swarm optimization) that adopts the method to a virtual multi-agent system, in this paper, we present a framework to use a modified PSO (MPSO) algorithm in a multi-robot system for search task in real-world environments. We modify the algorithm to optimize the total path traveled by robots. Experiments with multiple robots are provided.
A challenging issue in multi-robot system is to design effective algorithms which enable robots to collaborate with one another in order to search and find objects of interest. Unlike most of the research on PSO (particle swarm optimization) that adopts the method to a virtual multi-agent system, in this paper, we present a framework to use a modified PSO (MPSO) algorithm in a multi-robot system for search task in real-world environments. We modify the algorithm to optimize the total path traveled by robots. Experiments with multiple robots are provided.
Error model for scene reconstruction from motion and stereo
.png) Scene reconstruction from motion and stereo are the two most popular methods for 3D range reconstruction. Because both techniques are affected by different types of errors, combining these two approaches to carry out 3D reconstruction seems natural. In this work, we present the initial results of our work towards the goal of analytically describing the performance of such a synergistic system. We consider the case in which points are viewed from two vantage points, and analytically model the uncertainty in the reconstruction of their 3D position. The uncertainty is expressed as a function of the points’ location in the scene, as well as of the viewpoint change between the two images. The analysis is complemented by numerical results, which shed light on several interesting properties of the estimation accuracy.
Scene reconstruction from motion and stereo are the two most popular methods for 3D range reconstruction. Because both techniques are affected by different types of errors, combining these two approaches to carry out 3D reconstruction seems natural. In this work, we present the initial results of our work towards the goal of analytically describing the performance of such a synergistic system. We consider the case in which points are viewed from two vantage points, and analytically model the uncertainty in the reconstruction of their 3D position. The uncertainty is expressed as a function of the points’ location in the scene, as well as of the viewpoint change between the two images. The analysis is complemented by numerical results, which shed light on several interesting properties of the estimation accuracy.
Continuously Evolvable Bayesian Nets For Human Action Analysis in Videos
.png) This paper proposes a novel data driven continuously evolvable Bayesian Net (BN) framework to analyze human actions in video. In unpredictable video streams, only a few generic causal relations and their interrelations together with the dynamic changes of these interrelations are used to probabilistically estimate relatively complex human activities. Based on the available evidences in streaming videos, the proposed BN can dynamically change the number of nodes in every frame and different relations for the same nodes in different frames. The performance of the proposed BN framework is shown for complex movie clips where actions like hand on head or waist, standing close, and holding hands take place among multiple individuals under changing pose conditions. The proposed BN can represent and recognize the human activities in a scalable manner.
This paper proposes a novel data driven continuously evolvable Bayesian Net (BN) framework to analyze human actions in video. In unpredictable video streams, only a few generic causal relations and their interrelations together with the dynamic changes of these interrelations are used to probabilistically estimate relatively complex human activities. Based on the available evidences in streaming videos, the proposed BN can dynamically change the number of nodes in every frame and different relations for the same nodes in different frames. The performance of the proposed BN framework is shown for complex movie clips where actions like hand on head or waist, standing close, and holding hands take place among multiple individuals under changing pose conditions. The proposed BN can represent and recognize the human activities in a scalable manner.
Learning integrated perception-based speed control
.png) Advances in the area of autonomous mobile robotics have allowed robots to explore vast and often unknown terrains. This paper presents a particular form of autonomy that allows a robot to autonomously control its speed, based on perception, while traveling on unknown terrain. The robot is equipped with an onboard camera and a 3-axis accelerometer. The method begins by classifying a query image of the terrain immediately before the robot. Classification is based on the Gabor wavelet features. In learning the speed, a genetic algorithm is used to map the Gabor texture features to approximate speed that minimizes changes in accelerations along the three axes from their nominal values. Learning is performed continuously. Experiments are done in real time.
Advances in the area of autonomous mobile robotics have allowed robots to explore vast and often unknown terrains. This paper presents a particular form of autonomy that allows a robot to autonomously control its speed, based on perception, while traveling on unknown terrain. The robot is equipped with an onboard camera and a 3-axis accelerometer. The method begins by classifying a query image of the terrain immediately before the robot. Classification is based on the Gabor wavelet features. In learning the speed, a genetic algorithm is used to map the Gabor texture features to approximate speed that minimizes changes in accelerations along the three axes from their nominal values. Learning is performed continuously. Experiments are done in real time.
Real time robot learning
.png) This paper presents the design, implementation and testing of a real-time system using computer vision and machine learning techniques to demonstrate learning behavior in a miniature mobile robot. The miniature robot, through environmental sensing, learns to navigate a maze choosing the optimum route. Several reinforcement learning based algorithms, such as Q-Iearning, Q(A)-learning , fast online Q(A)-learning and DYNA structure, are considered. Experimental results based on simulation and an integrated real-time system are presented for varying density of obstacles in a 15xl5 maze.
This paper presents the design, implementation and testing of a real-time system using computer vision and machine learning techniques to demonstrate learning behavior in a miniature mobile robot. The miniature robot, through environmental sensing, learns to navigate a maze choosing the optimum route. Several reinforcement learning based algorithms, such as Q-Iearning, Q(A)-learning , fast online Q(A)-learning and DYNA structure, are considered. Experimental results based on simulation and an integrated real-time system are presented for varying density of obstacles in a 15xl5 maze.
Learning to perceive for autonomous navigation in outdoor environments
.png) In this paper we present a system that achieves robust performance by using local reinforcement learning to induce a highly adaptive mapping from input images to segmentation strategies for successful recognition. This is accomplished by using the confidence level of model matching as reinforcement to drive learning. Local reinforcement learning gives rises to better improvement in recognition performance. The system is verified through experiments on a large set of real images of traffic signs.
In this paper we present a system that achieves robust performance by using local reinforcement learning to induce a highly adaptive mapping from input images to segmentation strategies for successful recognition. This is accomplished by using the confidence level of model matching as reinforcement to drive learning. Local reinforcement learning gives rises to better improvement in recognition performance. The system is verified through experiments on a large set of real images of traffic signs.
A System for Obstacle Detection During Rotorcraft Low Altitude Flight
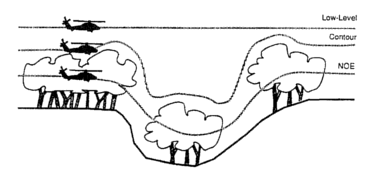 Automatic detection of obstacles (such as antennas, towers, poles, fences, tree branches, and wires strung across the flight path) and generation of appropriate guidance and control actions for the airborne vehicle to avoid these obstacles facilitated autonomous navigation. The requirements of an obstacle detection system for rotorcraft in low altitude Nap-of-the-Earth (NOE) flight based on various rotorcraft motion constraints is analyzed here in detail. An automated obstacle detection system for the rotorcraft scenario was expected to include both passive and active sensors to be effective and consequently, it introduced a maximally passive system which involved the use of an active (laser) sensor. The passive component was concerned with estimating range using optical flow-based motion analysis and binocular stereo. The optical flow-based motion analysis that was combined with an on-board inertial navigation system (INS) to compute ranges to visible scene points is described.
Automatic detection of obstacles (such as antennas, towers, poles, fences, tree branches, and wires strung across the flight path) and generation of appropriate guidance and control actions for the airborne vehicle to avoid these obstacles facilitated autonomous navigation. The requirements of an obstacle detection system for rotorcraft in low altitude Nap-of-the-Earth (NOE) flight based on various rotorcraft motion constraints is analyzed here in detail. An automated obstacle detection system for the rotorcraft scenario was expected to include both passive and active sensors to be effective and consequently, it introduced a maximally passive system which involved the use of an active (laser) sensor. The passive component was concerned with estimating range using optical flow-based motion analysis and binocular stereo. The optical flow-based motion analysis that was combined with an on-board inertial navigation system (INS) to compute ranges to visible scene points is described.
Synergism of Binocular and Motion Stereo for Passive Ranging
 Range measurements to objects in the world relative to mobile platform such as ground or air vehicles were critical for visually aided navigation and obstacle detection/avoidance. An approach is presented that consisted of a synergistic combination of two types of passive ranging methods: binocular stereo and motion stereo. We presented a way to model the errors in binocular and motion stereo in conjunction with an inertial navigation system (INS) and derive the appropriate Kalman filter to refine the estimates from these two stereo ranging techniques. By incorporating a blending filter, the approach had the potential of providing accurate, dense range measurements for all the pixels in the field of view (FOV).
Range measurements to objects in the world relative to mobile platform such as ground or air vehicles were critical for visually aided navigation and obstacle detection/avoidance. An approach is presented that consisted of a synergistic combination of two types of passive ranging methods: binocular stereo and motion stereo. We presented a way to model the errors in binocular and motion stereo in conjunction with an inertial navigation system (INS) and derive the appropriate Kalman filter to refine the estimates from these two stereo ranging techniques. By incorporating a blending filter, the approach had the potential of providing accurate, dense range measurements for all the pixels in the field of view (FOV).
A Geometric Constraint Method for Estimating 3-D Camera Motion
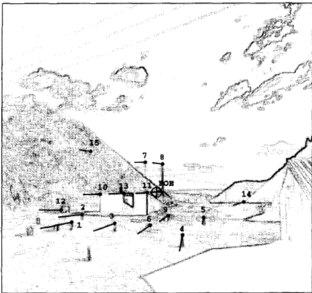 We investigated the problem of estimating the camera motion parameters from a 2D image sequence that had been obtained under combined 3D camera translation and rotation. Geometrical constraints in 2D were used to iteratively narrow down regions of possible values in the space of 3D motion parameters. The approach was based on a new concept called “FOE-feasibility” of an image region, for which an efficient algorithm had been implemented.
We investigated the problem of estimating the camera motion parameters from a 2D image sequence that had been obtained under combined 3D camera translation and rotation. Geometrical constraints in 2D were used to iteratively narrow down regions of possible values in the space of 3D motion parameters. The approach was based on a new concept called “FOE-feasibility” of an image region, for which an efficient algorithm had been implemented.
Robust Guidance of a Conventionally Steered Vehicle using Destination Bearing
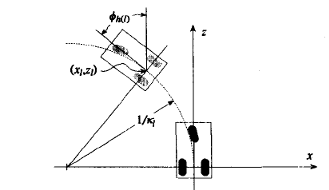 An algorithm for camera-based navigation of a conventionally steered vehicle is presented. The destination bearing, obtained by actively panning the camera to fixate on the destination, was the primary measurement. A steering sequence designed to direct a moving vehicle towards a visible destination was generated using an extension of predictive control techniques. A variable sampling interval, based on distance traveled instead of elapsed time, provided robustness to destination range errors. Additional robustness was achieved by incorporating non-linearities into the steering algorithm, ensuring that the moving vehicle originating from an awkward position and heading would not diverge from the destination. A two-stage extended Kalman filter, which used the destination bearing angle and known vehicle motion, provided estimates of range. A criterion for shifting the attention of the camera between intermediate destinations was presented and simulation results demonstrated the effectiveness of the proposed steering algorithm.
An algorithm for camera-based navigation of a conventionally steered vehicle is presented. The destination bearing, obtained by actively panning the camera to fixate on the destination, was the primary measurement. A steering sequence designed to direct a moving vehicle towards a visible destination was generated using an extension of predictive control techniques. A variable sampling interval, based on distance traveled instead of elapsed time, provided robustness to destination range errors. Additional robustness was achieved by incorporating non-linearities into the steering algorithm, ensuring that the moving vehicle originating from an awkward position and heading would not diverge from the destination. A two-stage extended Kalman filter, which used the destination bearing angle and known vehicle motion, provided estimates of range. A criterion for shifting the attention of the camera between intermediate destinations was presented and simulation results demonstrated the effectiveness of the proposed steering algorithm.
Inertial Navigation Sensor Integrated Motion Analysis for Autonomous Vehicle Navigation
 Many types of vehicles contained an inertial navigation system (INS) that could be utilized to greatly improve the performance of motion analysis techniques and make them useful for practical military and civilian applications. The results, obtained with a maximally passive system of obstacle detection for ground based vehicles and rotorcraft, are presented. Automatic detection of these obstacles and the necessary guidance and control actions triggered by such detection facilitated autonomous vehicle navigation. Our approach to obstacle detection employed motion analysis of imagery collected by a passive sensor during vehicle travel to generate range measurements to world points within the field of view of the sensor. The approach made use of INS data and scene analysis results to improve interest point selection, the matching of the interest points, and the subsequent motion-based range computations, tracking, and outdoor imagery.
Many types of vehicles contained an inertial navigation system (INS) that could be utilized to greatly improve the performance of motion analysis techniques and make them useful for practical military and civilian applications. The results, obtained with a maximally passive system of obstacle detection for ground based vehicles and rotorcraft, are presented. Automatic detection of these obstacles and the necessary guidance and control actions triggered by such detection facilitated autonomous vehicle navigation. Our approach to obstacle detection employed motion analysis of imagery collected by a passive sensor during vehicle travel to generate range measurements to world points within the field of view of the sensor. The approach made use of INS data and scene analysis results to improve interest point selection, the matching of the interest points, and the subsequent motion-based range computations, tracking, and outdoor imagery.
Dynamic Scene and Motion Analysis Using Passive Sensors Part II
 Several motion-understanding techniques using displacement fields, 3D motion and structures, and feature correspondence showed promise. But there were many issues to address and problems to solve before we achieved robust dynamic-scene and motion analysis.
Several motion-understanding techniques using displacement fields, 3D motion and structures, and feature correspondence showed promise. But there were many issues to address and problems to solve before we achieved robust dynamic-scene and motion analysis.
A System For Obstacle Detection During Rotorcraft Low-Altitude Flight
 Airborne vehicles such as rotorcraft had to (and still have to) avoid obstacles such as antennas, towers, poles, fences, tree branches, and wires strung across the flight path. Analyzed are the requirements of an obstacle detection system for rotorcrafts in low-altitude Nap-of-the-Earth flight based on various rotorcraft motion constraints. It argues that an automated obstacle detection system for the rotorcraft scenario should include both passive and active sensors. Consequently, it introduces a maximally passive system which involved the use of passive sensors (TV, FUR) as well as the selective use of an active (laser) sensor. The passive component was concerned with estimating range using optical flow-based motion analysis and binocular stereo in conjunction with inertial navigation system information.
Airborne vehicles such as rotorcraft had to (and still have to) avoid obstacles such as antennas, towers, poles, fences, tree branches, and wires strung across the flight path. Analyzed are the requirements of an obstacle detection system for rotorcrafts in low-altitude Nap-of-the-Earth flight based on various rotorcraft motion constraints. It argues that an automated obstacle detection system for the rotorcraft scenario should include both passive and active sensors. Consequently, it introduces a maximally passive system which involved the use of passive sensors (TV, FUR) as well as the selective use of an active (laser) sensor. The passive component was concerned with estimating range using optical flow-based motion analysis and binocular stereo in conjunction with inertial navigation system information.
Integrated Binocular and Motion Stereo in an Inertial Navigation Sensor-Based Mobile Vehicle
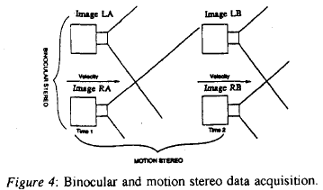 Range measurements to objects in the world relative to mobile platforms such as ground or air vehicles were critical for visually aided navigation and obstacle detection/avoidance. An approach that consisted of a synergistic combination of two types of passive ranging methods, binocular stereo and motion stereo, is presented. We showed a new way to model the errors in binocular and motion stereo in conjunction with an inertial navigation system and derived the appropriate Kalman filter to refine the estimates from these two stereo ranging techniques. We present results using laboratory images that show that refined estimates could be optimally combined to give range values which were more accurate than any one of the individual estimates from binocular and motion stereo. By incorporating a blending filter, the approach had the potential of providing accurate, dense range measurements for all the pixels in the field of view.
Range measurements to objects in the world relative to mobile platforms such as ground or air vehicles were critical for visually aided navigation and obstacle detection/avoidance. An approach that consisted of a synergistic combination of two types of passive ranging methods, binocular stereo and motion stereo, is presented. We showed a new way to model the errors in binocular and motion stereo in conjunction with an inertial navigation system and derived the appropriate Kalman filter to refine the estimates from these two stereo ranging techniques. We present results using laboratory images that show that refined estimates could be optimally combined to give range values which were more accurate than any one of the individual estimates from binocular and motion stereo. By incorporating a blending filter, the approach had the potential of providing accurate, dense range measurements for all the pixels in the field of view.
A Qualitative Approach to Dynamic Scene Understanding
 The goal of “dynamic scene understanding” was to find consistent explanations for all changes in the image in terms of three-dimensional camera motion, individual object motion, and static scene structure. Extended from the original Focus-of-Expansion concept to the so-called Fuzzy FOE, where a singular point in the image was not computed, but a connected image region that marked the approximate direction of heading. A rule-based reasoning engine analyzed the resulting “derotated” displacement field for certain events and incrementally built a three-dimensional Qualitative Scene Model. This model comprised of a collection of scene hypotheses, each representing a feasible and distinct interpretation of the current scene.
The goal of “dynamic scene understanding” was to find consistent explanations for all changes in the image in terms of three-dimensional camera motion, individual object motion, and static scene structure. Extended from the original Focus-of-Expansion concept to the so-called Fuzzy FOE, where a singular point in the image was not computed, but a connected image region that marked the approximate direction of heading. A rule-based reasoning engine analyzed the resulting “derotated” displacement field for certain events and incrementally built a three-dimensional Qualitative Scene Model. This model comprised of a collection of scene hypotheses, each representing a feasible and distinct interpretation of the current scene.
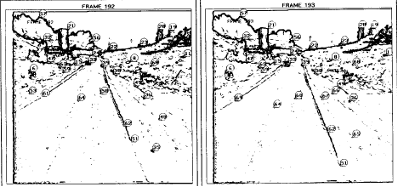
Qualitative Understanding of Scene Dynamics for Mobile Robots
 An approach to analyzing motion sequences as they were observed from a mobile robot that operated in a dynamic environment is presented. In particular, the problems of estimating the robot’s egomotion, reconstructing the 3D scene structure, and evaluating the motion of individual objects from a sequence of monocular images. This problem was approached by a two-stage process starting from given sets of displacement vectors between distinct image features in successive frames. The robot’s egomotion was computed in terms of rotations and the direction of translation. In order to cope with the problems of noise, we extended the concept of the Focus of Expansion (FOE) by computing a Fuzzy FOE, which defined an image region rather than a single point. In the second stage, a 3D scene model was constructed by analyzing the movements and positions of image features relative to each other and relative to the Fuzzy FOE. Using a mainly qualitative strategy of reasoning and modeling, multiple scene interpretations were pursued simultaneously. This second stage allowed the determination of moving objects in the scene.
An approach to analyzing motion sequences as they were observed from a mobile robot that operated in a dynamic environment is presented. In particular, the problems of estimating the robot’s egomotion, reconstructing the 3D scene structure, and evaluating the motion of individual objects from a sequence of monocular images. This problem was approached by a two-stage process starting from given sets of displacement vectors between distinct image features in successive frames. The robot’s egomotion was computed in terms of rotations and the direction of translation. In order to cope with the problems of noise, we extended the concept of the Focus of Expansion (FOE) by computing a Fuzzy FOE, which defined an image region rather than a single point. In the second stage, a 3D scene model was constructed by analyzing the movements and positions of image features relative to each other and relative to the Fuzzy FOE. Using a mainly qualitative strategy of reasoning and modeling, multiple scene interpretations were pursued simultaneously. This second stage allowed the determination of moving objects in the scene.
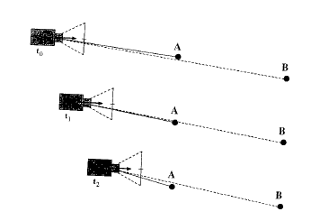
Estimating 3-D Egomotion from Perspective Image Sequences
 The problem of the computation of sensor motion from sets of displacement vectors obtained from consecutive pairs of images was investigated with emphasis on its application to autonomous robots and land vehicles. First, the effects of 3-D camera rotation and translation upon the observed image were discussed and in particular the concept of the focus of expansion (FOE). It was shown that locating the FOE precisely was difficult when displacement vectors were corrupted by noise and errors. A more robust performance could be achieved by computing a 2-D region of possible FOE-locations (termed the fuzzy FOE) instead of looking for a single-point FOE. The shape of this FOE-region was an explicit indicator for the accuracy of the result. It was shown elsewhere that given the fuzzy FOE, a number of powerful inferences about the 3-D scene structure and motion were possible.
The problem of the computation of sensor motion from sets of displacement vectors obtained from consecutive pairs of images was investigated with emphasis on its application to autonomous robots and land vehicles. First, the effects of 3-D camera rotation and translation upon the observed image were discussed and in particular the concept of the focus of expansion (FOE). It was shown that locating the FOE precisely was difficult when displacement vectors were corrupted by noise and errors. A more robust performance could be achieved by computing a 2-D region of possible FOE-locations (termed the fuzzy FOE) instead of looking for a single-point FOE. The shape of this FOE-region was an explicit indicator for the accuracy of the result. It was shown elsewhere that given the fuzzy FOE, a number of powerful inferences about the 3-D scene structure and motion were possible.
Internal Navigation Sensor Integrated Motion Analysis for Obstacle Detection
 Land navigation required (and still requires) a vehicle to steer clear of trees, rocks, and man-made obstacles in the vehicle's path while vehicles in flight, such as helicopters, must avoid antennas, towers, poles, fences, tree branches, and wires strung across the flight path. Automatic detection of these obstacles and the necessary guidance and control actions triggered by such detection would facilitate autonomous vehicle navigation. An approach employing a passive sensor for mobility and navigation was generally preferred in practical applications of these robotic vehicles. Motion analysis of imagery obtained during vehicle travel could be used to generate range measurements, but these techniques were not robust and reliable enough to handle arbitrary image motion caused by vehicle movement. However, many types of vehicles contained inertial navigation systems (INS) which could be utilized to improve interest point selection, matching of the interest points, and the subsequent motion detection, tracking, and obstacle detection. We discuss an inertial sensor integrated optical flow technique for motion analysis that achieved increased effectiveness in obstacle detection during vehicle motion.
Land navigation required (and still requires) a vehicle to steer clear of trees, rocks, and man-made obstacles in the vehicle's path while vehicles in flight, such as helicopters, must avoid antennas, towers, poles, fences, tree branches, and wires strung across the flight path. Automatic detection of these obstacles and the necessary guidance and control actions triggered by such detection would facilitate autonomous vehicle navigation. An approach employing a passive sensor for mobility and navigation was generally preferred in practical applications of these robotic vehicles. Motion analysis of imagery obtained during vehicle travel could be used to generate range measurements, but these techniques were not robust and reliable enough to handle arbitrary image motion caused by vehicle movement. However, many types of vehicles contained inertial navigation systems (INS) which could be utilized to improve interest point selection, matching of the interest points, and the subsequent motion detection, tracking, and obstacle detection. We discuss an inertial sensor integrated optical flow technique for motion analysis that achieved increased effectiveness in obstacle detection during vehicle motion.
Computing a ’Fuzzy’ Focus of Expansion for Autonomous Navigation
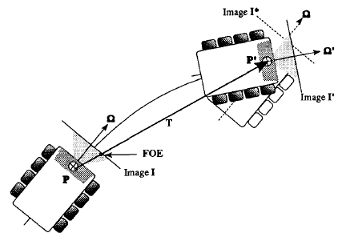 The Focus of Expansion (FOE) was an important concept in dynamic scene analysis, particularly where translational motion was dominant, such as in mobile robot applications. In practice, it was difficult to determine the exact location of the FOE from a given set of displacement vectors due to the effects of camera rotation, digitization, and noise. Instead of a single image location, we proposed to compute a connected region, termed ‘Fuzzy’ FOE, that marked the approximate direction of camera heading. The ‘Fuzzy’ FOE provided numerous clues about the 3D scene structure and independent object motion. We discuss the main problems of the classic FOE approach and concentrate on the details of computing the ‘Fuzzy’ FOE for a camera undergoing translation and rotation in 3D space.
The Focus of Expansion (FOE) was an important concept in dynamic scene analysis, particularly where translational motion was dominant, such as in mobile robot applications. In practice, it was difficult to determine the exact location of the FOE from a given set of displacement vectors due to the effects of camera rotation, digitization, and noise. Instead of a single image location, we proposed to compute a connected region, termed ‘Fuzzy’ FOE, that marked the approximate direction of camera heading. The ‘Fuzzy’ FOE provided numerous clues about the 3D scene structure and independent object motion. We discuss the main problems of the classic FOE approach and concentrate on the details of computing the ‘Fuzzy’ FOE for a camera undergoing translation and rotation in 3D space.
Approximation of Displacement Fields Using Wavefront Region Growing
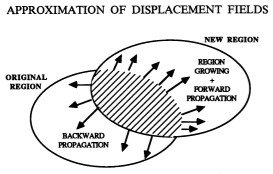 An approach for the computation of displacement fields along contours which corresponded to moving homogenous regions in an image sequence is presented. Individual frames of the image sequence were treated one at a time by performing segmentation and 2D motion analysis simultaneously. For the first frame, an original segmentation of the image into disjoint regions was assumed to be given in the form of pixel markings and the properties of these regions. The analysis of each new frame consisted of (a) finding the new segmentation and (b) a set of displacement vectors that linked corresponding points on the original and the new contour. The new region was assumed to overlap with the original region, such that their intersection was not empty. After finding the intersection, wavefront region growing was applied to obtain the new region and to compute a set of tentative displacement vectors. The final approximation was found by using a relaxation-type algorithm which “rotated” the mapping between the original and the new boundary until a correspondence with minimum deformation was found. The proposed algorithm was simple and lends itself to parallel implementation.
An approach for the computation of displacement fields along contours which corresponded to moving homogenous regions in an image sequence is presented. Individual frames of the image sequence were treated one at a time by performing segmentation and 2D motion analysis simultaneously. For the first frame, an original segmentation of the image into disjoint regions was assumed to be given in the form of pixel markings and the properties of these regions. The analysis of each new frame consisted of (a) finding the new segmentation and (b) a set of displacement vectors that linked corresponding points on the original and the new contour. The new region was assumed to overlap with the original region, such that their intersection was not empty. After finding the intersection, wavefront region growing was applied to obtain the new region and to compute a set of tentative displacement vectors. The final approximation was found by using a relaxation-type algorithm which “rotated” the mapping between the original and the new boundary until a correspondence with minimum deformation was found. The proposed algorithm was simple and lends itself to parallel implementation.
Landmark Recognition for Autonomous Mobile Robots
 An approach for landmark recognition based on the perception, reasoning, action, and expectation (PREACTE) paradigm is presented for the navigation of autonomous mobile robots. PREACTE used expectations to predict the appearance and disappearance of objects, thereby reducing computational complexity and locational uncertainty. It used an innovative concept called dynamic model matching (DMM), which was based on the automatic generation of landmark description at different ranges and aspect angles and used explicit knowledge about maps and landmarks. Map information was used to generate an expected site model (ESM) for search delimitation, given the location and velocity of the mobile robot. The landmark recognition vision system generated 2-D and 3-D scene models from the observed scene.
An approach for landmark recognition based on the perception, reasoning, action, and expectation (PREACTE) paradigm is presented for the navigation of autonomous mobile robots. PREACTE used expectations to predict the appearance and disappearance of objects, thereby reducing computational complexity and locational uncertainty. It used an innovative concept called dynamic model matching (DMM), which was based on the automatic generation of landmark description at different ranges and aspect angles and used explicit knowledge about maps and landmarks. Map information was used to generate an expected site model (ESM) for search delimitation, given the location and velocity of the mobile robot. The landmark recognition vision system generated 2-D and 3-D scene models from the observed scene.
Dynamic Scene Understanding for Autonomous Mobile Robots
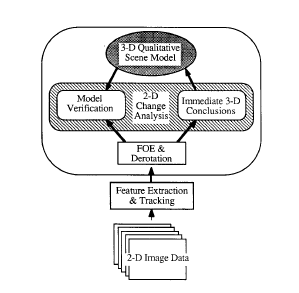 An approach to the dynamic scene analysis is presented which departed from previous work by emphasizing a qualitative strategy of reasoning and modeling. Instead of refining a single quantitative description of the observed environment over time, multiple qualitative interpretations were maintained simultaneously. This offered superior robustness and flexibility over traditional numerical techniques which were often ill-conditioned and noise sensitive. The main tasks of our approach were (a) to detect and to classify the motion of individual objects in the scene, (b) to estimate the robot's egomotion, and (c) to derive the 3-D structure of the stationary environment. These three tasks strongly depended on each other. First, the direction of heading (i.e. translation) and rotation of the robot were estimated with respect to stationary locations in the scene. The focus of expansion (FOE) was not determined as particular image location, but as a region of possible FOE-locations called the Fuzzy FOE. From this information, a rule-based system constructed and maintained a Qualitative Scene Model.
An approach to the dynamic scene analysis is presented which departed from previous work by emphasizing a qualitative strategy of reasoning and modeling. Instead of refining a single quantitative description of the observed environment over time, multiple qualitative interpretations were maintained simultaneously. This offered superior robustness and flexibility over traditional numerical techniques which were often ill-conditioned and noise sensitive. The main tasks of our approach were (a) to detect and to classify the motion of individual objects in the scene, (b) to estimate the robot's egomotion, and (c) to derive the 3-D structure of the stationary environment. These three tasks strongly depended on each other. First, the direction of heading (i.e. translation) and rotation of the robot were estimated with respect to stationary locations in the scene. The focus of expansion (FOE) was not determined as particular image location, but as a region of possible FOE-locations called the Fuzzy FOE. From this information, a rule-based system constructed and maintained a Qualitative Scene Model.
Estimation of Image Motion Using Wavefront Region Growing
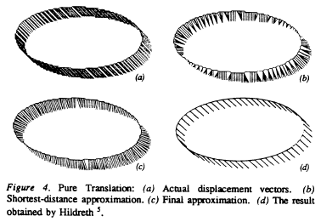 An approach for the computation of displacement fields along contours of moving regions, where distinct point features were difficult to maintain and the proposed algorithm was simple and lent itself to parallel implementation is presented. Individual frames of the image sequence were treated one at a time, and the segmentation and motion analysis were performed simultaneously. For the first frame an original segmentation of the image into disjoint regions was assumed to be given in the form of pixel markings and the properties of these regions. The analysis of each new frame consisted of finding the new segmentation and a set of displacement vectors that linked corresponding points on the original and new contour, while the new region was assumed to overlap with the original region. A relaxation-type algorithm was then used to determine the shortest links between subsequent boundaries to approximate the displacement field. Experiments on synthetic images showed that results compared favorably with work done by Hildreth, yet followed a simpler and more realistic approach.
An approach for the computation of displacement fields along contours of moving regions, where distinct point features were difficult to maintain and the proposed algorithm was simple and lent itself to parallel implementation is presented. Individual frames of the image sequence were treated one at a time, and the segmentation and motion analysis were performed simultaneously. For the first frame an original segmentation of the image into disjoint regions was assumed to be given in the form of pixel markings and the properties of these regions. The analysis of each new frame consisted of finding the new segmentation and a set of displacement vectors that linked corresponding points on the original and new contour, while the new region was assumed to overlap with the original region. A relaxation-type algorithm was then used to determine the shortest links between subsequent boundaries to approximate the displacement field. Experiments on synthetic images showed that results compared favorably with work done by Hildreth, yet followed a simpler and more realistic approach.
Knowledge-Based Analysis of Scene Dynamics for an Autonomous Land Vehicle
 In the Honeywell Strategic Computing Computer Vision Program, we were developing knowledge-based technology applied to Autonomous Land Vehicles. The focus of our work had been to use artificial intelligence techniques in computer vision, spatial and temporal reasoning and incorporation of a priori, and contextual and multisensory information for dynamic scene understanding. The topics under investigation were: Landmark and target recognition using multi-source a priori information, robust target motion detection and tracking using qualitative reasoning, and interpretation of terrain using symbolic grouping. We developed a new approach, called PREACTE (Perception-REasoning-ACTion and Expectation) for knowledge-based landmark recognition for the purpose of guiding ALVs that was based on the perception-reasoning-action and expectation paradigm of an intelligent agent and used dynamic model matching. For motion understanding we have developed a new approach called DRIVE (Dynamic Reasoning from Integrated Visual Evidence) based on a Qualitative Scene Model which addressed the key problems of the estimation of vehicle motion from visual cues, the detection and tracking of moving objects, and the construction and maintenance of a global dynamic reference model. Our approach to terrain interpretation employed a hierarchical region labeling algorithm for multi-spectral scanner data called HSGM (Hierarchical Symbolic Grouping from Multi-spectral data). Our results were useful in vision controlled navigation/guidance of an autonomous land vehicle, search and rescue, munitions deployment, and other military applications.
In the Honeywell Strategic Computing Computer Vision Program, we were developing knowledge-based technology applied to Autonomous Land Vehicles. The focus of our work had been to use artificial intelligence techniques in computer vision, spatial and temporal reasoning and incorporation of a priori, and contextual and multisensory information for dynamic scene understanding. The topics under investigation were: Landmark and target recognition using multi-source a priori information, robust target motion detection and tracking using qualitative reasoning, and interpretation of terrain using symbolic grouping. We developed a new approach, called PREACTE (Perception-REasoning-ACTion and Expectation) for knowledge-based landmark recognition for the purpose of guiding ALVs that was based on the perception-reasoning-action and expectation paradigm of an intelligent agent and used dynamic model matching. For motion understanding we have developed a new approach called DRIVE (Dynamic Reasoning from Integrated Visual Evidence) based on a Qualitative Scene Model which addressed the key problems of the estimation of vehicle motion from visual cues, the detection and tracking of moving objects, and the construction and maintenance of a global dynamic reference model. Our approach to terrain interpretation employed a hierarchical region labeling algorithm for multi-spectral scanner data called HSGM (Hierarchical Symbolic Grouping from Multi-spectral data). Our results were useful in vision controlled navigation/guidance of an autonomous land vehicle, search and rescue, munitions deployment, and other military applications.
Landmark Recognition for Autonomous Land Vehicle Navigation
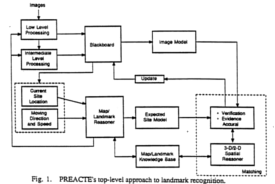 In the Autonomous Land Vehicle (ALV) application scenario, a significant amount of positional error was accumulated in the land navigation system after traversing long distances. Landmark recognition could be used to update the land navigation system by recognizing the observed objects in the scene and associating them with the specific landmarks in the geographic map knowledge-base. A landmark recognition technique based on a perception-reasoning-action and expectation paradigm of an intelligent agent that used extensive map and domain dependent knowledge in a model-based approach is presented. It performed spatial reasoning by using N-ary relations in combination with negative and positive evidences. Since it could predict the appearance and disappearance of objects, it reduced the computational complexity and uncertainty in labeling objects and provided a flexible and modular computational framework for abstracting image information and modelling objects in heterogeneous representations.
In the Autonomous Land Vehicle (ALV) application scenario, a significant amount of positional error was accumulated in the land navigation system after traversing long distances. Landmark recognition could be used to update the land navigation system by recognizing the observed objects in the scene and associating them with the specific landmarks in the geographic map knowledge-base. A landmark recognition technique based on a perception-reasoning-action and expectation paradigm of an intelligent agent that used extensive map and domain dependent knowledge in a model-based approach is presented. It performed spatial reasoning by using N-ary relations in combination with negative and positive evidences. Since it could predict the appearance and disappearance of objects, it reduced the computational complexity and uncertainty in labeling objects and provided a flexible and modular computational framework for abstracting image information and modelling objects in heterogeneous representations.
Qualitative Motion Understanding
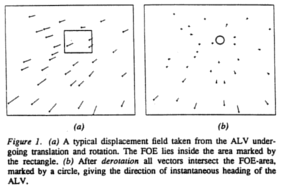 The vision system of an Autonomous Land Vehicle was required to handle complex dynamic scenes. Vehicle motion and individually moving objects in the field of view contributed to a continuously changing camera image. It was the purpose of motion understanding to find consistent three-dimensional interpretations for these changes in the image sequence. We present an approach to this problem, which departed from previous work by emphasizing a qualitative nature of reasoning and modeling and maintaining multiple interpretations of the scene at the same time. This approach offered advantages such as robustness and flexibility over “hard” numerical techniques which had been proposed in the motion understanding literature.
The vision system of an Autonomous Land Vehicle was required to handle complex dynamic scenes. Vehicle motion and individually moving objects in the field of view contributed to a continuously changing camera image. It was the purpose of motion understanding to find consistent three-dimensional interpretations for these changes in the image sequence. We present an approach to this problem, which departed from previous work by emphasizing a qualitative nature of reasoning and modeling and maintaining multiple interpretations of the scene at the same time. This approach offered advantages such as robustness and flexibility over “hard” numerical techniques which had been proposed in the motion understanding literature.
|
|



 The drive system used a qualitative scene model and a Fuzzy Focus Of Expansion to estimate robot motion from visual cues, detect and track moving objects, and construct and maintain a global dynamic reference.
The drive system used a qualitative scene model and a Fuzzy Focus Of Expansion to estimate robot motion from visual cues, detect and track moving objects, and construct and maintain a global dynamic reference.